







 本文深入探讨了线程、进程和协程在Python中的应用,包括它们的创建、管理和比较。详细解析了使用队列进行进程间通信的方法,以及协程通过gevent库实现的高效并发特性。
本文深入探讨了线程、进程和协程在Python中的应用,包括它们的创建、管理和比较。详细解析了使用队列进行进程间通信的方法,以及协程通过gevent库实现的高效并发特性。
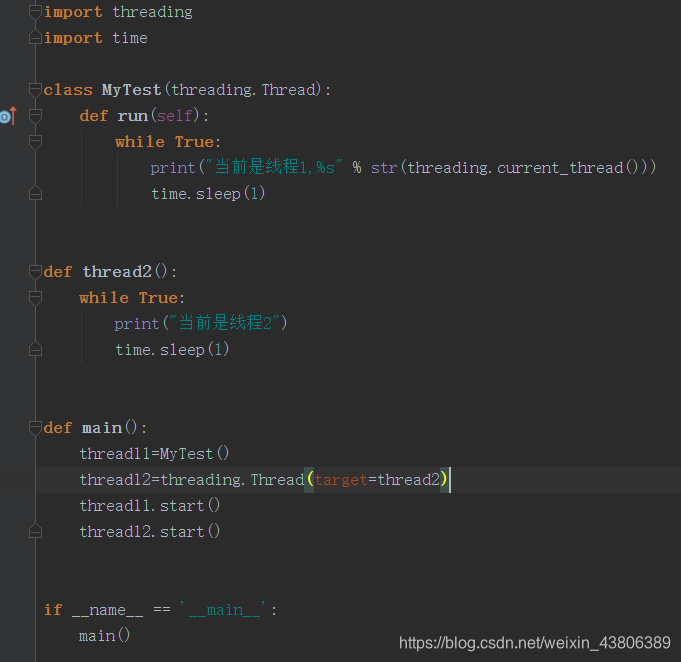
线程
线程是在threading包下的,线程的全局变量是共享的
创建线程有多种方法,下面代码列举2种
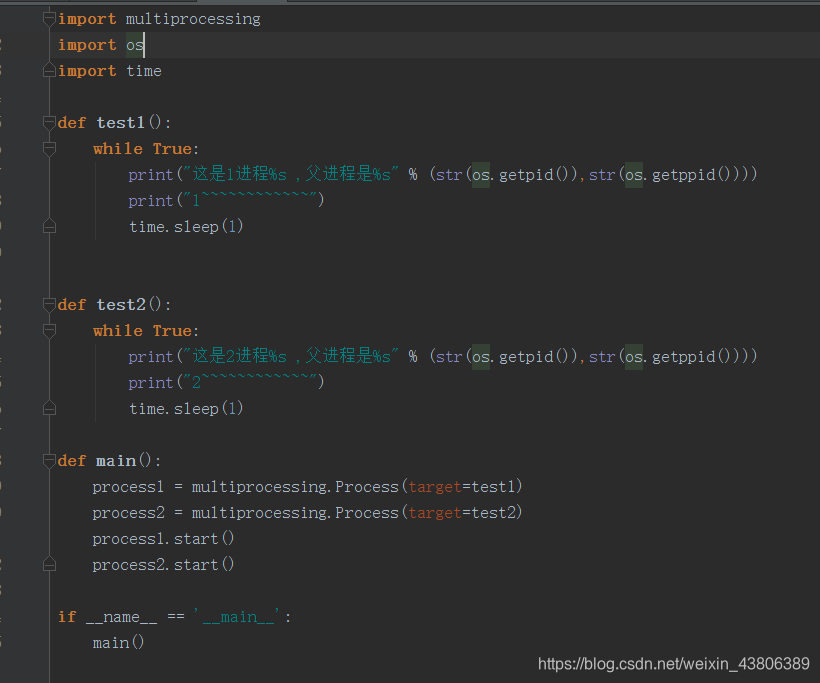
进程
进程是在multiprocessing包下的,线程的全局变量不是共享的
队列
由于进程中全局变量不是共享的,所以需要用队列去同步。
队列和进程是同一个包下。
使用队列同步数据:
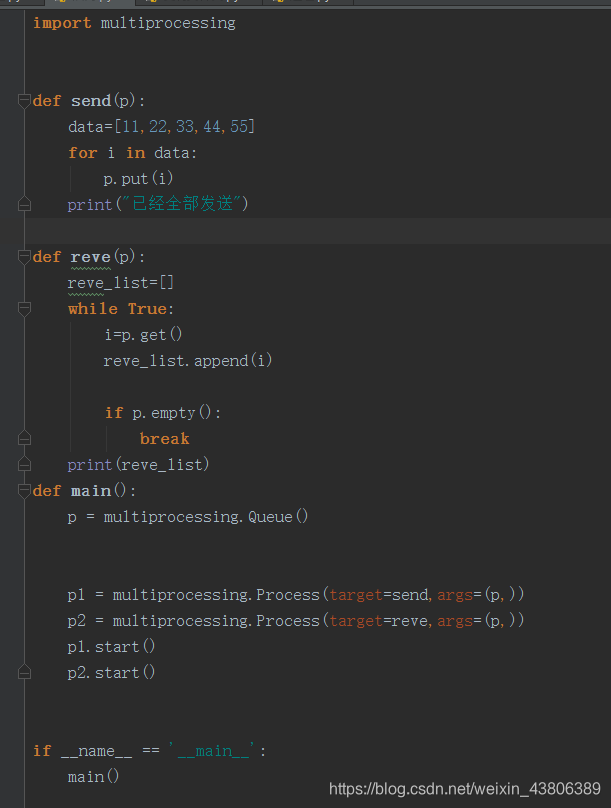
队列中的方法:
get() 取数据 遵从先进先出
put() 放数据
empty() 队列是否为空
full() 队列是否放满
在队列中使用get方法,队列中没数据时,会造成堵塞,等待队列中有数据才会继续执行,put方法同理

