







源码提供
有需要的朋友可以下载补环境那部分的源码:补环境源码
前言
前不久才攻克了某房地产的瑞四,这两天跑脚本发现破解失败了,打开网址一看,好家伙,升级到瑞六了,卷的很!趁着有时间试试看能不能攻克。
难点
大家可以看看我之前的文章,虽然已经失效了,但是补环境思路是可以参考的,而且攻克瑞六一切前提和代码啥的都还是用的以前的。
爬虫逆向学习(六):补环境过某数四代
爬虫逆向学习(七):补环境动态生成某数四代后缀MmEwMD
这里提前给大家透露一下:现在升级后它还只要补全代理提示缺失的环境就能可以补成功了,相比于瑞四多检测了些环境,并没有在控制流中检测特定的像canvas、span标签这些恶心玩意,且对all、form只是简单检测
已知难点:
- 补环境所需代码构建
- 代码格式化检测
- 外链js文件代码中对方法体注入debugger
解决
这里不会从头到尾讲解补过程,毕竟只需缺啥补啥,且缺啥提示很明确,帮助大家整理好前提环境才是重点
老样子,先给脚本断点,情况浏览器内存(删除已有cookie),然后刷新页面
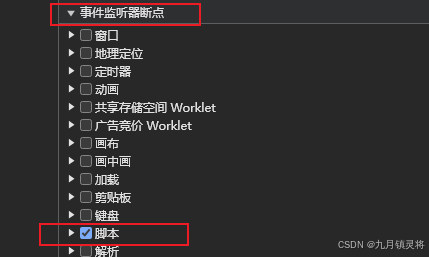
我们提取关键代码其实就是根据它出现的顺序,瑞六和瑞4相比,它没有自执行函数,而是定义_ts,也就是如下代码

再走下去就是外链js的内容了,这部分可以单独存一个文件,也可以直接放在后面,注意不要格式化复制,它的格式化检测就是在这部分代码实现的
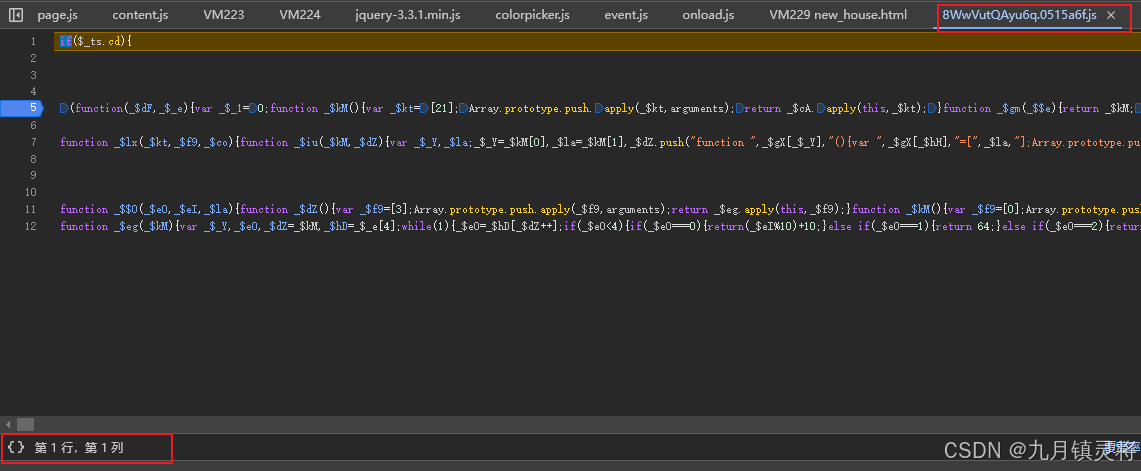
content的处理操作是一样的,最后关键代码如下,这里就可以开始补了。
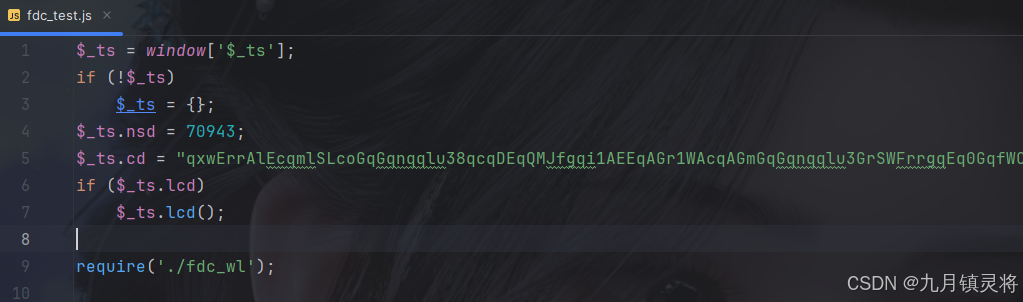
上面我们解决了难点一和二,而难点三是在给我们调试增加难度的,继续执行到VM代码处,会不断进入debugger,全部由120多处,不断循环还更多
