




RetrievalAugmentation表示检索增强
Spring AI(7)——RAG_springai rag-优快云博客 中介绍了RAG的基本使用,但是其中的QuestionAnswerAdvisor 主要作用是对向量数据库中的所有文档执行相似性搜索。
RetrievalAugmentationAdvisor可以更好的体现检索增强。
基本用法
导入jar
帮助文档中提到“要使用 QuestionAnswerAdvisor 或 RetrievalAugmentationAdvisor,需添加 spring-ai-advisors-vector-store”,但是实际测试发现,如果使用RetrievalAugmentationAdvisor,还需要导入如下的jar:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>yml
其中的主要配置和之前博客中的配置基本一致
spring:
ai:
zhipuai:
api-key: 自己申请的key
chat:
options:
# model: glm-4v-flash
model: glm-4-flash
temperature: 0.7
ollama:
base-url: http://localhost:11434
embedding:
options:
model: shaw/dmeta-embedding-zh:latest
model:
embedding: ollama
vectorstore:
milvus:
client:
host: "localhost"
port: 19530
databaseName: "myai"
collectionName: "vector_2501"
embeddingDimension: 768
indexType: IVF_FLAT
metricType: COSINE测试代码
package com.renr.springainew.controller;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.chat.client.advisor.vectorstore.QuestionAnswerAdvisor;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.template.st.StTemplateRenderer;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.milvus.MilvusVectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
/**
* @Classname RagController
* @Description TODO
* @Date 2025-05-15 11:15
* @Created by 老任与码
*/
@RestController
@RequestMapping("/rag")
public class RagController {
@Resource
private ChatClient client;
@Resource
private EmbeddingModel embeddingModel;
@Value("classpath:document/医院.txt")
private org.springframework.core.io.Resource resource;
@Resource
// private VectorStore vectorStore;
private MilvusVectorStore milvusVectorStore;
// 执行一次即可
// @PostConstruct
public void init() {
// 读取文本文件
TextReader textReader = new TextReader(this.resource);
// 元数据中增加文件名
textReader.getCustomMetadata().put("filename", "医院.txt");
// 获取Document对象,只有一个记录
List<Document> docList = textReader.read();
TokenTextSplitter splitter = new TokenTextSplitter(300, 350, 5, 10000, true);
List<Document> splitDocuments = splitter.apply(docList);
milvusVectorStore.add(splitDocuments);
}
@GetMapping("/chat2")
public String chat2(String message) {
// 创建RetrievalAugmentationAdvisor对象
// 通过documentRetriever指定使用的向量数据库
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.topK(3)
.vectorStore(milvusVectorStore)
.build())
.build();
String answer = client.prompt()
// 设置检索增强对象
.advisors(retrievalAugmentationAdvisor)
.user(message)
.call()
.content();
System.out.println(answer);
return "success";
}
}
VectorStoreDocumentRetriever 从向量数据库检索与输入查询语义相似的文档,支持基于元数据过滤、相似度阈值和 top-k 结果数量控制。
测试结果
提问内容是“医院职工数”,根据日志,可以看到对应的提示词的模版如下:
'Context information is below.
---------------------
70%,获批省级特色专科、省级专病治疗中心。
心脏大血管外科入选河南省“十四五”首批省级临床重点专科,开展冠脉搭桥手术、经导管主动脉瓣置换术(TAVI手术)、HYBRID心脏杂交手术。血管外科是河南省医学会、医师协会副主委单位,完成主动脉夹层(瘤)介入技术、颈动脉体瘤切除、颈动脉内膜剥脱、一站式治疗VTE。
整形修复科是中国创面修复建设培育单位,入选河南省“十四五”首批省级临床重点专科,开展耳、鼻、口唇、颌面、手足、乳房、腹壁、生殖器、瘢痕、体表肿瘤
河南省直第三人民医院简介
(修订日期 2025年3月)
河南省直第三人民医院是河南省卫健委直属的一家“医教研转工作统筹推进、防治康养手段综合应用、吃动睡想行为全面科学”的省三级公立综合医院。是河南省干部保健定点医院。
医院位于河南省省会郑州,有三个院区,郑东院区(郑东新区人民医院)比邻河南省政府。西院区位于中原区伏牛路陇海路交叉口;857院区位于中原区陇海路328号。医院有2个急救站,5个急救联盟单位、4个社区卫生服务中心;下设司法鉴定中心。
医院核定床位1800张,职工2113人,专业技术人员1903人,二级主任医�
化,汲取“智慧管理、人文管理、高科技创新、低成本高效运营”的现代化综合性医院之精髓,为患者提供安全、优质、便捷的医疗服务。
---------------------
Given the context information and no prior knowledge, answer the query.