进程池
进程池和进程属于中一个包下
下面是一个简单的文件夹复制功能
import multiprocessing
import os
def cory_file(cory_name,new_name,old_name,q):#文件名,新文件夹,旧文件夹
# 读取文件
old_f = open(old_name+"/"+cory_name,"rb")
content=old_f.read()
old_f.close()
# 写入文件
new_f = open(new_name+"/"+cory_name,"wb")
new_f.write(content)
new_f.close()
# 完成一个文件放入队列
q.put(cory_name)
def main():
# 输入需要复制的文件夹
old_name = input("请输入需要复制的文件路径")
# 创建新的文件夹
try:
new_name = old_name + "复件"
os.mkdir(new_name)
except:
pass
#查询文件夹下所有文件
cory_names=os.listdir(old_name)
p = multiprocessing.Pool(2)
q = multiprocessing.Manager().Queue(3)
#使用线程池执行文件复制
for cory_name in cory_names:
p.apply_async(cory_file,args=(cory_name,new_name,old_name,q))
p.close()
# p.join()
#进度条功能
all_size = len(cory_names)
cory_size = []
count = 0
while True:
file_name = q.get()
count +=1
cory_size.append(file_name)
print("\r已经完成:%2.f %%"%(count*100/all_size),end="")
if count>=all_size:
break
print()
if __name__ == '__main__':
main()
协程
协程可以用yield,greenlet,gevent实现,其中greenlet是基于yield的封装,gevent是基于greenlet的封装,这里主要分享gevent。
协程的特点:当程序遇到需要耗时或者阻塞的操作,就会去并发执行其他代码
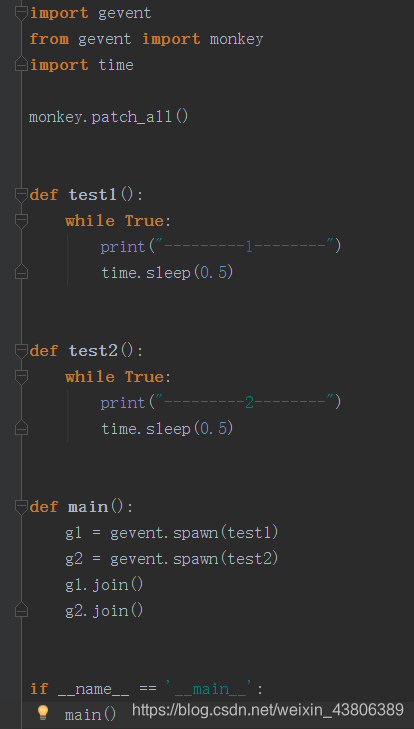
显然这样代码比较繁琐,如果需要100个协程,那就需要100次join。下面分享一个下载图片的小程序
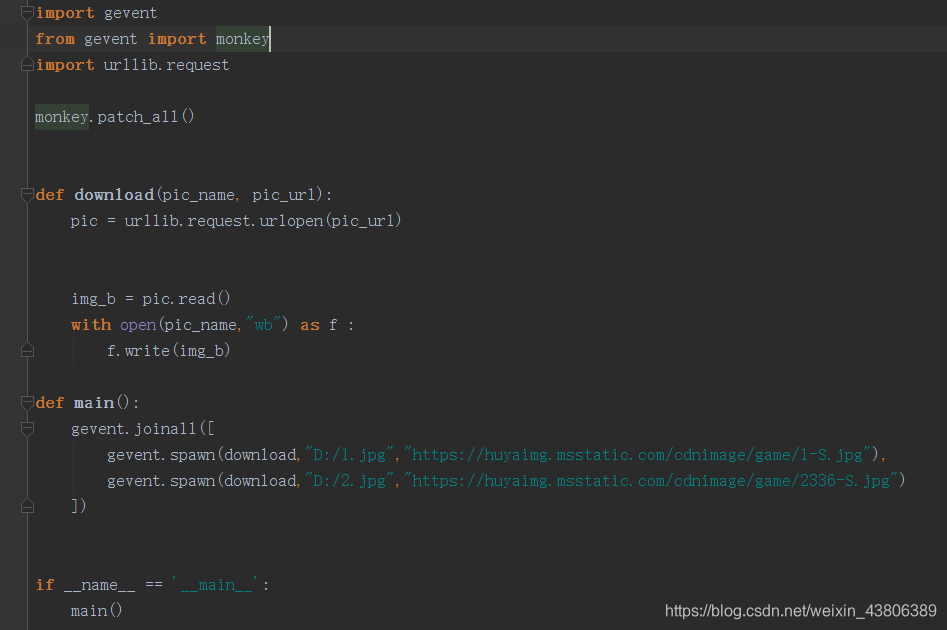
使用gevent.joinall方法同时执行多个协程
线程,进程,协程比较
进程切换需要消耗的资源最大,效率很低
线程切换需要的资源一般,效率一般(不考虑GIL的情况)
协程切换需要的资源小,效率很高
协程一定是并发执行的,线程和进程根据cpu核数性能不同,有可能是并行的

















 2568
2568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









