






 本文探讨了概率论如何在机器学习中用于处理数据的不确定性和可变性,介绍了概率、条件概率、独立事件、联合概率分布、随机变量等概念,并通过实例解释了它们在模式识别中的作用。此外,还讨论了随机变量的期望、方差、协方差和正态分布,以及在处理多个变量时的统计依赖性。这些理论基础对于理解和构建有效的机器学习模型至关重要。
本文探讨了概率论如何在机器学习中用于处理数据的不确定性和可变性,介绍了概率、条件概率、独立事件、联合概率分布、随机变量等概念,并通过实例解释了它们在模式识别中的作用。此外,还讨论了随机变量的期望、方差、协方差和正态分布,以及在处理多个变量时的统计依赖性。这些理论基础对于理解和构建有效的机器学习模型至关重要。
文章目录
模式识别和概率的关系
机器学习算法帮助我们分析数据以及提取和识别固有模式。现实中的数据拥有不确定性 (uncertainty) 和可变性 (variability)。概率论允许我们从数据中去建模这种不确定性和可变性。这些模型功能强大,同时为统计和概率推演提供了基础。
概率
概率论是不确定事件 (non-deterministic) 的学科。我们将一场实验中的可能产出用集合S来代表:
S = { f 1 , f 2 , f 3 , . . . , f 6 } S = \{f_1, f_2, f_3, ..., f_6\} S={f1,f2,f3,...,f6}
上式是投掷骰子的结果集,每个结果的可能性为:
p ( f i ) = 1 / 6 , i = 1 , 2 , . . . , 6 p(f_i) = 1 / 6, i = 1, 2, ..., 6 p(fi)=1/6,i=1,2,...,6
事件 (Events) 是样本空间 (sample space) 的子集,比如:
{
e
v
e
n
}
=
f
2
,
f
4
,
f
6
\{even\} = {f_2, f_4, f_6}
{even}=f2,f4,f6 以及
{
o
d
d
}
=
f
1
,
f
3
,
f
5
\{odd\} = {f_1, f_3, f_5}
{odd}=f1,f3,f5
当两个事件满足 A ∩ B = ∅ A \cap B = \varnothing A∩B=∅,我们可以说这两个事件是互斥的。
设我们拥有一个有限样本空间 S S S 以及一系列事件 { A , B , . . . } \{A, B, ...\} {A,B,...}。一个概率函数 (probability function) P P P, 其为每个事件输出一个实数以满足:
- 对于所有的事件,比如说 A A A,应该满足 0 ≤ P ( A ) ≤ 1 0 \le P(A) \le 1 0≤P(A)≤1.
- P ( S ) = 1 P(S) = 1 P(S)=1.
- 若 A A A 和 B B B 事件是互斥的,则 P ( A ∪ B ) = P ( A ) + P ( B ) P(A \cup B) = P(A) + P(B) P(A∪B)=P(A)+P(B)
若空间中的每一个样本点拥有相同的概率,我们可以称其为 等概率 (equiprobable) 或 均匀空间 (uniform space)。
我们可以使用 事件
