







目录
在当今互联网时代,垃圾邮件不仅令人厌烦,还可能带来安全隐患。为了有效过滤垃圾邮件,我们可以采用两种主要方法:传统的编程技术和机器学习技术。本文将探讨这两种方法的特点,并说明为什么机器学习在处理复杂问题时更具优势。
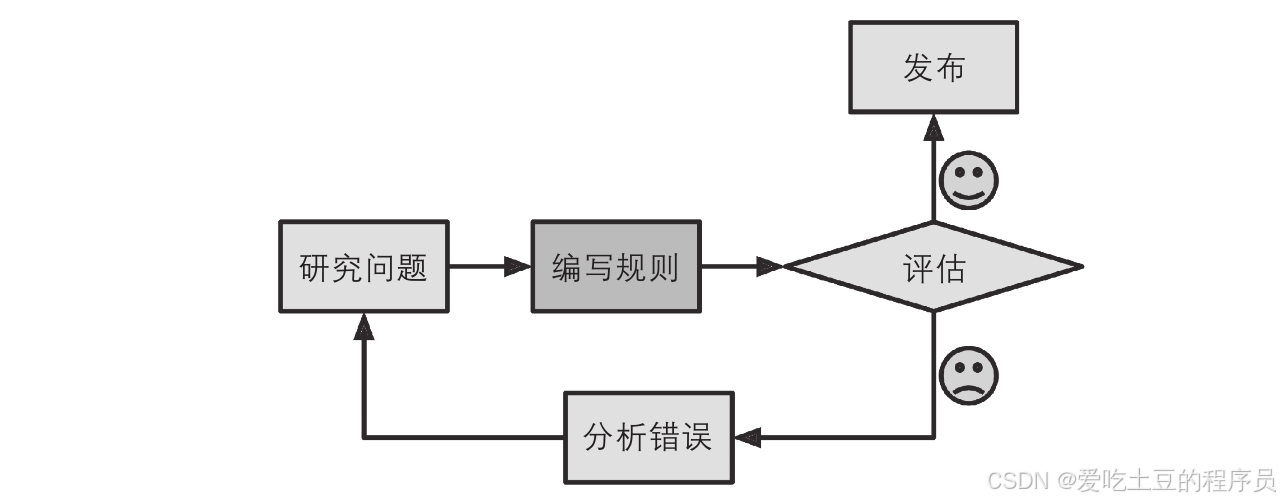
传统编程方法
步骤1:分析垃圾邮件特征
首先,我们需要仔细查看垃圾邮件的样本,找出其中的常见特征。例如,我们可能会注意到一些词或短语(如“4U”、“credit card”、“free”、“amazing”)在邮件主题中频繁出现。此外,还有一些固定的模式可能出现在邮件的发件人名字、正文和其他部分。
步骤2:编写检测算法
针对观察到的每个模式,我们需要编写相应的检测算法。如果检测到某个特定的规律,程序就会将邮件标记为垃圾邮件。例如,如果邮件主题中包含“4U”,则将其标记为垃圾邮件。
步骤3:测试和迭代
接下来,我们需要对程序进行测试,看看它是否能够有效地过滤垃圾邮件。如果效果不佳,我们需要回到第一步,继续分析更多的垃圾邮件样本,然后改进我们的检测算法。这个过程可能会非常繁琐,最终导致程序变得非常复杂且难以维护。
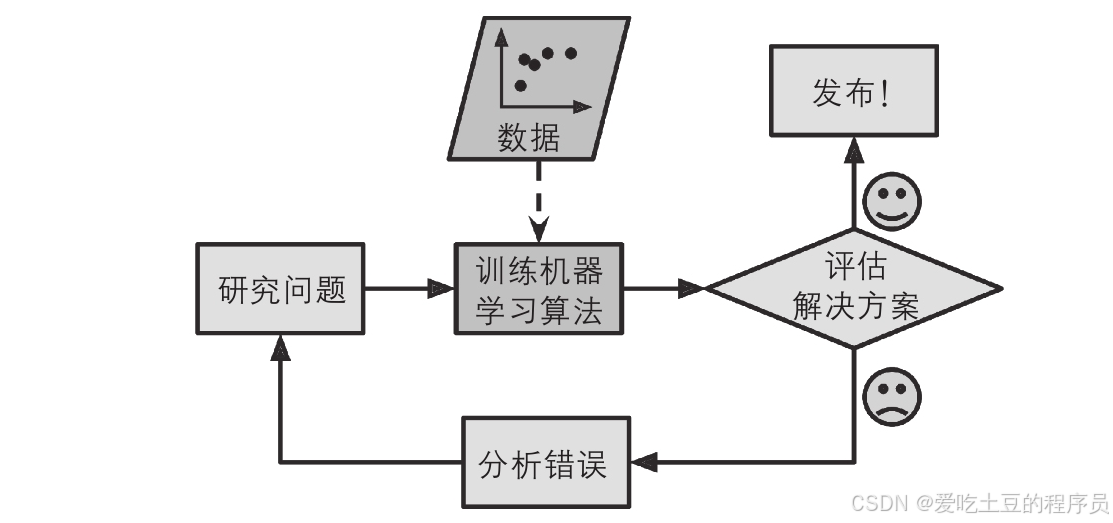
机器学习方法
自动学习垃圾邮件特征
与传统编程方法不同,基于机器学习的垃圾邮件过滤器会自动学习词和短语,这些词和短语是垃圾邮件的预测因素。通过与非垃圾邮件进行比较,机器学习算法可以检测出垃圾邮件中反复出现的词语模式。
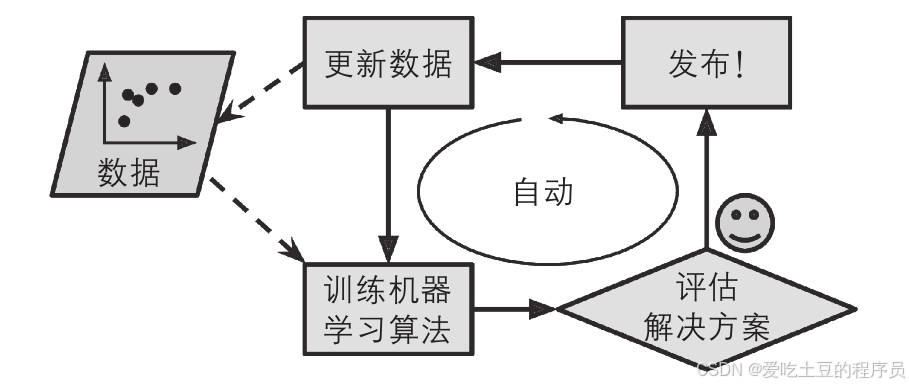
动态适应变化
