




 本文探讨了Generalized Focal Loss在目标检测中的应用,分析了现有one-stage anchor-free检测器存在的问题,包括训练与测试阶段的不一致以及边界框表示的局限性。为解决这些问题,文章提出将分类与质量估计进行联合表示,并使用离散化方法回归任意分布以建模复杂场景下边界框的不确定性。GFL(Generalized Focal Loss)的优化方法包括Quality Focal Loss和Distance Focal Loss的结合。
本文探讨了Generalized Focal Loss在目标检测中的应用,分析了现有one-stage anchor-free检测器存在的问题,包括训练与测试阶段的不一致以及边界框表示的局限性。为解决这些问题,文章提出将分类与质量估计进行联合表示,并使用离散化方法回归任意分布以建模复杂场景下边界框的不确定性。GFL(Generalized Focal Loss)的优化方法包括Quality Focal Loss和Distance Focal Loss的结合。
Generalized Focal Loss
motivation:
目前比较强力的one-stage anchor-free的检测器(以FCOS,ATSS为代表)基本会包含3个表示:
-
分类表示:cls
-
检测框表示:box
-
检测框的质量估计(在FCOS/ATSS中,目前采用centerness,当然也有一些其他类似的工作会采用IoU,这些score基本都在0~1之间):iou or centerness
问题一:classification score 和 IoU/centerness score 训练测试不一致。

两个方面:
1) 用法不一致。训练的时候,分类和质量估计各自训记几个儿的,但测试的时候却又是乘在一起作为NMS score排序的依据,这个操作显然没有end-to-end,必然存在一定的gap。
2) 对象不一致。借助Focal Loss的力量,分类分支能够使得少量的正样本和大量的负样本一起成功训练,但是质量估计通常就只针对正样本训练。那么,对于one-stage的检测器而言,在做NMS score排序的时候,所有的样本都会将分类score和质量预测score相乘用于排序,那么必然会存在一部分分数较低的“负样本”的质量预测是没有在训练过程中有监督信号的,有就是说对于大量可能的负样本,他们的质量预测是一个未定义行为。这就很有可能引发这么一个情况:一个分类score相对低的真正的负样本,由于预测了一个不可信的极高的质量score,而导致它可能排到一个真正的正样本(分类score不够高且质量score相对低)的前面。
问题二:bbox regression 采用的表示不够灵活,没有办法建模复杂场景下的uncertainty。
问题二比较好理解,在复杂场景中,边界框的表示具有很强的不确定性,而现有的框回归本质都是建模了非常单一的狄拉克分布,非常不flexible。我们希望用一种general的分布去建模边界框的表示。

methods:
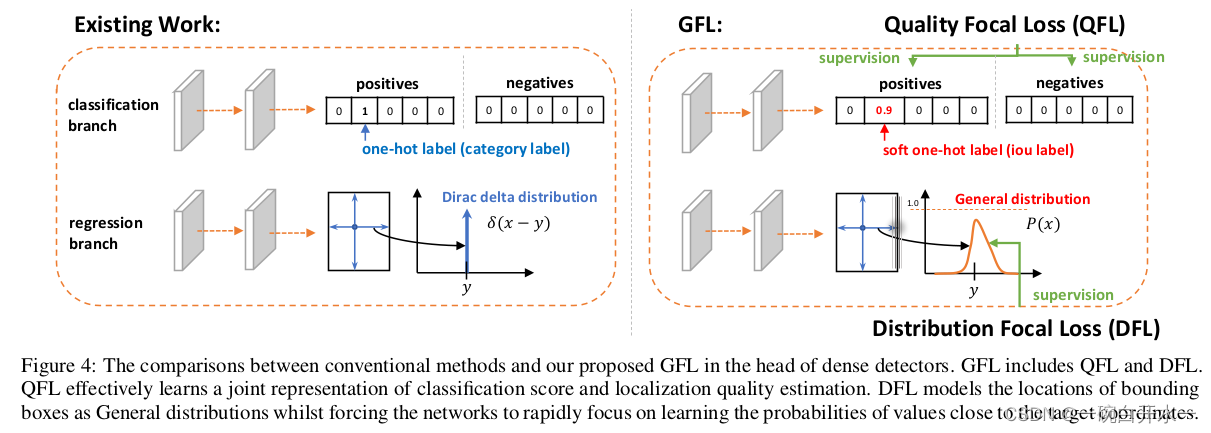
-
对于第一个问题,为了保证training和test一致,同时还能够兼顾分类score和质量预测score都能够训练到所有的正负样本,那么一个方案呼之欲出:就是将两者的表示进行联合。这个合并也非常有意思,从物理上来讲,我们依然还是保留分类的向量,但是对应类别位置的置信度的物理含义不再是分类的score,而是改为质量预测的score。这样就做到了两者的联合表示,同时,暂时不考虑优化的问题,我们就有可能完美地解决掉第一个问题。
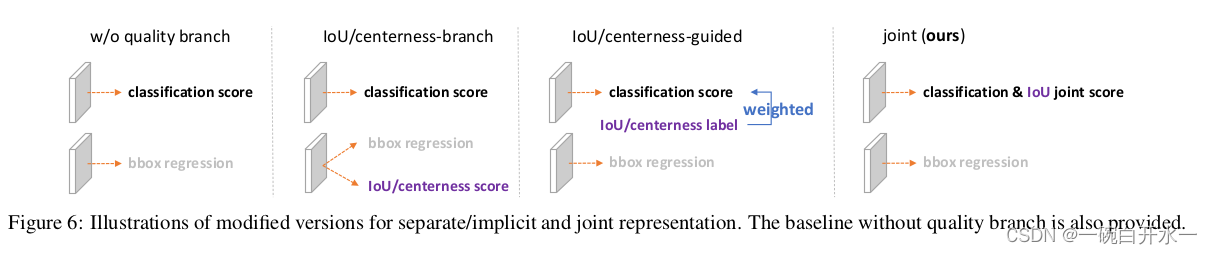
-
对于第二个问题,我们选择直接回归一个任意分布来建模框的表示。当然,在连续域上回归是不可能的,所以可以用离散化的方式,通过softmax来实现即可。这里面涉及到如何从狄拉克分布的积分形式推导到一般分布的积分形式来表示框,详情可以参考原论文。
-

如何优化:
GFL=QFL+DFL
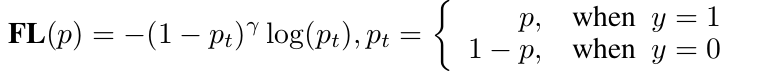
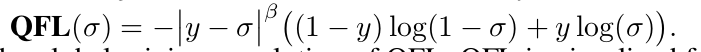

DFL:
dis_left = label.long()
dis_right = dis_left + 1
weight_left = dis_right.float() - label
weight_right = label - dis_left.float()
loss = F.cross_entropy(pred, dis_left, reduction='none') * weight_left \
+ F.cross_entropy(pred, dis_right, reduction='none') * weight_right




















 3233
3233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