A
A
A 中的 点数 (the number of points) 来得到其概率。
并集概率的求法,设我们有事件A和B:
P
(
A
∪
B
)
=
P
(
A
)
+
P
(
B
)
−
P
(
A
∩
B
)
P(A \cup B) = P(A) + P(B) - P(A \cap B)
P(A∪B)=P(A)+P(B)−P(A∩B)
条件概率 (Conditional Probability)
事件可以依赖于其他事件,也就是说,一件事的发生会影响另一件事的概率。
给定事件E发生的情况下,事件A发生的概率如下:
P ( A ∣ E ) = P ( A ∩ E ) P ( E ) P(A|E) = \frac{P(A \cap E)}{P(E)} P(A∣E)=P(E)P(A∩E)
独立事件 (Independent Events)
若 P ( A ∣ E ) = P ( A ) P(A|E) = P(A) P(A∣E)=P(A) ,则两个事件 E E E 和 A A A 是相互独立的,这是因为,E的发生并不会对A发生的概率产生影响。
同样的我们可以得出:
P ( A ∩ E ) = P ( A ∣ E ) P ( E ) = P ( A ) P ( E ) P(A \cap E) = P(A|E) P(E) = P(A)P(E) P(A∩E)=P(A∣E)P(E)=P(A)P(E)
互斥事件 (Mutually Exclusive Events)
若事件 E E E 和 A A A 是互斥的,则其中一个的发生互斥另一个的发生,即:
P ( A ∣ E ) = 0 P(A|E) = 0 P(A∣E)=0
这代表了互斥事件不是独立事件。
联合概率分布 (Joint Probability Distribution)
在这种情况下,样本空间由两个实验的结果对组成。
以下是例子说明,夏天温度和湿度的样本。
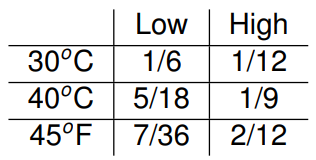
边际分布 (Marginal Distribution)
给定
(
X
,
Y
)
(X, Y)
(X,Y) 的联合分布,其能够推导出
X
X
X 和
Y
Y
Y的分布。
设
P
(
x
,
y
)
P(x, y)
P(x,y) 代表 样本点
(
x
,
y
)
(x, y)
(x,y) 的概率。
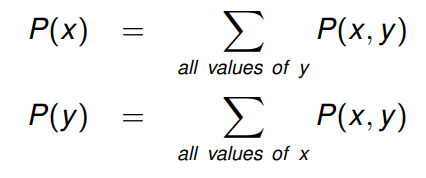
此时,
P
(
x
)
P(x)
P(x)和
P
(
y
)
P(y)
P(y)被称为边际分布。
如,上一节的联合概率分布的例子中,我们有如下的边际分布:
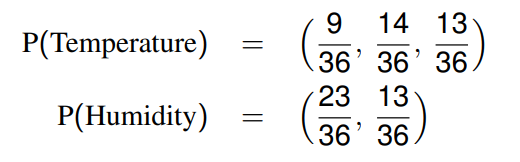
条件独立 (Conditional Independence)
假设 小明 和 小红 分别抛硬币。设 A 代表变量“小明 的投掷结果”,B 代表变量“小红 的投掷结果”。
A
A
A 和
B
B
B 都有两个可能的值(正面 和 反面)。没有任何争议,我们可以假设
A
A
A 和
B
B
B 是独立的。关于
B
B
B 的证据不会改变我们对
A
A
A 的信念。
现在假设 小明 和 小红 都掷相同的硬币。再次让
