





 本文深入探讨Apache Flink中的时间语义、状态管理和检查点技术。解析EventTime、ProcessingTime和IngestionTime的区别,阐述状态在流式计算中的作用,以及检查点和Savepoint机制如何保障容错和应用升级。
本文深入探讨Apache Flink中的时间语义、状态管理和检查点技术。解析EventTime、ProcessingTime和IngestionTime的区别,阐述状态在流式计算中的作用,以及检查点和Savepoint机制如何保障容错和应用升级。
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。主要分享Flink时间语义、状态与检查点等核心概念
在流处理中,时间是一个非常核心的概念,是整个系统的基石。比如,我们经常会遇到这样的需求:给定一个时间窗口,比如一个小时,统计时间窗口的内数据指标。那如何界定哪些数据将进入这个窗口呢?在窗口的定义之前,首先需要确定一个应用使用什么样的时间语义。
分为: Event Time、Processing Time和 Ingestion Time
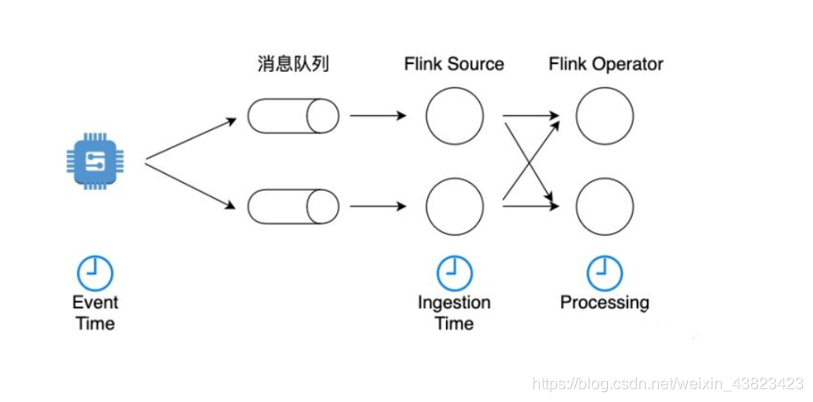
Event Time
Event Time指的是数据流中每个元素或者每个事件自带的时间属性,一般是事件发生的时间 。一个较早发生的事件因为延迟可能较晚到达,因此使用Event Time意味着事件到达有可能是乱序的。
在实际应用中,当涉及到对事件按照时间窗口进行统计时,Flink会将窗口内的事件缓存下来,直到接收到一个Watermark,以确认不会有更晚数据的到达。Watermark意味着在一个时间窗口下,Flink会等待一个有限的时间,这在一定程度上降低了计算结果的绝对准确性,而且增加了系统的延迟。在流处理领域,比起其他几种时间语义,使用Event Time的好处是某个事件的时间是确定的,这样能够保证计算结果在一定程度上的可预测性。
使用Event Time的优势是结果的可预测性,缺点是缓存较大,增加了延迟,且调试和定位问题更复杂
Processing Time
对于某个算子来说,Processing Time指算子使用当前机器的系统时钟来定义时间。在Processing Time的时间窗口场景下,无论事件什么时候发生,只要该事件在某个时间段达到了某个算子,就会被归结到该窗口下,不需要Watermark机制。
Processing Time只依赖当前执行机器的系统时钟,不需要依赖Watermark,无需缓存。Processing Time是实现起来非常简单也是延迟最小的一种时间语义。
Ingestion Time 是事件到达Flink Souce的时间。从Source到下游各个算啊自中间可能有很多计算环节,任何一个算子的处理速度快慢可能影响到下游算子的Processing Time 。而Ingestion Time定义的是数据流最早进入Flink的时间,因此不会被算子处理速度影响 。