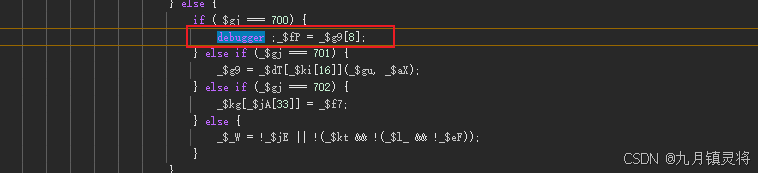
这里要处理过无限debugger
(function () {
'use strict';
window.__cr_eval = window.eval
String.prototype.replaceAll = String.prototype.replaceAll || function(string, replaced) {
return this.replace(new RegExp(string, 'g'), replaced);
};
var myeval = function (src) {
console.log(src);
return window.__cr_eval(src.replaceAll('debugger;', ';'))
}
var _myeval = myeval.bind(null)
_myeval.toString = window.__cr_eval.toString
Object.defineProperty(window, 'eval', {value: myeval})
window.setInterval=function(){};
window.setTimeout=function(){};
var _constructor = constructor;
Function.prototype.constructor = function (s) {
if (s === 'debugger') {
console.log(s);
return null;
}
return _constructor(s);
}
//去除无限debugger
Function.prototype.__constructor_back = Function.prototype.constructor;
Function.prototype.constructor = function () {
