






 本文深入探讨了数组和链表两种基本数据结构的特性,包括它们的定义、操作时间复杂度对比、应用场景以及优缺点分析。特别关注了数组的连续内存空间特性与链表的灵活性,同时提供了链表反转、查找中间元素和环检测的具体实现。
本文深入探讨了数组和链表两种基本数据结构的特性,包括它们的定义、操作时间复杂度对比、应用场景以及优缺点分析。特别关注了数组的连续内存空间特性与链表的灵活性,同时提供了链表反转、查找中间元素和环检测的具体实现。
数组
概念:数组的本质是固定大小的连续的内存空间,并且这片连续的内存空间又被分割成等长的小空间。它最主要的特点是随机访问。
- 数组的长度是固定的
- 数组只能存储同一种数据类型的元素
- 在Java中只有一维数组的内存空间是连续,多维数组的内存空间不一定连续。
为什么数组的索引是一般都是从0开始的呢?
- 假设索引不是从0开始的,而是从1开始的,那么我们有两种处理方式:
- 寻址公式变为: i_address = base_address + (i – 1) * type_length
- 浪费开头的一个内存空间,寻址公式不变。
- 在计算机发展的初期,不管是CPU资源,还是内存资源都极为宝贵,所以在设计编程语言的时候,索引就从0开始了,而我们也一直延续了下来。
为什么数组的效率比链表高?
-
计算机中的CPU、内存、IO设备之间传输速率有很大差异
-
CPU与内存之间
a.高速缓存(cache预存)
b.编译器的指令重排序:在编译阶段对没有依赖关系的代码排序,更好利用CPU,且最后会保证结果和顺序执行一致 -
内存和IO之间:缓存:将磁盘上的数据缓存在内存
-
CPU和IO:中断技术
数组的基本操作:增删快,查找慢
添加
- 最好情况:O(1)
- 最坏情况:移动n个元素,O(n)
- 平均情况:移动 n/2 个元素,O(n)
删除
- 最好情况:O(1)
- 最坏情况:移动n-1个元素,O(n)
- 平均情况:移动(n-1)/2个元素,O(n)
查找
- a. 根据索引查找元素:O(1)
- b. 查找数组中与特定值相等的元素 ①大小无序:O(n) ②大小有序:O(log2n)
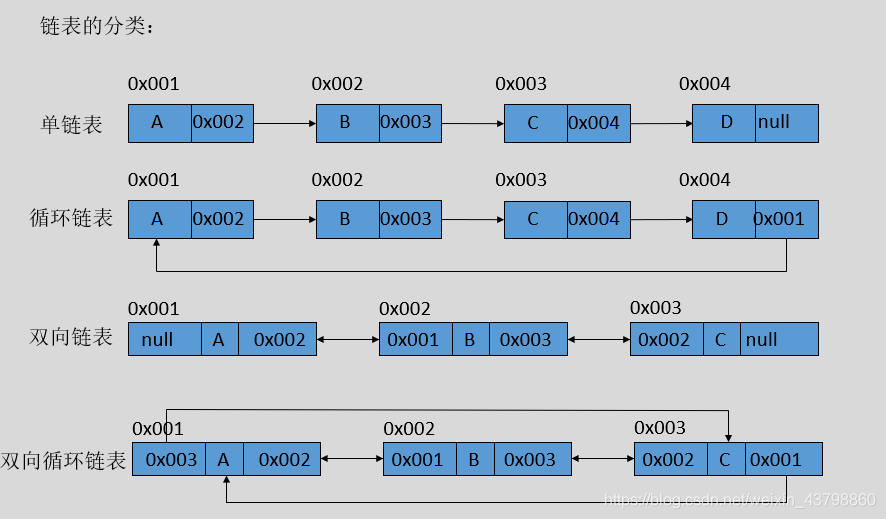
链表
public class Node {
int value;
Node next;
public Node(int value) {
this.value = value;
}
public Node(int value, Node next) {
this.value = value;
this.next = next;
}
@Override
public String toString() {
return "Node{" +
"value=" + value +
'}';
}
}
缓存是一种用空间换取时间的技术。
内存大小是有限的,所以缓存不能无限大。那么当缓存满的时候,再向缓存中添加数据,该怎么办呢?
缓存淘汰策略:
- FIFO (First In First Out)
- LFU (Least Frequently Used)
- LRU(Least Recently Used)
LRU的链表实现
添加 (认为尾节点是最近最少使用的数据)
a. 如果缓存中已经存在该数据 :删除该结点,添加到头结点
b. 如果缓存中不存在该数据 :
- 缓存没满 添加到头结点
- 缓存满了 删除尾节点, 在头结点添加
链表的练习
1.求链表的中间元素
求单链表的中间元素
示例1:
输入:1 --> 2 --> 3
输出: 2
示例2:
输入:1 --> 2 --> 3 --> 4
输出:2
思路:
如果是数组,我们可以怎么求中间元素. arr[(arr.length - 1)/2]
a. 求链表的长度
b. 从头开始遍历链表,并计数
public class Ex1 {
public static int middleElement(Node head) {
// 求链表的长度
int length = 0;
Node x = head;
while (x != null) {
length++;
x = x.next;
}
// 计算中间元素的索引
int index = (length - 1) / 2;
// 从头开始遍历链表,并计数
int i = 0;
x = head;
while (i < index) {
x = x.next;
i++;
}
return x.value;
}
public static void main(String[] args) {
// 1 --> 2 --> 3 --> 4
Node head = new Node(4);
head = new Node(3, head);
head = new Node(2, head);
head = new Node(1, head);
System.out.println(middleElement(head));
}
}
2.判断链表中是否有环
判断单链表中是否有环
思路1:一刀切
给定一个阈值100ms
如果程序运行时间超过10ms, 有环, 否则无环。
public class Ex2 {
思路2:迷雾森林
将经过的结点做标记。Collection visited.