Ingestion Time通常是Event Time和Processing Time之间的一个折中方案。比起Event Time,Ingestion Time可以不需要设置复杂的Watermark,因此也不需要太多缓存,延迟较低。比起Processing Time,Ingestion Time的时间是Souce赋值的,一个事件在整个处理过程从头至尾都使用这个时间,而且后续算子不受前序算子处理速度的影响,计算结果相对准确一些,但计算成本稍高。
Watermark 水位线
如果我们要使用Event Time 语义 ,一下两项配置缺一不可:第一,使用一个时间戳为数据流中每个事件的Event Time赋值;第二: 生成Watermark
实际上,Event Time 是每个事件的元数据,Flink并不知道每个事件的发生时间是什么,我们必须要为每个事件的Event Time赋值一个时间戳 。关于时间戳,包括Flink在内的绝大多数系统都支持Unix时间戳系统(Unix time或Unix epoch)。Unix时间戳系统以1970-01-01 00:00:00.000 为起始点,其他时间记为距离该起始时间的整数差值,一般是毫秒(millisecond)精度。
有了Event Time时间戳,我们还必须生成Watermark 。Watermark 是flink插入到数据流中的一个特殊的数据结构,它包含一个时间戳,并假设后续不会有小于该时间戳的数据。下图展示了一个乱序数据流,其中方框是单个事件,方框的数字是其对应的Event Time的时间戳,圆圈为watermark,圆圈中的数字为Watermark对应的时间戳。
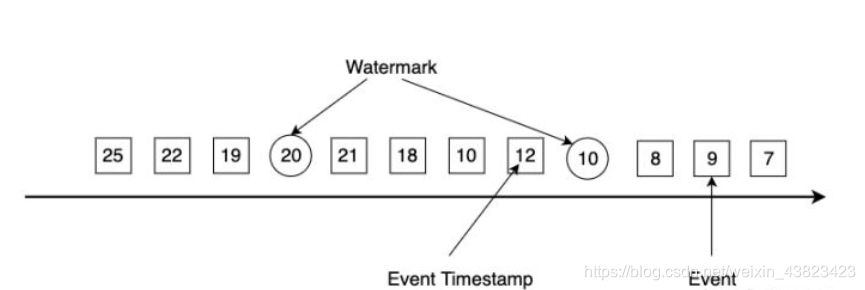
- Watermark与事件的时间戳紧密相关。一个时间戳为T的Watermark假设后续到达的事件时间戳都大于T。
- 假如Flink算子接收到一个违背上述规则的事件,该事件将被认定为迟到数据,如上图中时间戳为19的事件比Watermark(20)更晚到达。Flink提供了一些其他机制来处理迟到数据。
- Watermark时间戳必须单调递增,以保证时间不会倒流。
- Watermark机制允许用户来控制准确度和延迟。Watermark设置得与事件时间戳相距紧凑,会产生不少迟到数据,影响计算结果的准确度,整个应用的延迟很低;Watermark设置得非常宽松,准确度能够得到提升,但应用的延迟较高,因为Flink必须等待更长的时间才进行计算。
2、状态与检查点
状态
状态是流式计算特有的概念。比如计算词频的例子,要统计实时数据流一分钟内的单词词频,一方面要处理每一瞬间新流入的数据,另一方面要保存之前一分钟内已经进入系统的单词词频。再举一个告警的例子,当系统在监听到“高温”事件后10分钟内又监听到“冒烟”的事件,系统必须及时报警,系统必须把“高温”的事件作为状态记录下来,并判断这个状态下十分钟内是否有“冒烟”事件。
状态可以是当前所处理事件的位置偏移(Offset)、一个时间窗口内的某种输入数据、或与具体作业有关的自定义变量。
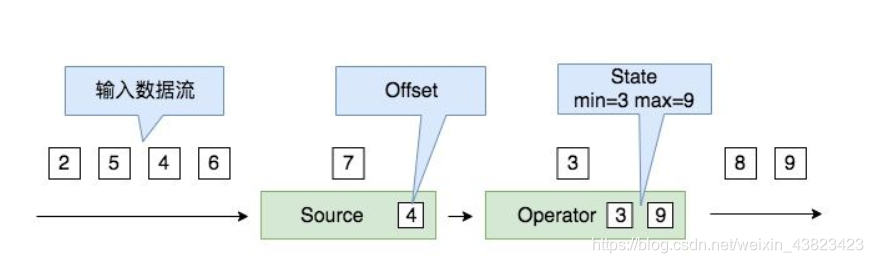
