






词向量学习笔记(二)Glove
文章目录
一、概述
GloVe的全称叫Global Vectors for Word Representation,是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。通过对向量的运算,比如欧几里得距离或者cosine相似度,可以计算出两个单词之间的语义相似性。
二、Glove原理
令词汇的共现矩阵为
X
X
X,
X
i
j
X_{ij}
Xij表示词汇
j
j
j出现在词汇
i
i
i上下文中的次数综合,则
X
i
=
∑
k
X
i
k
X_i=\sum_k X_{ik}
Xi=∑kXik为所有出现在词汇
i
i
i上下文中的词汇次数总和。令词汇
j
j
j出现在
i
i
i上下文的概率为
P
i
j
P_{ij}
Pij,则
P
i
j
=
P
(
j
∣
i
)
=
X
i
j
/
X
i
P_{ij}=P(j|i)=X_{ij}/X_i
Pij=P(j∣i)=Xij/Xi
根据论文《GloVe: Global Vectors for Word Representation》所列出的数据,可以看出
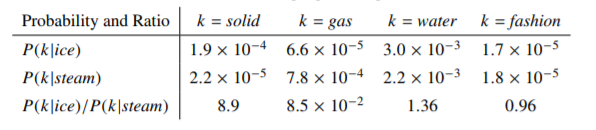
选定一个中心词
k
k
k,再选定两个对照词
a
,
b
a,b
a,b。分别计算中心词
k
k
k在对照词上下文出现的概率
P
(
k
∣
a
)
,
P
(
k
∣
b
)
P(k|a),P(k|b)
P(k∣a),P(k∣b),并计算二者的比值
λ
=
P
(
k
∣
a
)
P
(
k
∣
b
)
\lambda=\frac{P(k|a)}{P(k|b)}
λ=P(k∣b)P(k∣a)。如果
λ
<
<
1
\lambda<<1
λ<<1,则说明对于中心词
k
k
k,
b
b
b的相关度更高;反之
a
a
a相关度较高。如果
λ
\lambda
λ接近于1,则说明
k
k
k与
a
,
b
a,b
a,b的相关性较小。
为了能够通过训练词向量,从而计算得到上述的比例关系,定义函数
F
(
w
i
,
w
j
,
w
k
)
=
P
i
k
P
j
k
F(w_i,w_j,w_k)=\frac{P_{ik}}{P_{jk}}
F(wi,wj,wk)=PjkPik
其中,
w
i
,
w
j
,
w
k
w_i,w_j,w_k
wi,wj,wk为词汇对应的词向量,维度为
d
d
d,而
P
i
k
P
j
k
\frac{P_{ik}}{P_{jk}}
PjkPik能够通过分析语料得出。对
w
i
,
w
j
w_i,w_j
wi,wj进行差分,可以得到
F
(
w
i
−
w
j
,
w
k
)
=
P
i
k
P
j
k
F(w_i-w_j,w_k)=\frac{P_{ik}}{P_{jk}}
F(wi−wj,wk)=PjkPik
由于词向量的长度均为
d
d
d,因此可以进行向量内积,得到
F
(
(
w
i
−
w
j
)
T
w
k
)
=
F
(
w
i
T
w
k
−
w
j
T
w
k
)
=
P
i
k
P
j
k
F((w_i-w_j)^Tw_k)=F(w_i^Tw_k-w_j^Tw_k)=\frac{P_{ik}}{P_{jk}}
F((wi−wj)Twk)=F(wiTwk−wjTwk)=PjkPik
通过指数运算,将
F
F
F中的减法转化为除法,得出
exp
(
w
i
T
w
k
−
w
j
T
w
k
)
=
exp
(
w
i
T
w
k
)
exp
(
w
j
T
w
k
)
P
i
k
P
j
k
\exp(w_i^Tw_k-w_j^Tw_k)=\frac{\exp(w_i^Tw_k)}{\exp(w_j^Tw_k)}\frac{P_{ik}}{P_{jk}}
exp(wiTwk−wjTwk)=exp(wjTwk)exp(wiTwk)PjkPik
因此可以构造出如下方程组
{
exp
(
w
i
T
w
k
)
=
P
i
k
exp
(
w
j
T
w
k
)
=
P
j
k
\begin{cases} \exp(w_i^Tw_k)=P_{ik} \\ \exp(w_j^Tw_k)=P_{jk} \end{cases}
{exp(wiTwk)=Pikexp(wjTwk)=Pjk
又因为
exp
(
w
i
T
w
k
)
=
P
i
k
=
X
i
k
X
i
\exp(w_i^Tw_k)=P_{ik}=\frac{X_{ik}}{X_i}
exp(wiTwk)=Pik=XiXik,可以得到
w
i
T
w
k
=
log
(
X
i
k
X
i
)
=
log
X
i
k
−
log
X
i
w_i^Tw_k=\log (\frac{X_{ik}}{X_i})=\log X_{ik}-\log X_i
wiTwk=log(XiXik)=logXik−logXi
对上述等式引入两个偏置项,时期具有对称性
w
i
T
w
k
=
log
X
i
k
−
b
i
−
b
k
w_i^Tw_k=\log X_{ik}-b_i-b_k
wiTwk=logXik−bi−bk
此时
log
X
i
\log X_i
logXi包含在偏置项
b
i
b_i
bi中。因此,此时模型的目标就转化为通过学习词向量的表示,使得上式两边尽量接近,通过计算两者之间的平方差来作为目标函数,即:
J
=
∑
i
,
k
=
1
V
(
w
i
T
w
k
+
b
i
+
b
k
−
log
X
i
k
)
2
J=\sum_{i,k=1}^V (w_i^Tw_k+b_i+b_k-\log X_{ik})^2
J=i,k=1∑V(wiTwk+bi+bk−logXik)2
在对上式进行优化,针对预料中共现词汇的统计次数,设置其在目标函数中的权重,得出
J
=
∑
i
,
k
=
1
V
f
(
X
i
k
)
