







为什么要创建线程池?
项目中经常创建,启动销毁线程是非常耗时的,使用线程池去进行管理,提高程序效率。
什么是线程池?
Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池。在开发过程中,合理地使用线程池能够带来3个好处。
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是,要做到合理利用线程池,必须对其实现原理了如指掌。
java使用线程池核心走ThreadPoolExecutor类,提供了4种构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
ThreadPoolExecutor构造函数参数:
corePoolSize: 核心池的大小。 当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize 后,就会把到达的任务放到缓存队列当中
maximumPoolSize: 线程池最大线程数,它表示在线程池中最多能创建多少个线程;threadFactory:线程工厂,用于创建线程
keepAliveTime: 表示线程没有任务执行时最多保持多久时间会终止。
unit: 参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性workQueue:阻塞队列,用于存储等待执行的任务,并且只能存储调用
execute方法提交的任务。常用队列:SynchronousQueue,LinkedBlockingDeque,ArrayBlockingQueue,DelayQueue和 PriorityBlockingQueue)
handler:拒绝策略,当任务太多来不及处理时所采用的处理策略。(4种类型)
线程池的工作队列:
ArrayBlockingQueue
ArrayBlockingQueue(有界队列)是一个用数组实现的有界阻塞队列,按FIFO排序(先进先出)量。
LinkedBlockingQueue
LinkedBlockingQueue(可设置容量队列)基于链表结构的阻塞队列,按FIFO排序任务,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列,最大长度为Integer.MAX_VALUE,吞吐量通常要高于ArrayBlockingQuene; newFixedThreadPool线程池使用了这个无界的阻塞队列,如果线程获取一个任务后,任务的执行时间比较长(比如设置10秒),会导致队列的任务越积越多,导致机器内存使用不停飙升,最终导致OOM。
DelayQueue
DelayQueue(延迟队列)是一个任务定时周期的延迟执行的队列。根据指定的执行时间从小到大排序,否则根据插入到队列的先后排序。newScheduledThreadPool线程池使用了这个队列。
PriorityBlockingQueue
PriorityBlockingQueue(优先级队列)是具有优先级的无界阻塞队列;
SynchronousQueue
SynchronousQueue(同步队列)一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene,newCachedThreadPool线程池使用了这个队列。
使用线程池使用方式?
Executor分装了4种创建方式(都是ThreadPoolExecutor的构造函数):
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。底层中核心池大小为0,线程池最大线程数无限制,但是会对线程做复用,也就是回收线程,重复使用。
线程池特点:
核心线程数为0
最大线程数为Integer.MAX_VALUE
阻塞队列是SynchronousQueue
非核心线程空闲存活时间为60秒
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。它的核心池大小与最大线程数相等,重复使用创建的定长线程池,例如,定义线程池长度为3就只有这3个线程,不停地重复利用这3个,当当前线程池中线程数超出3个的话会进入阻塞队列进行等待
线程池特点:
核心线程数和最大线程数大小一样
没有所谓的非空闲时间,即keepAliveTime为0
阻塞队列为无界队列LinkedBlockingQueue
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
线程池特点
最大线程数为Integer.MAX_VALUE
阻塞队列是DelayedWorkQueue
keepAliveTime为0
scheduleAtFixedRate() :按某种速率周期执行
scheduleWithFixedDelay():在某个延迟后执行
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。底层中核心池大小,线程池最大线程数都等于1,这个线程 池可以在线程死后(或发生异常时)重新启动一个线程来替代原来的线程继续执行下去!线程池特点
核心线程数为1
最大线程数也为1