如上图所示的应用,我们计算一个实时数据流的最大值与最小值,这个作业的状态包括当前处理的位置偏移、已处理过的最大值和最小值等变量信息。
Checkpoint
由于分布式大数据系统运行在多台机器上,因此经常会遇到某台机器宕机、网络出现延迟抖动等问题,一旦出现宕机等问题,该机器的状态以及相应的计算会丢失,因此需要一种恢复机制来应对这些潜在问题。
Flink 使用检查点(Checkpoint)技术来做失败恢复。检查点一般是将状态数据生成快照(Snapshot),持久化存储起来,一旦发生意外,Flink主动重启应用,并从最近的快照中恢复,再继续处理新流入数据。
Flink 采用的是一种一致性检查点(Consistent Checkpoint)技术,他可以将分布在多台机器上所有状态都记录下来,并提供了Exactly-Once的投递保障,其背后是使用了Chandy-Lamport算法,将本地的状态数据存储到一个存储空间上,并在故障恢复时在多态机器上恢复当前状态。
状态后端
1、内存
这三种存储方式又被称为状态后端(State Backend)
使用这种方式,Flink会将状态维护在Java堆上。众所周知,内存的访问读写速度最快;其缺点也显而易见,单台机器的内存空间有限,不适合存储大数据了的状态信息。一般在本地开发调试时或者状态非常小的应用场景下使用内存这种方式。
如不做特殊配置,Flink默认使用内存作为Backend 。
文件系统包括:本地文件系统和分布式文件系统,如HDFS ,S3
当选择使用文件系统作为后端时,正在计算的数据会被咱存在TaskManager的内存中。Checkpoint时,此后端会将状态写入配置的文件系统中,同时会在JobManager的内存中或者在Zookeeper中存储极少的元数据
RocksDB是一种嵌入式键值数据库,由Facebook开发。使用RocksDB作为后端时,Flink会将实时处理中的数据使用RocksDB存储在本地磁盘上。Checkpoint时,整个RocksDB数据库会被存储到配置的文件系统中,同时Flink会将极少的元数据存储在JobManager的内存中,或者在Zookeeper中(高可用情况)。
RocksDB支持增量Checkpoint,即只对修改的数据做备份,因此非常适合超大状态的场景。
Savepoint
在容错上,除了checkpoint ,flink还提供了savepoint机制,从名称和实现上,这两个机制都及其相似,甚至Savepoint机制会使用checkpoint机制的数据,但实际上这两个机制的定位不同。
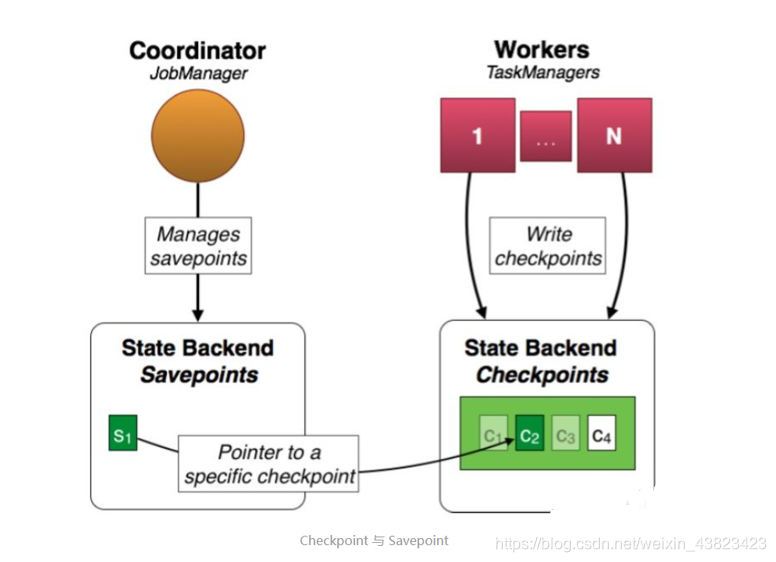
Checkpoint是Flink定时触发并自动执行的容错恢复机制,以应对各种意外情况;Savepoint是一种特殊的Checkpoint,它需要编程人员手动介入。比如,用户更新某个应用的代码,需要先停掉该应用并重启,这时就需要使用Savepoint。

















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