(
w
i
T
w
k
+
b
i
+
b
k
−
log
X
i
k
)
2
J=\sum_{i,k=1}^V f(X_{ik})(w_i^Tw_k+b_i+b_k-\log X_{ik})^2
J=i,k=1∑Vf(Xik)(wiTwk+bi+bk−logXik)2
其中,权重函数
f
f
f需要满足:
- f ( 0 ) = 0 f(0)=0 f(0)=0,当词汇共现的次数为0时,此时对应的权重应该为0。
- f ( x ) f(x) f(x)应该单调递增
- 对于那些太频繁的词, f ( x ) f(x) f(x)应设置一个相对小的数值,防止出现过度加权
因此,权重函数设置为
f
(
x
)
=
{
(
x
/
x
max
)
α
,
i
f
x
<
x
max
1
,
o
t
h
e
r
w
i
s
e
f(x)=\begin{cases} (x/x_{\max})^\alpha, if\ x<x_{\max} \\ 1, otherwise \end{cases}
f(x)={(x/xmax)α,if x<xmax1,otherwise
一般来说设置
α
=
3
4
\alpha=\frac{3}{4}
α=43时效果较好
三、Python中的Glove使用
3.1 总体思想
生成嵌入是一个两步过程: 从语料库中生成一个匹配矩阵,然后用它生成嵌入矩阵。 Corpus 类有助于从令牌的interable构建一个语料库。
3.2 数据集准备
- 用法:corpus_model.fit(corpus, window=10, ignore_missing=False)
sentences = LineSentence(r'E:/Machine Learning/Demo/wiki.zh.word.txt')
# 生成矩阵
corpus_model = Corpus()
corpus_model.fit(sentences,window=10)
# 保存矩阵模型
corpus_model.save('scorpus.matrix')
3.3 词向量训练
- 定义:glove = Glove(no_components=30, learning_rate=0.05, alpha=0.75, max_count=100, max_loss=10.0, random_state=None)
- no_components是所生成的词向量维数
- learning_rate是学习率
- alpha、max_count是权重参数
- max_loss是计算梯度时的最大绝对值
- random_state是随机状态
- 训练:glove.fit(matrix, epochs=10, no_threads=2)
- martix是上一步数据集生成的共现矩阵
- epochs是针对语料库的学习次数,默认为10
- no_threads是并行数,默认为2
glove = Glove(no_components=128, learning_rate=0.05)
glove.fit(corpus_model.matrix, epochs=2, no_threads=4,)
glove.add_dictionary(corpus_model.dictionary)
glove.save('sglove.model')
3.4 相关应用
3.4.1 求相似词
- 用法:
# 计算和一个词语最相关的词
items = glove.most_similar('维修', topn=5)
print("与'维修'相关的词有:")
for item in items:
# 词的内容,词的相关度
print(item[0], item[1])
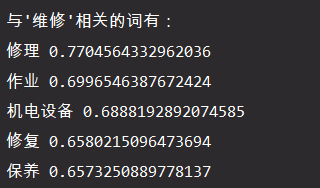
根据结果可以发现,Glove的模型在语义相关性上的表现不如Word2Vec,其原因主要是Glove模型的训练过程更加注重在共现型上,而对相关性的侧重不如Word2Vec。
3.4.2 查看两个词的相似度
- 用法:glove.similarity(w1, w2)
# 计算两个词语之间的相关度
val1 = glove.similarity('分布', '嵌入')
val2 = glove.similarity('数据', '信息')
print("分布/嵌入的相似度为:", val1)
print("数据/信息的相似度为:", val2)

3.4.3 词条的词向量
- 用法:glove.word_vectors[glove.dictionary[values]]
四、Glove与Word2Vec的区别
GloVe与Word2Vec,两个模型都可以根据词汇的共现信息,将词汇编码成一个向量。最直观的区别在于,Word2Vec是Predictive的模型,而GloVe是Count-Based的模型。
Predictive的模型是根据context预测中间的词汇,或者根据中间的词汇预测context,分别对应了Word2Vec的两种训练方式cbow和skip-gram。对于Word2Vec,采用三层神经网络就能训练,最后一层的输出要用一个Huffuman树进行词的预测。
Count-based模型,本质上是对共现矩阵进行降维。首先,构建一个词汇的共现矩阵,每一行是一个word,每一列是context。共现矩阵就是计算每个word在每个context出现的频率。由于context是多种词汇的组合,其维度非常大,因此需要在context的维度上降维,学习word的低维表示,即共现矩阵的重构问题。
两个模型在并行化上,GloVe更容易并行化。对于较大的训练数据,GloVe更快。

















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









