






 本文深入解析并查集数据结构原理,通过实例说明其在处理不相交集合问题中的应用,包括查找、合并操作及如何统计集合数量。并提供并查集的代码实现,展示在朋友圈关系和等式方程可满足性问题中的实际运用。
本文深入解析并查集数据结构原理,通过实例说明其在处理不相交集合问题中的应用,包括查找、合并操作及如何统计集合数量。并提供并查集的代码实现,展示在朋友圈关系和等式方程可满足性问题中的实际运用。
一、并查集原理
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中。这一类问题只能用并查集来描述。
并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。
举个栗子:某公司今年校招全国总共招生10人,西安招4人,成都招3人,武汉招3人,10个人来自不同的学校,起先互不相识,每个学生都是一个独立的小团体,现给这些学生进行编号:{0,1,2,3,4, 5, 6, 7, 8, 9}; 给以下数组用来存储该小集体,数组中的数字代表:该小集体中具有成员的个数。
西安学生小分队s1={0,6,7,8},成都学生小分队s2={1,4,9},武汉学生小分队s3={2,3,5}就相互认识了,10个人形成了三个小团体。假设右三个群主0,1,2担任队长,负责大家的出行。

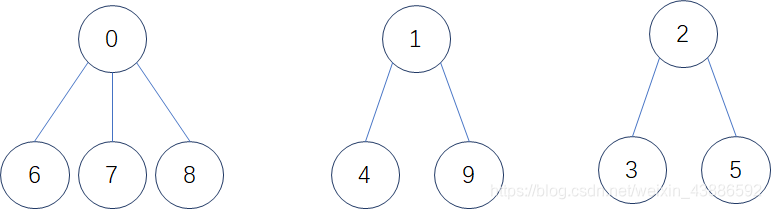
1、定义:
- 数组下标对应集合中元素的编号;
- 数组中数据为负数,就代表它为根,值的绝对值代表这个集合中数据的个数;
- 数组中数据为非负数,值就代表他的根在数组中的下标;
则有:
2、查找
- 查找时沿着数据存储的值找到父节点,直到父节点存储的值为负数即找到所处集合中的根;
3、判断两个数据是否属于一个集合
- 找到两个数据的根判断是否为同一个即可;
4、合并两个集合
- 将大集合的根加上小集合的根的值
- 将小集合的根的值变成大集合根的下标
5、判断集合的个数
- 遍历数组,数组中元素的值为负数就是一个集合的根,统计负数的个数就是集合的个数;

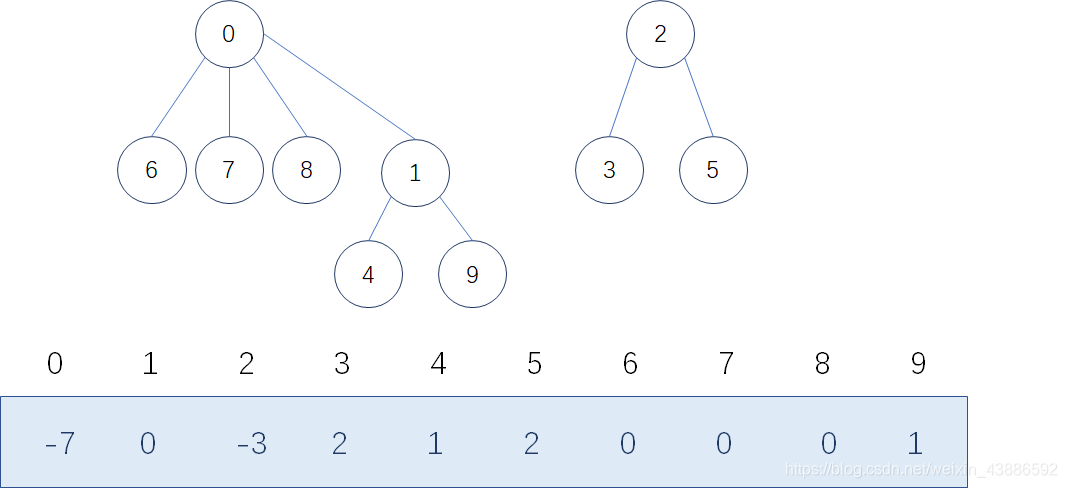
二、代码实现
UnionFindSet.h
#pragma once
#include<vector>
#include<iostream>
using namespace std;
class UnionFindSet
{
private:
vector<int> m_a;
public:
UnionFindSet(size_t Size = 0)//构造函数
{
m_a.resize(Size, -1);
}
UnionFindSet(const vector<int>& v):
m_a(v)
{}
int FindRoot(int index)//查找index的根
{
while (m_a[index] >= 0)
{
//每个元素存储的值是根节点的下标(>=0),只有根节点存储的是这个集合的个数(<0)
index = m_a[index];
}
return index;
}
bool Union(int x1, int x2)//合并两个集合
{
if (x1 == x2)
{
return true;
}
int root1 = FindRoot(x1);//找到根节点的下标
int root2 = FindRoot(x2);
if (root1 != root2)//不是一个集合才合并
{
if (m_a[root1] > m_a[root2])//保证root1为大集合,小集合合并到大集合中
{
int tmp = root1;
root1 = root2;
root2 = tmp;
}
m_a[root1] += m_a[root2];//跟节点的值加上新合并的个数
m_a[root2] = root1;//被合并集合的根节点的值变成新的跟节点的下标
return true;
}
return false;
}
size_t Count()const//统计根的个数,即集合的个数
{
size_t cnts = 0;
for (auto& e : m_a)
{
if (e < 0)
{
cnts++;
}
}
return cnts;
}
};
main.cpp
#include"UnionFindSet.h"
int main()
{
UnionFindSet unf(10);
unf.Union(0, 6);//三个集合{0,6,7,8},{1,4,9},{2,3,5}
unf.Union(6, 7);
unf.Union(0, 8);
unf.Union(1, 4);
unf.Union(4, 9);
unf.Union(2, 3);
unf.Union(2, 5);
cout << unf.Count() << endl;
return 0;
}

