







一、基本介绍
- Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
- HDFS(分布式文件系统):引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取
- MapReduce(计算框架):MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度 器(JobTracker)对任务进行分布式计算
二、基本作用
- 大数据存储:分布式存储
- 日志处理:擅长日志分析
- ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
- 机器学习: 比如Apache Mahout项目
- 搜索引擎:Hadoop + lucene实现
- 数据挖掘:目前比较流行的广告推荐,个性化广告推荐
- Hadoop是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。
- 优点
1、支持超大文件。HDFS存储的文件可以支持TB和PB级别的数据。
2、检测和快速应对硬件故障。数据备份机制,NameNode通过心跳机制来检测DataNode是否还存在。
3、高扩展性。可建构在廉价机上,实现线性(横向)扩展,当集群增加新节点之后,NameNode也可以感知,将数据分发和备份到相应的节点上。
4、成熟的生态圈。借助开源的力量,围绕Hadoop衍生的一些小工具。 - 缺点
1、不能做到低延迟。高数据吞吐量做了优化,牺牲了获取数据的延迟。
2、不适合大量的小文件存储。
3、文件修改效率低。HDFS适合一次写入,多次读取的场景。
三、基础架构原理
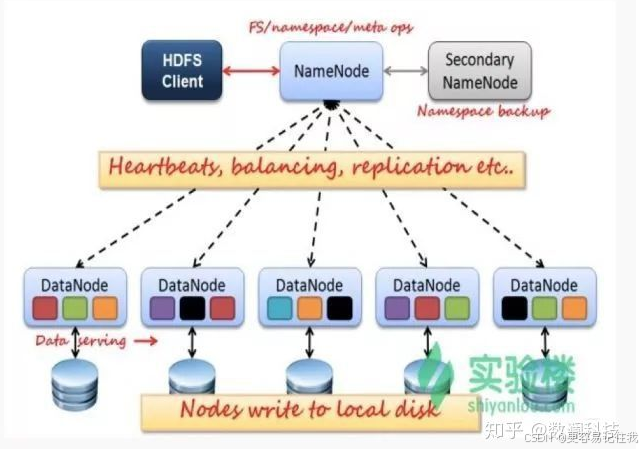
- HDFS
- HDFS框架分析:HDFS是Master和Slave的主从结构。主要由Name-Node、Secondary NameNode、DataNode构成。
- NameNode:管理HDFS的名称空间和数据块映射信存储元数据与文件到数据块映射的地方;可做HA
- Secondary NameNode:辅助NameNode,分担NameNode工作,紧急情况下可辅助恢复NameNode
- DataNode:Slave节点,实际存储数据、执行数据块的读写并汇报存储信息给NameNode。
- 数据按照block(块)存放在DataNode上,作为存储和传输的基本单位
- 文件读取流程:请求信息会通知NameNode会将读取任务分发给多个DataNode,最终汇总数据到NameNode
- 向nameNode通讯元数据,
- nameNode(就近原则后随即原则)构建DataNode的socket连接,
- dataNode从磁盘读取数据(packet为单位),合并汇总成最终的数据文件
- 文件写入流程:
- 请求发送到NameNode,NameNode检查文件是否存在,父目录是否存在
- 返回确认上传
- client会先对文件按照block大小进行切分
- clent请求第一台DataNode,然后继续调用后续节点,将整个通道建立完成,逐级返回客户端
- 按照顺序进行数据传输
- HDFS框架分析:HDFS是Master和Slave的主从结构。主要由Name-Node、Secondary NameNode、DataNode构成。
- MapReduce:map:将文件片交给不同机器处理;reduce:整合Map任务数据
- 工作流程
- 拆分计算任务为多个Map,各个Map任务会将生成的中间文件传输到Reduce,Reduce整合个计算机处理的数据
- 工作流程
四、安装部署
1master + 1masterB + 3slaves
-
配置服务映射(全部节点)
- hostname 查看服务名称 (假设 master1, master2,salve1,salve2,salve3)
- 编辑 /etc/hosts文件
192.168.1.1 master1 192.168.1.2 master2 192.168.1.1 salve1 192.168.1.2 salve2 192.168.1.3 salve3 -
配置主节点ssh免密码登录
- 生成密钥:ssh-keygen -t rsa -P ‘’
- 进入密钥生成文件(根据生成提示找到准确的目录):cd /root/.ssh/
- 将id_rsa.pub加到授权中: cat id_rsa.pub >> authorized_keys
- 如果使用的是非root用户,还需要修改文件"authorized_keys"权限并设置/etc/ssh/sshd_config
- 修改文件"authorized_keys":chmod 600 ~/.ssh/authorized_keys
- // ~表示 hme目录下的当前用户目录,例如omm用户,则代表 /home/omm
- 设置SSH配置,编辑/etc/ssh/sshd_config文件
RSAAuthentication yes # 启用 RSA 认证 PubkeyAuthentication yes # 启用公钥私钥配对认证方式 AuthorizedKeysFile /root/.ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)- 重启SSH服务:service sshd restart
- 修改文件"authorized_keys":chmod 600 ~/.ssh/authorized_keys
- 将主节点密钥复制到其他机器上:ssh-copy-id root@其他机器ip
-
解压到/opt/hadoop目录下
-
修改配置文件
- core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- 主机地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <!-- 临时文件地址 --> <property> <name>hadoop.tmp.dir</name> <value>/tmp/hadoop</value> </property> </configuration>- mapperd-site.xml