A
A
A 代表变量 “小明 的抛掷结果”,
B
B
B 代表变量 “小红 的抛掷结果”。
此时再假设硬币有可能偏向正面,但我们不确定这一点。在这种情况下,
A
A
A 和
B
B
B 不是独立的。例如,观察到
A
A
A 是正面会使我们更加相信
B
B
B 是正面。
在条件独立示例中,变量
A
A
A 和
B
B
B 都依赖于单独的变量
C
C
C,即“硬币偏向正面”(其值为 True 或 False)。虽然
A
A
A 和
B
B
B 不是独立的,但事实证明,一旦我们确定了
C
C
C 的值,那么任何关于
A
A
A 的证据都不能改变我们对
B
B
B 的信念。 具体来说:
P ( B ∣ C ) = P ( B ∣ A , C ) P(B|C) = P(B|A, C) P(B∣C)=P(B∣A,C)
另一个例子:
假设诺曼和马丁住在伦敦市的两侧,并以完全不同的方式来上班,比如诺曼坐火车来,马丁开车。 让
A
A
A 代表变量 “诺曼迟到了”(其值为
t
r
u
e
true
true 或
f
a
l
s
e
false
false),同样让
B
B
B 代表变量 “马丁迟到了”。 在这些情况下,假设
A
A
A 和
B
B
B 必须独立 是很符合直觉的。 然而,即使诺曼和马丁在不同的国家生活和工作,也可能存在一些因素(例如国际燃料短缺),这可能意味着
A
A
A 和
B
B
B 不是独立的。
在实践中,任何不确定性模型 (model of uncertainty) 都应考虑所有合理因素。
因此,虽然可以合理地排除撞击地球的陨石这一种特殊情况,但排除
A
A
A 和
B
B
B 都可能受到火车撞击 (
C
C
C) 的影响这一事实似乎并不合理。 因为如果 C 为真,显然
P
(
A
)
P(A)
P(A) 会增加,但由于由事故导致的道路额外交通,
P
(
B
)
P(B)
P(B) 也会增加。
因此,
P
(
A
∣
C
)
=
P
(
A
∣
B
,
C
)
;
P(A|C) = P(A|B,C);
P(A∣C)=P(A∣B,C);
P
(
A
,
B
∣
C
)
=
P
(
A
∣
C
)
×
P
(
B
∣
C
)
P(A,B|C)=P(A|C)×P(B|C)
P(A,B∣C)=P(A∣C)×P(B∣C)
A
A
A 和
B
B
B 在给定
C
C
C 的时候 条件独立。在事件之间保持条件独立的典型情况是,当多个事件共享一个共同的原因时。
随机变量 (Random Variables)
随机变量为概率空间中的事件赋值,其可以看做是能输出实值的函数。
使随机变量
X
X
X 能够获得
x
1
,
x
2
,
.
.
.
,
x
N
x_1, x_2, ..., x_N
x1,x2,...,xN
X
X
X的期望是:
E ( X ) = ∑ x n p ( x n ) E(X) = \sum x_n p(x_n) E(X)=∑xnp(xn)
期望值可以看作是随机变量的平均值。
定义一个随机变量(RV)
X
X
X 作为样本空间
S
S
S 的 实值函数(real-valued function),其范围由
R
X
R_X
RX表示。此外,若范围
R
X
R_X
RX是离散集,则RV是离散的。因此,离散RV