遍历链表:
判断当前结点是否在visited集合中存在。contains
存在:返回true。
不存在:遍历下一个结点。
遍历结束:返回false。
/*
时间复杂度:O(n^2) --> O(n)
空间复杂度:O(n)
*/
public static boolean hasCircle(Node head) {
// Collection visited = new ArrayList(); // HashSet的查找时间复杂度为O(1)
Collection visited = new HashSet();
Node x = head;
while (x != null) {
if (visited.contains(x)) return true;
// 做标记
visited.add(x);
x = x.next;
}
return false;
}
思路3:跑道(快慢指针)
1. 快慢指针都指向头结点,慢指针每次走一步, 快指针每次走两步。
2. 如果快指针走到终点,说明无环
3. 否则快慢指针一定会再次相遇, 说明有环。
/*
时间复杂度:假设环外的结点有a个,环内的结点有r个
最好情况:O(a)
最坏情况:O(a + r)
平均情况:O(a + r/2)
空间复杂度:O(1)
*/
public static boolean hasCircle(Node head) {
Node slow = head;
Node fast = head;
do {
// 判断快指针是否走到了终点 (短路原则)
if (fast == null || fast.next == null) return false;
slow = slow.next;
fast = fast.next.next;
} while (slow != fast);
return true;
}
public static void main(String[] args) {
// 1 --> 2 --> 3 --> 4
/*Node head = new Node(4);
head = new Node(3, head);
head = new Node(2, head);
head = new Node(1, head);
System.out.println(hasCircle(head));*/
// 1 --> 2 --> 3 --> 4 --> 2...
/*Node node = new Node(4);
Node head = new Node(3, node);
head = new Node(2, head);
node.next = head;
head = new Node(1, head);
System.out.println(hasCircle(head));*/
// 1 --> 2 --> 3 --> 4 --> 4 ...
Node head = new Node(4);
head.next = head;
head = new Node(3, head);
head = new Node(2, head);
head = new Node(1, head);
System.out.println(hasCircle(head));
}
}
进阶版:判断单链表中是否有环
如果有环,返回入环的第一个结点
否则返回null
思路1: 迷雾森林
将经过的结点做标记。Collection visited.
遍历链表:
判断当前结点是否在visited集合中存在。contains
存在:返回该节点
不存在:遍历下一个结点。
遍历结束:返回null。
/*
时间复杂度:O(n)
空间复杂度:O(n)
*/
public static Node hasCircle(Node head) {
Collection visited = new HashSet();
Node x = head;
while (x != null) {
if (visited.contains(x)) return x;
visited.add(x);
x = x.next;
}
return null;
}
思路2:跑道(快慢指针)
public static Node hasCircle(Node head) {
Node fast = head;
Node slow = head;
do {
if (fast == null || fast.next == null) return null;
slow = slow.next;
fast = fast.next.next;
} while (slow != fast);
// 将fast移动到头结点
fast = head;
while (slow != fast) {
fast = fast.next;
slow = slow.next;
}
return fast;
}
3.反转链表
反转单链表
示例
输入:1 --> 2 --> 3 --> null
输出:3 --> 2 --> 1 --> null
思路1:头插法
public class Ex1 {
public static Node reverse(Node head) {
Node prev = null;
Node curr = head;
while (curr != null) {
Node next = curr.next;
curr.next = prev;
prev = curr;
curr = next;
}
return prev;
}
/
思路2:递归
public static Node reverse(Node head) {
if (head.next == null) return head;
// 反转head.next
Node reversed = reverse(head.next);
// 反转head结点
head.next.next = head;
head.next = null;
return reversed;
}
数组VS链表:数组更加高效,链表更加灵活

数组和链表的插入,删除,随机访问操作的时间复杂度刚好相反。
- 数组使用的是连续的内存空间,可以利用CPU的高速缓存预读数据。链表的内存空间不是连续的,不能有效预读数据。当然如果数组过大,系统没有足够的连续内存空间,会抛出OOM。
- 数组的缺点是大小固定,没法动态的调整大小。如果要存储一些对象,如果数组太大,浪费内存空间;如果数组太小,我们需要重新申请一个更大数组,并将数据拷贝过去,耗时。
- 如果业务对内存的使用非常苛刻,数组更适合。因为结点有指针域,更消耗内存。而且对链表的频繁插入和删除,会导致结点对象的频繁创建和销毁,有可能会导致频繁的GC活动。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









