






 本文通过Jupyter Notebook开发环境,利用sklearn框架,详细介绍了如何对MNIST数据集进行机器学习分类,探索人工智能在图像识别领域的应用。未来在这一领域还有广阔的发展前景,一起加油吧!
本文通过Jupyter Notebook开发环境,利用sklearn框架,详细介绍了如何对MNIST数据集进行机器学习分类,探索人工智能在图像识别领域的应用。未来在这一领域还有广阔的发展前景,一起加油吧!
from scipy.io import loadmat # loadnmat用来加载从kaggle上下载的.mat文件
mnist = loadmat('datasets/MNIST/mnist-original.mat')
mnist["target"]=mnist["label"]
del mnist["label"]
mnist

X,y = mnist["data"],mnist["target"]
X = X.T
X.shape
y=y.T.ravel() # 扁平化
y.shape
X_train,X_test,y_train,y_test = X[:60000],X[60000:],y[:60000],y[60000:] # MNIST已经将数据分好数据集和测试集了,前6w为训练集
import numpy as np # 将训练集的数据洗牌,保证X与y的对应不变,只改变相应的脚标,不改变对应关系
shuffle_index = np.random.permutation(60000) # 将60000随机分配index,用np.random.permutation(60000)
X_train,y_train = X_train[shuffle_index],y_train[shuffle_index] # 重新洗牌
# 先训练一个二元的分类器
y_train_5 = (y_train == 5) #将所有等于5的y设置为true,其余的为false(y_train_5)
y_test_5 = (y_test == 5)
from sklearn.linear_model import SGDClassifier # 先选择一个随机梯度下降的分类器,SGDClassifier,适合大型数据集
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train,y_train_5) # 先fit,再predict预测是否为True or False
sgd_clf.predict([some_digit]) # predict函数里面放array
from sklearn.model_selection import cross_val_score #从sklearn.model_selection的模型选择库里import 交叉验证分数
cross_val_score(sgd_clf,X_train,y_train_5,cv=3,scoring="accuracy") # 分类器,训练集,测试集,折叠三次,留1个预测,其他的训练
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf,X_train,y_train_5,cv=3) #从未见过的预测结果
