






 第四范式的新框架SLXLLM和硬件加速卡SLX通过优化技术显著提升了大模型推理性能,尤其在显存利用上实现10倍提升,使得在有限显存条件下可以部署更多模型,降低推理成本。SLX还兼容多种主流大模型框架,推动大模型在实际应用中的落地.
第四范式的新框架SLXLLM和硬件加速卡SLX通过优化技术显著提升了大模型推理性能,尤其在显存利用上实现10倍提升,使得在有限显存条件下可以部署更多模型,降低推理成本。SLX还兼容多种主流大模型框架,推动大模型在实际应用中的落地.
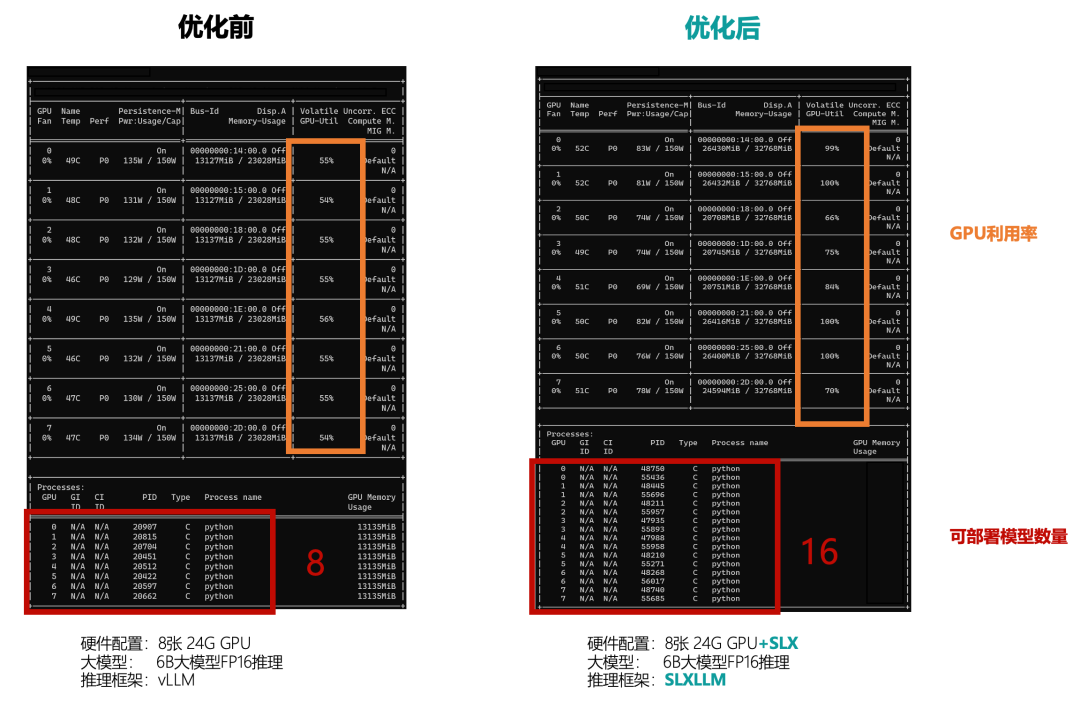
为破解大模型推理中GPU显存瓶颈,第四范式发布了大模型推理框架SLXLLM以及硬件版本的推理加速卡4Paradigm Sage LLM Accelerator(简称SLX)。通过多任务共享存储及处理优化技术,大模型推理性能提升10倍;在模型效果无损情况下,同样使用8张24G显存GPU对6B/7B大模型进行FP16推理,可部署的模型数量从8增至16,GPU利用率从55%最高提升至100%,推理成本仅为原来的一半。值得一提的是,该能力也将集成在4Paradigm Sage AIOS 5.0中,推动大模型落地应用。
当前,业界公认的大模型推理主要瓶颈之一是GPU显存瓶颈。同算力一样,显存是衡量GPU性能的关键指标之一,用于存储计算结果、模型参数等数据。在大模型推理的过程中,往往因为显存受限,导致GPU的算力无法被“全部激活”用于推理过程,GPU算力利用率较低,大模型推理成本居高不下。

为此,第四范式发布了大模型推理框架SLXLLM以及推理加速卡SLX,在二者联合优化下,在文本生成类场景中,大模型推理性能提升10倍。例如在使用4张80G GPU对72B大模型进行推理测试中,相较于使用vLLM,第四范式使用SLXLLM+SLX的方案,可同时运行任务数量从4增至40。此外,推理加速卡SLX也可兼容TGI、FastLLM、vLLM等主流大模型推理框架,大模型推理性能提升约1-8倍。


















 9
9

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