阻塞队列是LinkedBlockingQueue
keepAliveTime为0
ThreadPoolExecutor类中成员变量:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
ctl:控制线程运行状态的一个字段。同时,根据下面的几个方法runStateOf,workerCountOf,ctlOf可以看出,该字段还包含了两部分的信息:线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount),并且使用的是Integer类型,高3位保存runState,低29位保存workerCount。
COUNT_BITS:值为29的常量,在字段CAPACITY被引用计算。
CAPACITY:表示有效线程数量(workerCount)的上限,大小为 (1<<29) - 1。
下面5个变量表示的是线程的运行状态,分别是:
- RUNNING :接受新提交的任务,并且能处理阻塞队列中的任务;
- SHUTDOWN:不接受新的任务,但会执行队列中的任务。
- STOP:不接受新任务,也不处理队列中的任务,同时中断正在处理任务的线程。
- TIDYING:如果所有的任务都已终止了,workerCount (有效线程数) 为0,线程池进入该状态后会调用 terminated() 方法进入TERMINATED 状态。
- TERMINATED:terminated( ) 方法执行完毕。
线程池合理配置---CPU密集,IO密集。
CPU密集型时,任务可以少配置线程数,大概和机器的cpu核数相当,这样可以使得每个线程都在执行任务(FixedThreadPool 适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务)
IO密集型时,大部分线程都阻塞,故需要多配置线程数,2*cpu核数
四种拒绝策略
AbortPolicy(抛出一个异常,默认的)
DiscardPolicy(直接丢弃任务)
DiscardOldestPolicy(丢弃队列里最老的任务,将当前这个任务继续提交给线程池)
CallerRunsPolicy(交给线程池调用所在的线程进行处理)
提交一个任务到线程池中,线程池的处理流程如下:
-
提交一个任务,线程池里存活的核心线程数小于线程数corePoolSize时,线程池会创建一个核心线程去处理提交的任务。
-
如果线程池核心线程数已满,即线程数已经等于corePoolSize,一个新提交的任务,会被放进任务队列workQueue排队等待执行。
-
当线程池里面存活的线程数已经等于corePoolSize了,并且任务队列workQueue也满,判断线程数是否达到maximumPoolSize,即最大线程数是否已满,如果没到达,创建一个非核心线程执行提交的任务。
-
如果当前的线程数达到了maximumPoolSize,还有新的任务过来的话,直接采用拒绝策略处理。
线程池原理图:

线程池处理异常(4种):
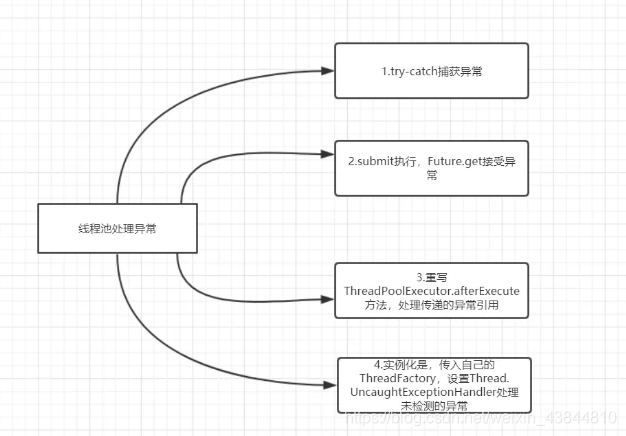
第三种:为工作者线程设置UncaughtExceptionHandler,在uncaughtException方法中处理异常的方式:
ExecutorService threadPool = Executors.newFixedThreadPool(1, r -> {
Thread t = new Thread(r);
t.setUncaughtExceptionHandler(
(t1, e) -> {
System.out.println(t1.getName() + "线程抛出的异常"+e);
});
return t;
});
threadPool.execute(()->{
Object object = null;
System.out.print("result## " + object.toString());
});
第四种:重写ThreadPoolExecutor的afterExecute方法,处理传递的异常引用
class ExtendedExecutor extends ThreadPoolExecutor {
// 这可是jdk文档里面给的例子。。
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
if (t == null && r instanceof Future<?>) {
try {
Object result = ((Future<?>) r).get();
} catch (CancellationException ce) {
t = ce;
} catch (ExecutionException ee) {
t = ee.getCause();
} catch (InterruptedException ie) {
Thread.currentThread().interrupt(); // ignore/reset
}
}
if (t != null)
System.out.println(t);
}
}}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