<configuration> <!-- 指定资源管理yran --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>- hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- 副本数,小于等于slaves个数--> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 主节点备机 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.1.41:8020</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/name</value> </property> </configuration>- yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:18040</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:18030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:18025</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:18141</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:18088</value> </property> </configuration> -
修改slaves文件:删除原有的localhost那一行,添加上salves的地址:类似加上下面三行(三台机器的域名或者ip)
salve1 192.168.1.1 salve2 192.168.1.2 salve3 192.168.1.3 -
在其他机器上安装并配置相同的hadoop或者直接复制hadoop到其他机器上
- scp -r /opt/hadoop root@master2:/opt/hadoop
-
配置环境变量
-
格式化master节点hadoop:hadoop namenode -format
-
启动hadoop: NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager
六、问题
- ERROR tool.ImportTool: Import failed: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://hacluster/user/root/qz_data already exists
- 原因:这是因为每次MR都会生成一个output目录但是不能自动删除
- 解决:所以我们就把HDFS的输出目录删除:
- hadoop fs -ls -R:查看目录
- hadoop fs -rm -r output:删除输出目录
- 若果已经存在.Trash文件,先删除 .Trash
五、hadoop相关命令
- sbin/start-all.sh: 启动所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager
- sbin/stop-all.sh: 停止所有的Hadoop守护进程。包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager
- sbin/start-dfs.sh: 启动Hadoop HDFS守护进程NameNode、SecondaryNameNode、DataNode
- sbin/stop-dfs.sh: 停止Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode
- sbin/hadoop-daemons.sh start namenode: 单独启动NameNode守护进程
- sbin/hadoop-daemons.sh stop namenode: 单独停止NameNode守护进程
- sbin/hadoop-daemons.sh start datanode: 单独启动DataNode守护进程
- sbin/hadoop-daemons.sh stop datanode: 单独停止DataNode守护进程
- sbin/hadoop-daemons.sh start secondarynamenode: 单独启动SecondaryNameNode守护进程
- sbin/hadoop-daemons.sh stop secondarynamenode: 单独停止SecondaryNameNode守护进程
- sbin/start-yarn.sh: 启动ResourceManager、NodeManager
- sbin/stop-yarn.sh: 停止ResourceManager、NodeManager
- sbin/yarn-daemon.sh start resourcemanager: 单独启动ResourceManager
- sbin/yarn-daemons.sh start nodemanager: 单独启动NodeManager
- sbin/yarn-daemon.sh stop resourcemanager: 单独停止ResourceManager
- sbin/yarn-daemons.sh stopnodemanager: 单独停止NodeManager

















 5453
5453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