X
X
X 的概率函数是:
p
X
(
x
)
=
P
(
X
=
x
)
p_X(x) = P(X = x)
pX(x)=P(X=x)
假设现在机器学习班里有十个学生,现在我们考虑他们的年龄。有三个19岁的同学,四个20岁,一个21岁,一个24岁以及一个26岁。我们要从中无重复地随机选取两个学生。
我们让
X
X
X 来表示两个所选学生的平均年龄 的随机变量,并推导出
X
X
X 的概率函数。
从十个学生中选择两个 的方法总数为45,因为:
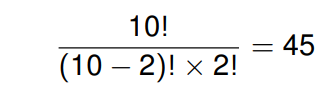
而从
{
19
,
20
,
21
,
24
,
26
}
\{19, 20, 21, 24, 26\}
{19,20,21,24,26}中能得到的 两个年龄的平均数 的总数为10。
它们是
{
19
,
19.5
,
20
,
20.5
,
21.5
,
22
,
22.5
,
23
,
23.5
,
25
}
\{19, 19.5, 20, 20.5, 21.5, 22, 22.5, 23, 23.5, 25\}
{19,19.5,20,20.5,21.5,22,22.5,23,23.5,25}
45种方法中,使得平均年龄为19有三种方法
P
(
X
=
19
)
=
3
45
P(X=19) = \frac{3}{45}
P(X=19)=453。而45种方法中,有
3
×
4
=
12
3 × 4 = 12
3×4=12 种方法使得平均年龄为19.5。在45种方法中,有
6
+
3
=
9
6+3=9
6+3=9种方法使得结果为20。使用类似的办法得到下列表格。
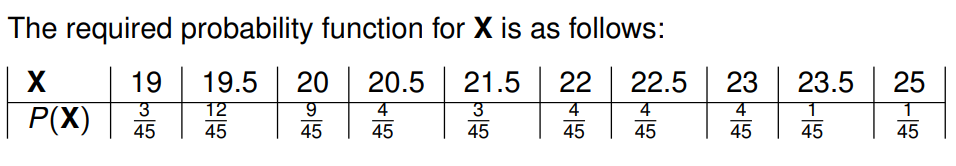
二阶矩和方差 (Second Moment and Variance)
取值为
x
i
x_i
xi 的随机变量
X
X
X 的二阶矩是:
E
[
X
2
]
=
∑
i
x
i
2
P
(
x
i
)
E[X^2] = \sum_i x_i^2 P(x_i)
E[X2]=∑ixi2P(xi)
若我们将
X
X
X 的期望用
μ
=
E
[
X
]
\mu = E[X]
μ=E[X] 来代表,则
X
X
X 的方差为,
V
a
r
{
X
}
=
σ
2
=
E
[
(
X
−
μ
)
2
]
=
∑
i
(
x
i
−
μ
)
2
P
(
x
i
)
Var\{X\} = \sigma^2 = E[(X - \mu)^2] = \sum_i(x_i-\mu)^2P(x_i)
Var{X}=σ2=E[(X−μ)2]=∑i(xi−μ)2P(xi)
其中,
σ
\sigma
σ 是
X
X
X 的标准差。
两个随机变量的函数
若我们拥有两个随机变量的函数 f ( x , y ) f(x, y) f(x,y), 且其以 P ( x , y ) P(x, y) P(x,y) 联合概率分布。则该函数的期望为:
E [ f ( x , y ) ] = ∑ R X ∑ R Y f ( x , y ) P ( x , y ) E[f(x, y)]=\sum_{R_X}\sum_{R_Y}f(x, y)P(x, y) E[f(x,y)]=∑RX∑RYf(x,y)P(x,y)
