







PostGIS教程学习十九:基于索引的聚簇
数据库只能以从磁盘获取信息的速度检索信息。小型数据库将完全位于于RAM缓存(内存),并摆脱物理磁盘访问速度慢的限制。但是对于大型数据库,对物理磁盘的访问将限制数据库的信息检索速度。
数据是偶尔写入磁盘的,因此存储在磁盘上的有序数据与应用程序访问或组织该数据的方式之间不需要存在任何关联。
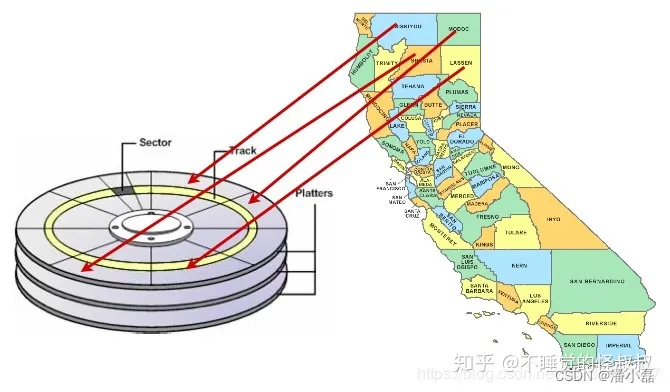
加速数据访问的一种方法是确保可能在同一结果集中一起被检索的记录位于硬盘上的相近物理位置。这就是所谓的"聚簇(clustering)"。
要使用正确的聚簇方案可能很棘手,但可以遵循一条通用性规则:索引定义了数据的自然排序方案,该方案类似于检索数据的访问模式。
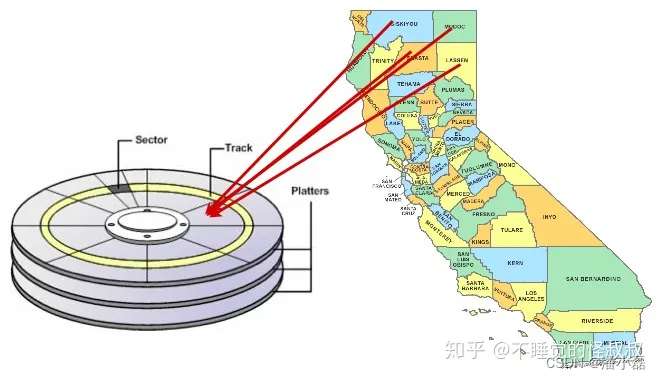
正因为如此,在某些情况下,以与索引相同的顺序对磁盘上的数据进行排序可以加速数据访问速度。
一、基于R-Tree的聚簇
空间数据倾向于在客户端的窗口中访问:想想Web应用程序或桌面应用程序中的地图窗口。窗口中的所有数据都具有相近的位置信息(否则它们将不在相同的窗口中!)。
因此,基于空间索引的聚簇对于将通过空间查询访问的空间数据是有意义的:相似的事物往往具有相似的位置(地理学第一定律&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2417
2417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









