






背景
spark版本2.4.6
在spark sql中shuffle的partition数量由spark.sql.shuffle.partitions决定。
spark.sql.shuffle.partitions默认是200
shuffle并行度定死某一个数值(如200),会存在一些问题。因为每次shuffle的数据量是不确定。当数据量小的时候,每一个shuffle的task处理的数据量太少(如下图)。当数据量大的时候,每一个shuffle处理的数量又太多。所以需要根据shuffle前文件大小来动态调节shuffle的并行度。
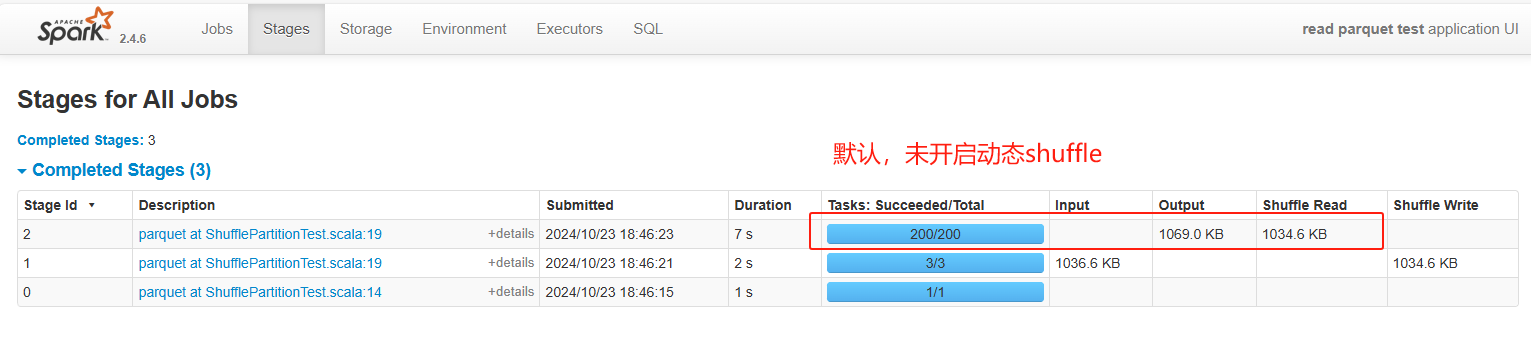
动态shuffle partition
主要参数有三个:
- spark.sql.adaptive.enabled:开启adaptive功能,默认false
- spark.sql.adaptive.shuffle.targetPostShuffleInputSize:shuffle单个partition输入文件大小,默认64M
- spark.sql.adaptive.minNumPostShufflePartitions:shuffle的partition最小数量,默认-1
开启动态shuffle,需要设置spark.sql.adaptive.enabled=true,开启后shuffle的并行度变成了有200变成了1
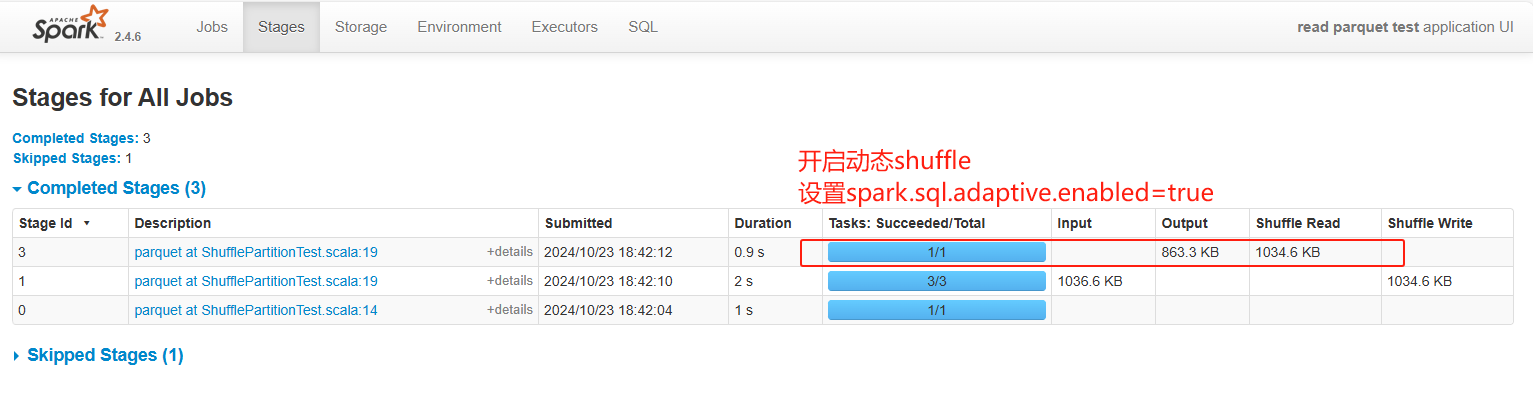
可以通过spark.sql.adaptive.shuffle.targetPostShuffleInputSize来调整shuffle的并行度。如下图spark.sql.adaptive.shuffle.targetPostShuffleInputSize设置为500kb,shuffle的数据大小为1034.6kb。并行度=ceil(1034.6/500)=3