垃圾邮件的发送者会不断改变他们的策略。例如,如果他们发现所有包含“4U”的邮件都被屏蔽了,他们可能会转而使用“for U”。使用传统方法的垃圾邮件过滤器需要不断更新规则来应对这种变化。而基于机器学习的过滤器则会自动注意到“for U”在用户手动标记的垃圾邮件中频繁出现,从而自动标记垃圾邮件而无需人工干预。
复杂问题的处理能力
机器学习特别擅长处理那些传统方法难以解决的复杂问题。例如,语音识别是一个典型的例子。假设你想写一个可以识别“one”和“two”的简单程序。你可能会注意到“two”的起始是一个高音(“T”),因此会编写一个测量高音强度的算法。然而,这种方法很难推广到所有语音识别场景,因为人们的发音、环境和使用的词汇都有很大差异。相比之下,机器学习算法可以通过大量单词录音自我学习,从而更好地处理这些复杂情况。
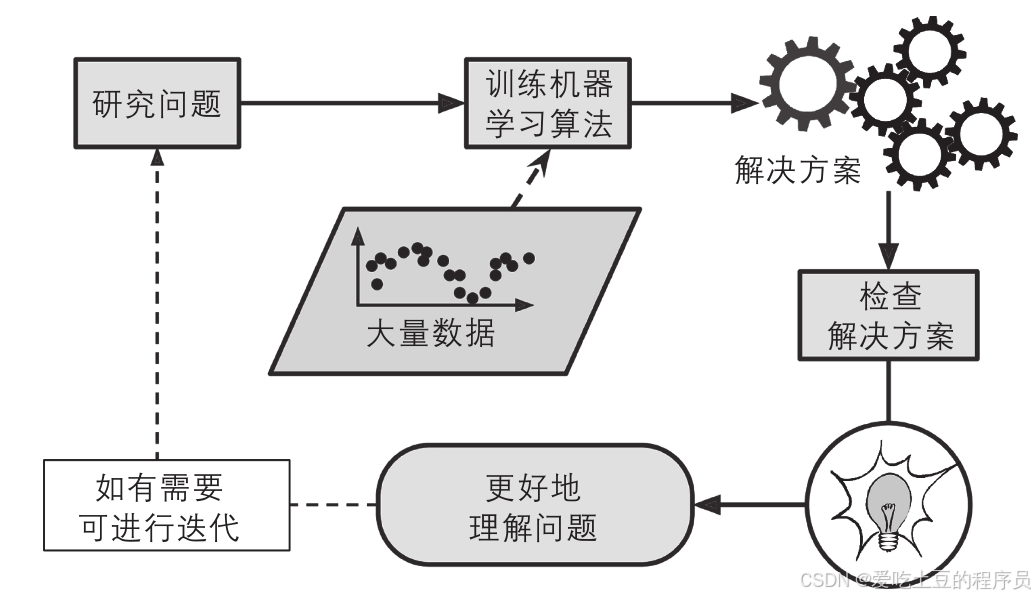
发现隐藏规律
机器学习不仅可以帮助我们过滤垃圾邮件,还可以帮助我们发现数据中的隐藏规律。例如,经过充分训练的垃圾邮件过滤器可以列出垃圾邮件预测器的单词和单词组合。这些发现有时会揭示不引人关注的关联或新趋势,从而帮助我们更好地理解问题。
结论
虽然传统编程方法在处理简单问题时仍然有效,但在面对复杂和动态变化的问题时,机器学习方法展现出更强的适应性和精确度。通过自动学习和动态适应,机器学习不仅简化了开发流程,还提高了系统的性能。因此,对于垃圾邮件过滤等复杂任务,机器学习无疑是更好的选择。
参考:《机器学习实战》



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









