







机器学习(3)基于近邻用户、近邻物品的协同过滤算法
一、基于近邻用户的协同过滤
基于近邻用户的协同过滤算法(简称UserCF):给用户 A 推荐和他有着相似观影兴趣的用户 B 喜欢观看的电影。如图所示:
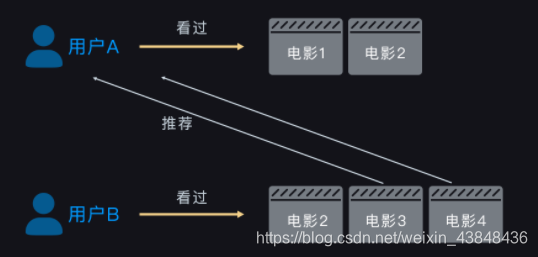
基于近邻用户的协同过滤算法,第一个要理解的点是近邻用户,也就是兴趣相似的用户;第二个要理解的点是协同过滤算法到底指的是什么?所谓的协同过滤,其实指的是一类算法的称呼:根据用户的行为数据给用户产生推荐结果的一类算法。用电影推荐为例子:
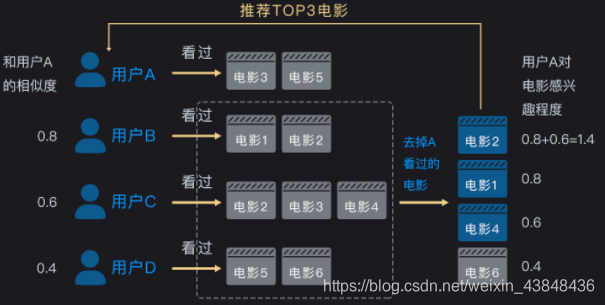
首先要找到和用户 A 观影兴趣最相似的 K 个用户,然后再从这 K 个用户喜欢的电影中,找到用户 A 没有看过的电影,推荐给 A。如图所示,先不考虑相似度的计算方法,K=3 的情况下,和用户 A 最相似的 3 个用户依次是用户 B、C、D,从这 3 个用户喜欢的电影集合中过滤掉用户 A 看过的电影,然后计算 A 对剩下的电影感兴趣的程度,从中选取最感兴趣的的 3 个电影推荐给用户 A 。这里的推荐数量根据产品需求来设定,不一定是 3。
二、基于近邻物品的协同过滤
另一种推荐算法:基于近邻物品的协同过滤。
推荐系统会根据你过往看过的电影,从电影库中查找相似的电影推荐给你,这种方法叫做基于近邻物品的协同过滤算法(简称ItemCF)
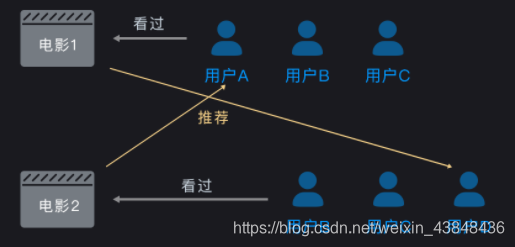
用户 A 看过电影 1,那么就给他推荐相似的电影 2;用户 D 看过电影 2,那么就给他推荐相似的电影 1。电影 1 和电影 2 相似是因为他们有着共同的观影群体(B和C)。基于近邻物品的协同过滤算法常见的推荐理由是:看了该电影的用户还看了如下电影。基于近邻物品的协同过滤算法,第一个要理解的点是近邻物品,也就是用户群体相似的物品;第二个要理解的点是协同过滤,这个前面已经讲过,核心是利用了用户行为数据。
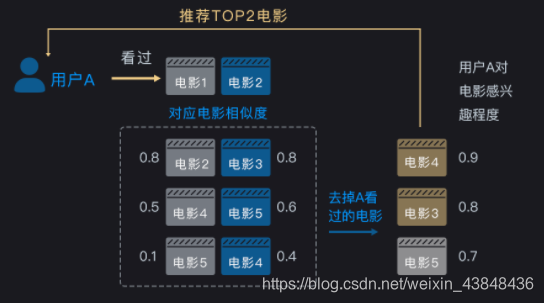
基于近邻物品的协同过滤算法是给用户推荐和他过去喜欢的电影相似的电影。具体的算法流程是:比如我们要给用户 A 推荐电影,首先要在用户 A 喜欢的电影中分别找到 K 个最相似的电影,然后再从这些电影中找到用户 A 没看过的电影推荐给 A 。
三、杰卡德相似度
前面我们讲的两种基于近邻的协同过滤算法有一个共同点,那就是计算相似度。前面我们已经提到了几种相似度的计算方法,比如欧氏距离、余弦相似性、皮尔逊相关系数。
杰卡德相似度是指两个集合的交集元素个数在并集中所占的比例。先来看一幅图片:
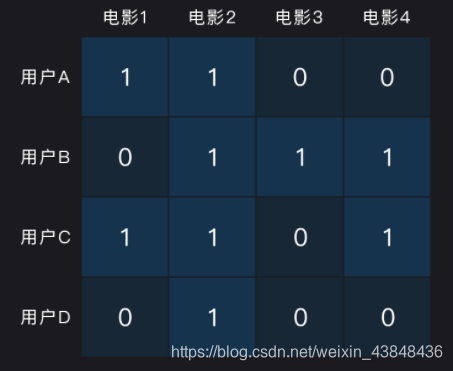
图中展现的是代表用户观影记录的行为矩阵,矩阵中的 1 表示用户看过对应的电影,0 表示没看过。据此,我们可以根据杰卡德相似度定义分别计算出用户的相似度矩阵和电影的相似度矩阵。先来看用户相似度矩阵: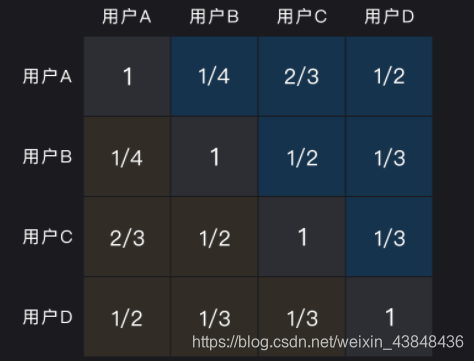

















 1994
1994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