if (arguments && typeof arguments[0] === 'string') {
if ('debugger' === arguments[0]) {
return
}
}
return Function.prototype.__constructor_back.apply(this, arguments);
}
var _Function = Function;
Function = function (s) {
if (s === 'debugger') {
console.log(s);
return null;
}
return _Function(s);
}
})();
经测试,上面这部分代码处理eval没法实现,其它都可以,这里之所以没法实现eval是因为它是在外链js代码中执行的,没法被hook到(本地node环境可以过,浏览器过不了)
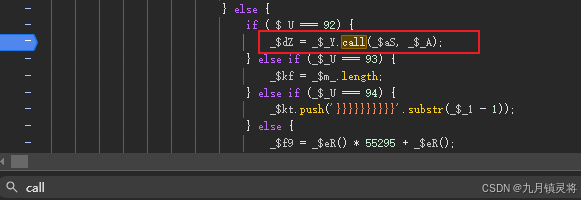
针对浏览器这种情况,我们需要定位eval.call,手动处理它的内容
如下,我们通过这种方式加上上面的代码,就能把所有的函数体debugger和时间循环debugger给绕过了,且能在hook cookie这里debugger住。
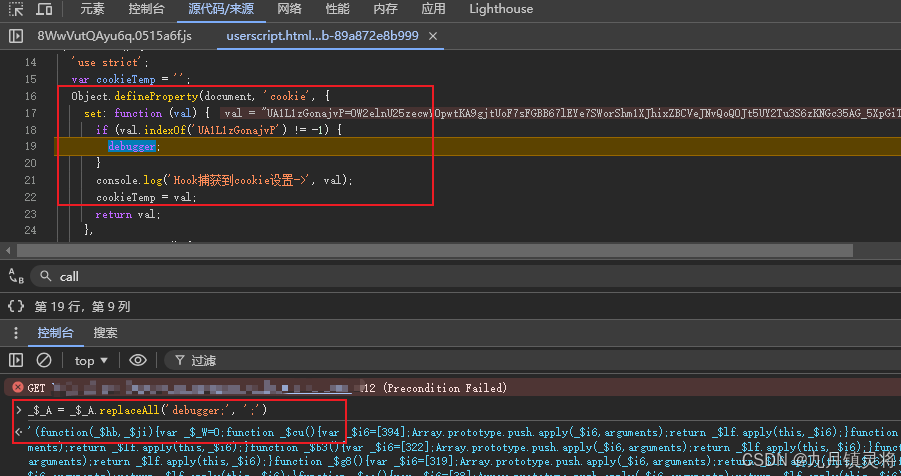
这里给大家看下我补的大致内容,具体的大家自己练练手,实在搞不定可以提问
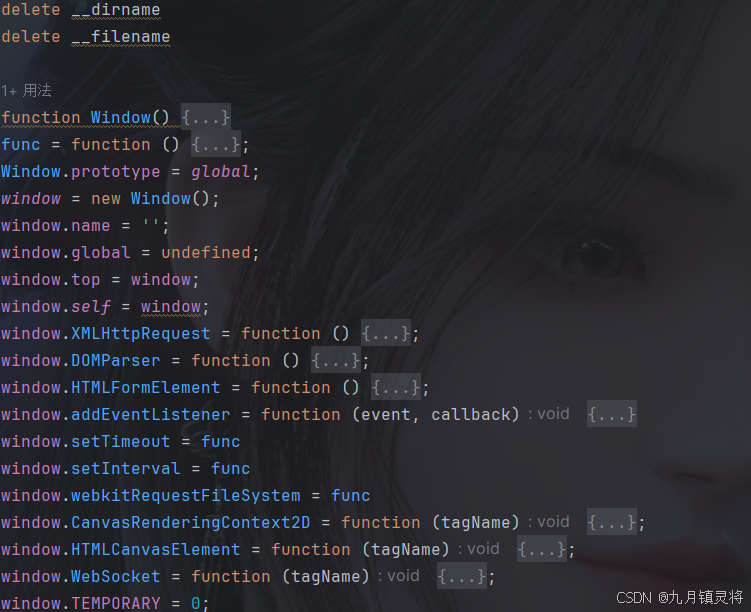
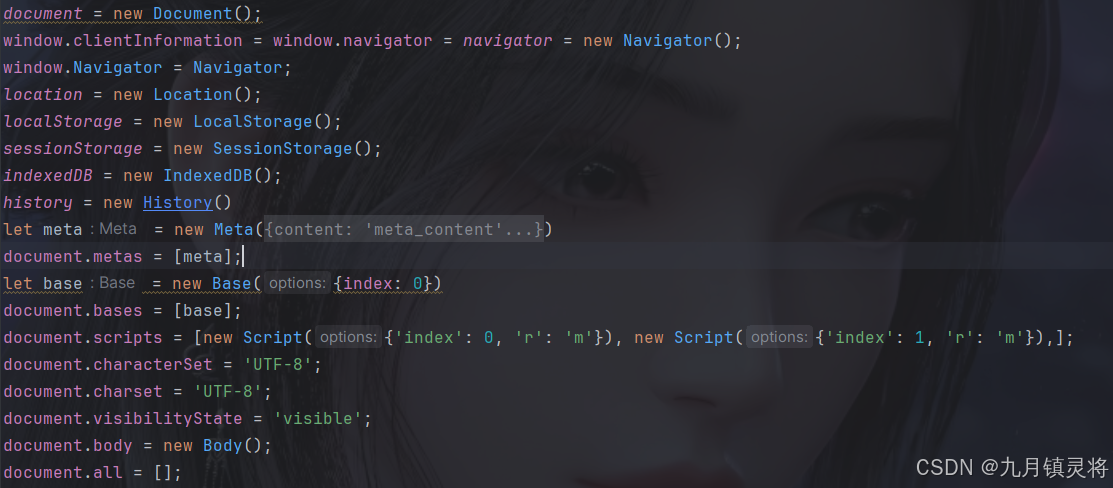
破解结果
我补处理的cookie长度是236,可以破解成功




















 5186
5186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











