







 文章探讨了Spark中的RDD持久化机制,包括cache、persist和checkpoint。cache将数据存储在内存中,不安全但快速;persist可选择存储级别,包括磁盘,提供容错但较慢;checkpoint则是持久保存到磁盘,切断血缘关系,用于数据安全和高效重用。
文章探讨了Spark中的RDD持久化机制,包括cache、persist和checkpoint。cache将数据存储在内存中,不安全但快速;persist可选择存储级别,包括磁盘,提供容错但较慢;checkpoint则是持久保存到磁盘,切断血缘关系,用于数据安全和高效重用。
spark中的cache、persist、checkpoint都可以将RDD保存起来,进行持久化操作,供后面重用或者容错处理。但是三者有所不同。
cache
- 将数据临时存储在内存中进行数据重用,不够安全;
- 会在血缘关系中添加新的依赖,如果出现问题,可以重新从头读取数据。
persist
- 将数据临时存储在磁盘文件中进行数据重用;
- 涉及到磁盘IO,性能较低,但是数据安全;
- 如果作业执行完毕,临时保存的数据文件就会丢失。
checkpoint
- 将数据长久的保存在磁盘文件中进行数据重用;
- 涉及到磁盘IO,性能较低,但是数据安全;
- 为了保证数据安全,所以一般情况下,会独立执行作业;
- 为了能够提高效率,一般情况下,需要和cache联合使用。
RDD.cache() RDD.checkpoint(); - 需要指定保存路径,一般为HDFS;
- 执行过程中,会切断血缘关系,重新建立新的血缘关系。checkpoint等同于改变数据源。
血缘关系改变代码测试
- cache
package com.zsz.spark.core.rdd.operator.persist
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark_RDD_Persist {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("persist")
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.makeRDD(List("hello spark", "hello scala"))
val flatMapRDD: RDD[String] = rdd.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = flatMapRDD.map((_, 1))
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
mapRDD.cache()
// 打印血缘关系
println(mapRDD.toDebugString)
reduceRDD.collect().foreach(println)
println("*****************************")
// 打印血缘关系
println(mapRDD.toDebugString)
sc.stop()
}
}
输出结果:
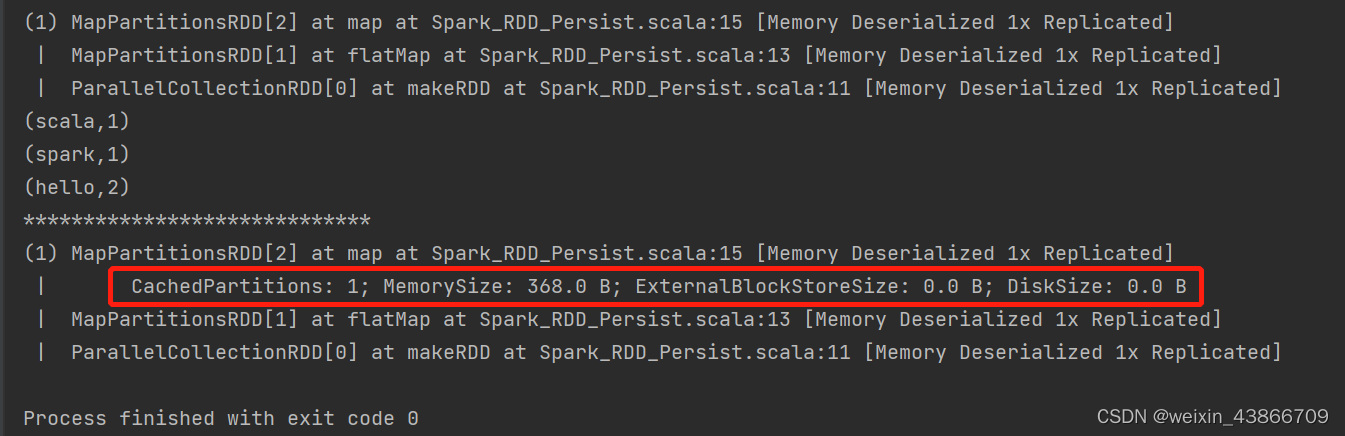
从结果可以看到,cache和persist方式会在血缘关系中添加新的依赖。
- checkpoint
package com.zsz.spark.core.rdd.operator.persist
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark_RDD_Persist {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("persist")
val sc = new SparkContext(conf)
sc.setCheckpointDir("cp")
val rdd: RDD[String] = sc.makeRDD(List("hello spark", "hello scala"))
val flatMapRDD: RDD[String] = rdd.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = flatMapRDD.map((_, 1))
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
// mapRDD.cache()
mapRDD.checkpoint()
// 打印血缘关系
println(mapRDD.toDebugString)
reduceRDD.collect().foreach(println)
println("*****************************")
// 打印血缘关系
println(mapRDD.toDebugString)
sc.stop()
}
}
输出结果:
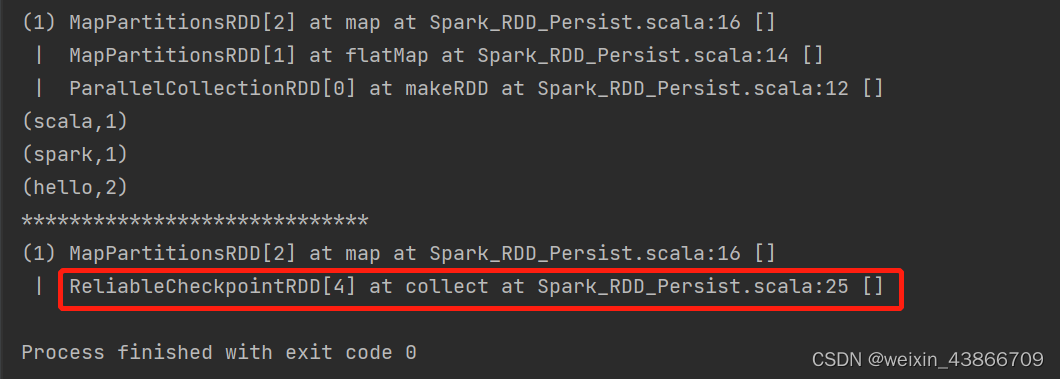
从结果看出,checkpoint会切断血缘关系,重新建立新的血缘关系。等同于改变数据源。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