Follow these rules:
1. If the answer is not in the context, just say that you don't know.
2. Avoid statements like "Based on the context..." or "The provided information...".
Query: 医院职工数
Answer:
'回答如下,而且回答结果正确
我们再次给出如下提问:
提出的问题是“你好”,请求日志中提示“query is outside your knowledge base.
Politely inform the user that you can't answer it.”,说明没有从向量数据库中检索到对应的数据。
request: ChatClientRequest[prompt=Prompt{messages=[SystemMessage{textContent='你是一个java架构师', messageType=SYSTEM, metadata={messageType=SYSTEM}}, UserMessage{content='The user query is outside your knowledge base.
Politely inform the user that you can't answer it.
', properties={messageType=USER}, messageType=USER}], modelOptions=org.springframework.ai.zhipuai.ZhiPuAiChatOptions@dde07018}, context={rag_document_context=[]}]回答的内容如下:“I'm sorry, but I don't have the information to answer that question. Please feel free to ask another question or provide more context, and I'll do my best to assist you.”
默认情况下,RetrievalAugmentationAdvisor 不允许检索到的上下文为空。此时它会指示模型不回答用户查询。
ContextualQueryAugmenter
上文我们提到,RetrievalAugmentationAdvisor 不允许检索到的上下文为空。如果解决该问题可以使用ContextualQueryAugmenter,利用所提供文档的内容上下文数据增强用户查询。
修改上述代码如下:
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.topK(3)
.vectorStore(milvusVectorStore)
.build())
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(true)
.build())
.build();通过queryAugmenter()指定ContextualQueryAugmenter对象,在该对象中设置allowEmptyContext(true),再次提问:
回答内容如下:

另外,查询时,默认的提示词模版信息是英文的,那么如何指定我们的自定义提示词模版呢?
只需要设置ContextualQueryAugmenter的queryTemplate属性即可。
修改代码如下:
@GetMapping("/chat2")
public String chat2(String message) {
// 定义提示词模版
PromptTemplate customPromptTemplate = PromptTemplate.builder()
.renderer(StTemplateRenderer.builder().startDelimiterToken('<').endDelimiterToken('>').build())
.template("""
<query>
上下文信息如下:
---------------------
<context>
---------------------
根据上下文信息回答查询。
遵循以下规则:
1. 如果答案不在上下文中,只需说你不知道。
2. 避免使用“根据上下文...”或“提供的信息...”这样的表述。
3. 回答问题尽量精简
""")
.build();