也可以通过spark.sql.adaptive.minNumPostShufflePartitions调整shuffle并行度。如下图设置spark.sql.adaptive.minNumPostShufflePartitions为10,shuffle并行度为11(满足最小为10)

shuffle并行度确定流程(源码)
暂时无法在飞书文档外展示此内容
举例说明:

源码在ExchangeCoordinator类中
map输出文件大小为1034.6KB()
spark.sql.adaptive.enabled=true
spark.sql.adaptive.shuffle.targetPostShuffleInputSize=500KB
spark.sql.adaptive.minNumPostShufflePartitions=10
文件大小totalPostShuffleInputSize=1112175,除以10,得到maxPostShuffleInputSize=111218,跟500KB取最小值,targetPostShuffleInputSize最终等于111218

map输出的文件已经按照默认分区数200进行了分组。mapOutputStatistics中是map task生成文件中200个分区对应的大小。遍历200个分区,从mapOutputStatistics中获取全部map输出文件中对应partition的数据大小,累加直到targetPostShuffleInputSize生成一个合并分区。最后写入partitionStartIndices中。
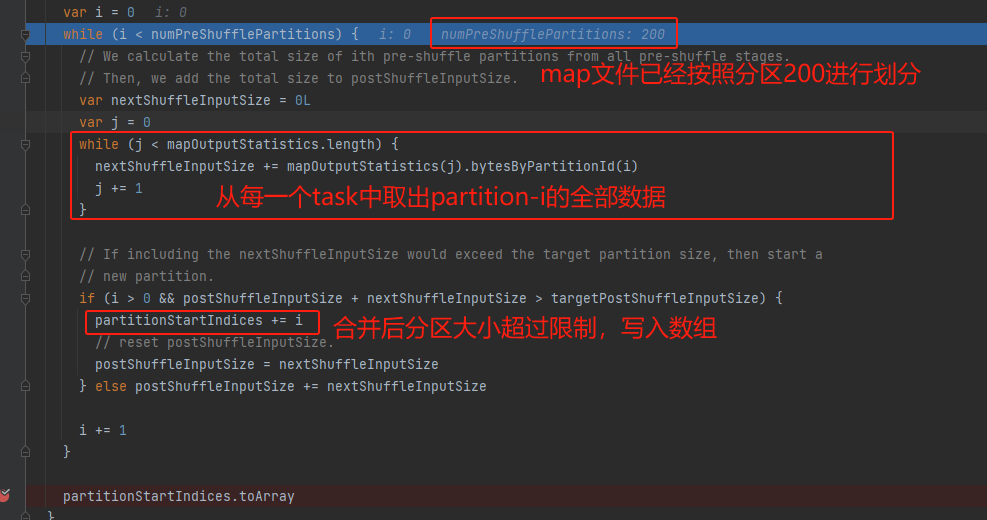
partitionStartIndices中保存的是原始200分区对应的索引值,表示合并后partition的起始位置。
最后将200个分区合并成了11个分区。
分别对应处理
0-19 20-38 39-57 58-77 78-97 98-117 118-136 137-154 156-175 176-194 195-200


















 2675
2675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