三、应用
1.朋友圈
班上有 N 名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A 是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C 的朋友。所谓的朋友圈,是指所有朋友的集合。
给定一个 N * N 的矩阵 M,表示班级中学生之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。
class Solution {
vector<int> m_s_v;
public:
int find(int x)//查找两个元素
{
while(m_s_v[x] >= 0)
{
x = m_s_v[x];
}
return x;
}
bool Union(int x,int y)//合并两个元素
{
if(x == y)
{
return false;
}
int root1 = find(x);
int root2 = find(y);
if(root1 != root2)
{
m_s_v[root1] += m_s_v[root2];
m_s_v[root2] = root1;
return true;
}
return false;
}
size_t Count()//统计集合的个数
{
int cnts = 0;
for(auto& e:m_s_v)
{
cout << e <<endl;
if(e < 0)
{
cnts++;
}
}
return cnts;
}
int findCircleNum(vector<vector<int>>& M)
{
m_s_v.resize(M.size(),-1);
for(int i = 0;i < M.size();i++)
{
for(int j = 0;j < M.size();j++)
{
if(i == j)//遍历一般即可,i是j的朋友,到[i][j]位置时已经把两个都加进去了
{
break;
}
if(M[i][j] == 1)
{
Union(i,j);
}
}
}
return Count();
}
};
给定一个由表示变量之间关系的字符串方程组成的数组,每个字符串方程 equations[i] 的长度为
4,并采用两种不同的形式之一:“a==b” 或 “a!=b”。在这里,a 和 b 是小写字母(不一定不同),表示单字母变量名。
只有当可以将整数分配给变量名,以便满足所有给定的方程时才返回 true,否则返回 false。
class Solution
{
vector<int> m_s_v;
public:
int find(int x)//查找两个元素
{
while(m_s_v[x] >= 0)
{
x = m_s_v[x];
}
return x;
}
bool Union(int x,int y)//合并两个元素
{
if(x == y)
{
return false;
}
int root1 = find(x);
int root2 = find(y);
if(root1 != root2)
{
m_s_v[root1] += m_s_v[root2];
m_s_v[root2] = root1;
return true;
}
return false;
}
bool equationsPossible(vector<string>& equations)
{
m_s_v.resize(26,-1);
for(auto& e:equations)//先将相等的拉入一个集合中
{
if(e[1] == '=')
{
Union(e[0]-'a',e[3]-'a');
}
}
for(auto& e:equations)//找不相等的,如果不在一个集合就会矛盾
{
if(e[1] == '!')
{
if(find(e[0]-'a') == find(e[3]-'a'))
{
return false;
}
}
}
return true;
}
};

















 1847
1847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