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.topK(3)
.vectorStore(milvusVectorStore)
.build())
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(true)
.promptTemplate(customPromptTemplate)
.build())
.build();
String answer = client.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(message)
.call()
.content();
System.out.println(answer);
return "success";
}其中自定了提示词模版对象PromptTemplate,通过.promptTemplate(customPromptTemplate)指定了模版对象。修改代码后,再次提问:
根据模版生成的提示词如下:
'医院职工数
上下文信息如下:
---------------------
70%,获批省级特色专科、省级专病治疗中心。
心脏大血管外科入选河南省“十四五”首批省级临床重点专科,开展冠脉搭桥手术、经导管主动脉瓣置换术(TAVI手术)、HYBRID心脏杂交手术。血管外科是河南省医学会、医师协会副主委单位,完成主动脉夹层(瘤)介入技术、颈动脉体瘤切除、颈动脉内膜剥脱、一站式治疗VTE。
整形修复科是中国创面修复建设培育单位,入选河南省“十四五”首批省级临床重点专科,开展耳、鼻、口唇、颌面、手足、乳房、腹壁、生殖器、瘢痕、体表肿瘤
河南省直第三人民医院简介
(修订日期 2025年3月)
河南省直第三人民医院是河南省卫健委直属的一家“医教研转工作统筹推进、防治康养手段综合应用、吃动睡想行为全面科学”的省三级公立综合医院。是河南省干部保健定点医院。
医院位于河南省省会郑州,有三个院区,郑东院区(郑东新区人民医院)比邻河南省政府。西院区位于中原区伏牛路陇海路交叉口;857院区位于中原区陇海路328号。医院有2个急救站,5个急救联盟单位、4个社区卫生服务中心;下设司法鉴定中心。
医院核定床位1800张,职工2113人,专业技术人员1903人,二级主任医�
化,汲取“智慧管理、人文管理、高科技创新、低成本高效运营”的现代化综合性医院之精髓,为患者提供安全、优质、便捷的医疗服务。
---------------------
根据上下文信息回答查询。
遵循以下规则:
1. 如果答案不在上下文中,只需说你不知道。
2. 避免使用“根据上下文...”或“提供的信息...”这样的表述。
3. 回答问题尽量精简
'RewriteQueryTransformer
RewriteQueryTransformer 利用大语言模型重写用户查询,从而在查询向量数据库或搜索引擎等目标系统时获得更好结果。
当用户查询冗长、含歧义或包含可能影响搜索结果质量的无关信息时,该转换器(Transformer)特别有效
修改代码如下:
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.topK(3)
.vectorStore(milvusVectorStore)
.build())
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(true)
.promptTemplate(customPromptTemplate)
.build())
.queryTransformers(RewriteQueryTransformer.builder()
.chatClientBuilder(this.client.mutate())
.build())
.build();通过queryTransformers()指定 RewriteQueryTransformer对象,提问如下:
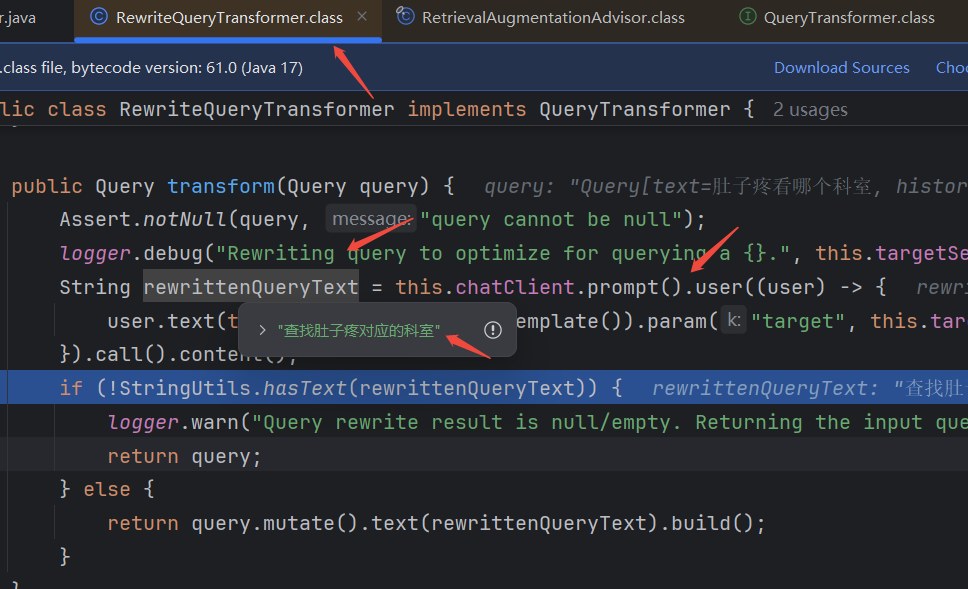
通过调试RewriteQueryTransformer源码,可以看到源码的transform()方法,将我们的提问先发给大模型,大模型根据提问内容返回重写的查询信息。本例,我们提问的内容是“肚子疼看哪个科室”,大模型给出的重写后的查询为“查找肚子疼对应的科室”。程序内部,根据重写后的内容再次向大模型发送提问。


















 3044
3044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