其中 R X R_X RX 和 R Y R_Y RY 分别是 X X X 和 Y Y Y 的范围。
期望算子 (expectation operator) 是一个线性函数,因为对于任意函数
f
1
(
x
,
y
)
f_1(x, y)
f1(x,y)
f
2
(
x
,
y
)
f_2(x, y)
f2(x,y),以及标量
α
1
\alpha_1
α1 和
α
2
\alpha_2
α2,满足:
E
[
α
1
f
1
(
x
,
y
)
+
α
2
f
2
(
x
,
y
)
]
=
α
1
E
[
f
1
(
x
,
y
)
]
+
α
2
E
[
f
2
(
x
,
y
)
]
E[α_1f_1(x, y) + α_2f_2(x, y)] = α_1E[f_1(x, y)] + α_2E[f_2(x, y)]
E[α1f1(x,y)+α2f2(x,y)]=α1E[f1(x,y)]+α2E[f2(x,y)]
X
X
X和
Y
Y
Y的期望可以被写为:
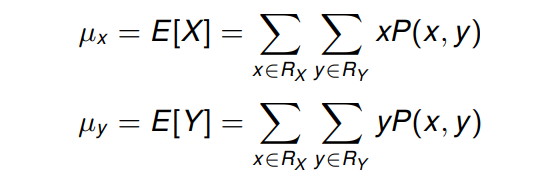
而方差 (variance) 可以被写为:
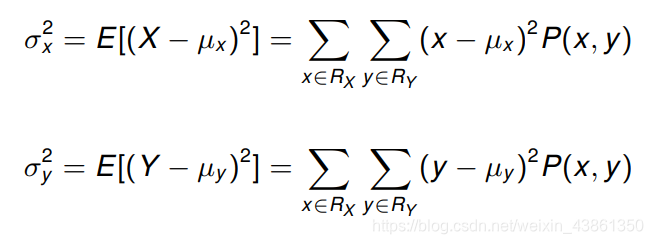
协方差 (Covariance)
X
X
X和
Y
Y
Y的协方差被定义为:
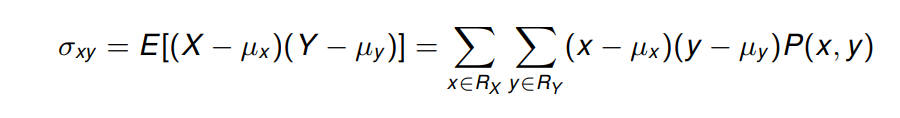
协方差 (covariance) 是衡量
X
X
X 和
Y
Y
Y 之间 统计依赖 (statistical dependence) 程度的指标。如果
X
X
X 和
Y
Y
Y 在统计上独立,则
σ
x
y
=
0
σ_{xy} = 0
σxy=0。若
σ
x
y
=
0
σ_{xy} = 0
σxy=0,则这两个随机变量被称为 不相关 (uncorrelated)。(并不意味着不相关的变量必须在统计上独立。)
请注意,如果不相关变量具有多元正态分布 (multivariate normal distribution),则它们在统计上是独立的。
若我们拥有关系
Y
=
α
X
Y=\alpha X
Y=αX,则这代表了
Y
Y
Y 强烈依赖
X
X
X,且
σ
x
y
=
α
σ
x
\sigma_{xy}=\alpha\sigma_x
σxy=ασx。
当协方差为正数,则
X
X
X 和
Y
Y
Y 同时增加和减少,而若负数,则当
X
X
X 减少时
Y
Y
Y 增加。
相关系数 (correlation coefficient) 被定义为:
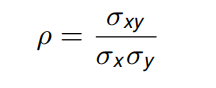
是归一化协方差 (normalized covariance),取值在 -1 到 +1 之间。
向量随机变量 (Vector Random Variables)
若我们拥有超过两个变量的时候,将其用向量表示更为方便。
让 x x x 代表一个随机 d d d 维向量,其中元素有 x 1 , x 2 , . . . , x d x_1, x_2, ..., x_d x1,x2,...,xd。
联合分布 (joint distribution) 可以获得并且通常会很复杂。 如果变量在统计上是独立的,联合概率质量函数 (joint probability mass function),
P
(
x
)
P(x)
P(x) 如下,
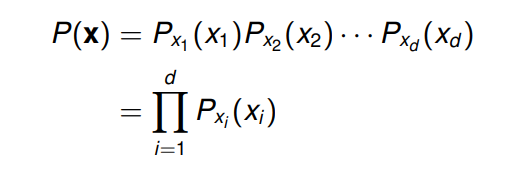
边际分布
P
x
i
(
x
i
)
P_{xi}(x_i)
Pxi(xi) 是通过对其他变量的联合分布求和来获得的。
向量的期望值被定义为其元素为 原始元素的期望值 (expected values of the original components) 的向量。
d
d
d 维均值向量
μ
\mu
μ (mean vector) 被定义为:
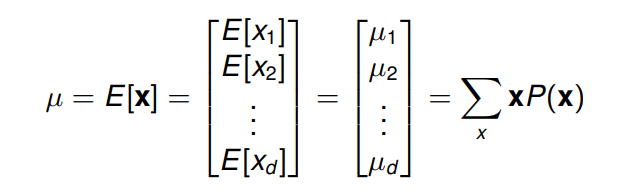
协方差矩阵被用 ∑ \sum ∑ 代表,其定义为:
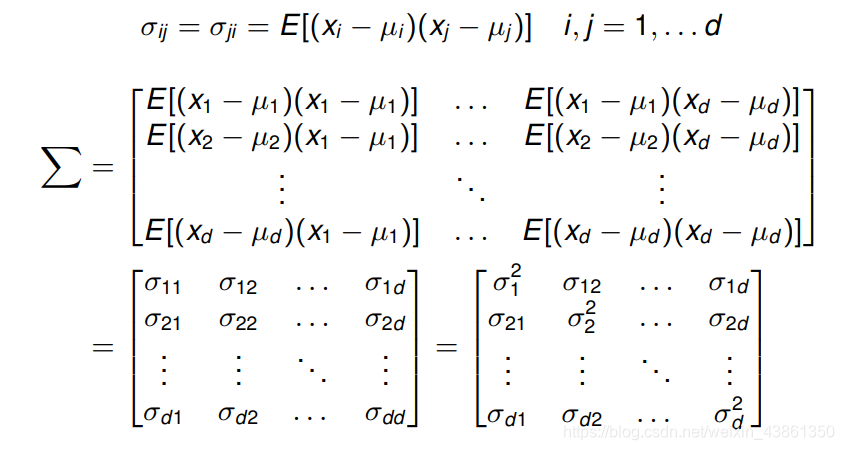
协方差矩阵
∑
\sum
∑ 可以被写为以下形式:
∑
=
E
[
(
x
−
μ
)
(
x
−
μ
)
t
]
\sum = E[(x-\mu)(x-\mu)^t]
∑=E[(x−μ)(x−μ)t]
协方差矩阵是对称 (symmetric) 的,对角线元素是 x 的各个元素的方差。 它们总是正的。
不在对角线上的元素是协方差,且它们是正的或者负的。
如果变量是统计独立的,协方差是0 且 协方差矩阵是对角矩阵。
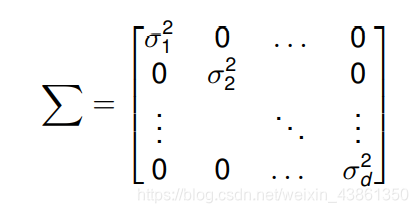
对于任意
d
d
d 维向量
w
w
w,若其二次型 (quadratic form)
w
t
∑
w
>
0
w^t \sum w\gt 0
wt∑w>0,则
∑
\sum
∑ 是正定矩阵 (positive definite)。若
w
t
∑
w
≥
0
w^t \sum w\ge 0
wt∑w≥0,则其是正半定矩阵 (positive semi-definite)。
连续随机变量 (Continuous Random Variables)
如果随机变量可以在 连续体(continuum) 中取值,我们将其称为连续随机变量,并根据其概率密度函数 (probability density function) 对其进行描述。
概率密度函数如下
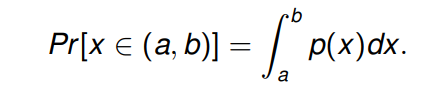
这代表了 连续随机变量
x
x
x 在 范围
(
a
,
b
)
(a, b)
(a,b) 中的概率。
以下式子为真
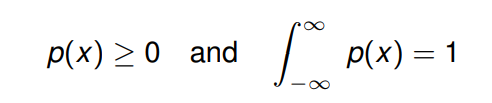
正态分布 (Normal Distributions)
正态或高斯分布的概率密度函数被定义为 (考虑单随机变量):
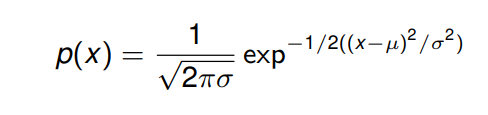
以下期望值可以被计算:
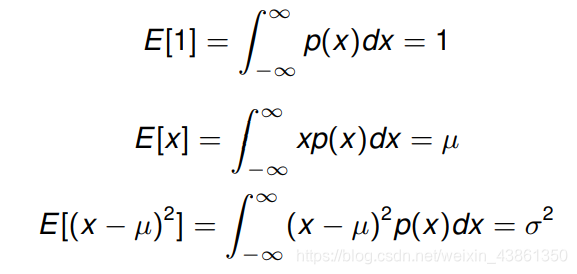

















 2761
2761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