y_train_pred
from sklearn.metrics import confusion_matrix # 从metrics里面导入混淆矩阵
confusion_matrix(y_train_5,y_train_pred) #用cross_val_predict的预测结果与真实结果相构成混淆矩阵
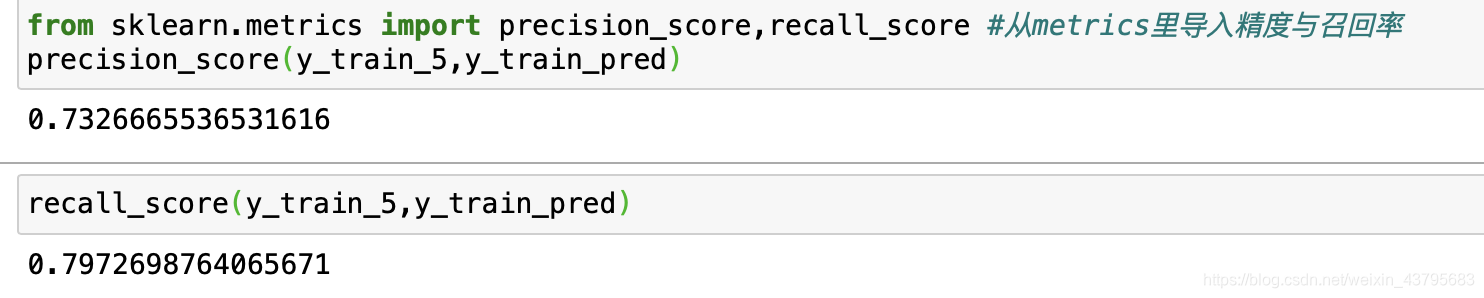
from sklearn.metrics import precision_score,recall_score #从metrics里导入精度与召回率
precision_score(y_train_5,y_train_pred)
recall_score(y_train_5,y_train_pred)
from sklearn.metrics import f1_score # 一种更客观的方法
f1_score(y_train_5,y_train_pred)
y_scores = sgd_clf.decision_function([some_digit]) # 用于预测的决策分数,根据这个设置阈值
y_scores
# 阈值评估
threshold = 0
y_some_digit_pred = (y_scores > threshold)
y_some_digit_pred
y_scores = cross_val_predict(sgd_clf,X_train,y_train_5,cv=3,method="decision_function") #决定使用什么阈值,先计算出预测分数
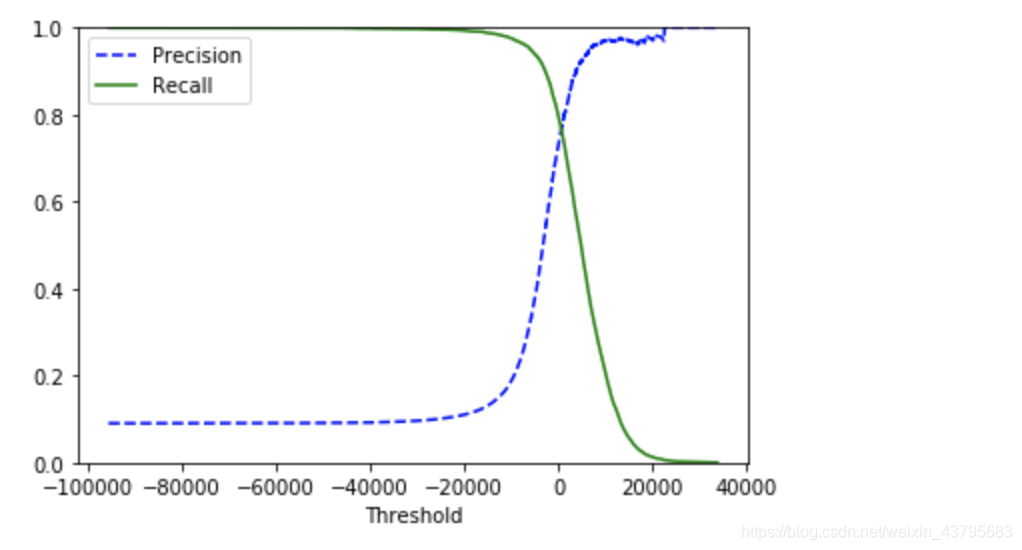
from sklearn.metrics import precision_recall_curve
precisions,recalls,thresholds = precision_recall_curve(y_train_5,y_scores) # 根据预测分计算出precisions,recalls,thresholds等用来画图
def plot_precision_recall_vs_threshold(precisions,recalls,thresholds):
plt.plot(thresholds,precisions[:-1],"b--",label="Precision")
plt.plot(thresholds,recalls[:-1],"g-",label="Recall") #recalls[:-1]除了最后一个取全部
plt.xlabel("Threshold")
plt.legend(loc="best")
plt.ylim([0,1]) # y轴的范围
plot_precision_recall_vs_threshold(precisions,recalls,thresholds)
plt.show()
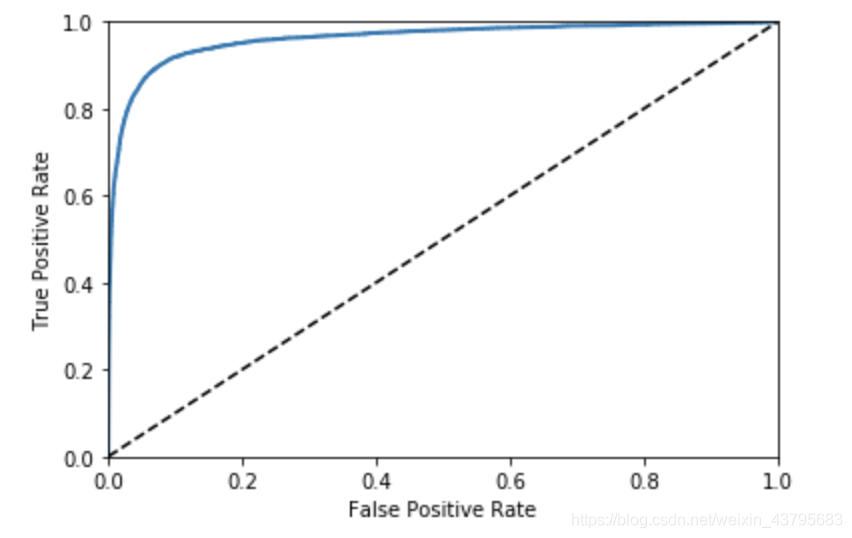
from sklearn.metrics import roc_curve
fpr,tpr,threshold = roc_curve(y_train_5,y_scores) # 同样的方法画出fpr,tpr,threshold
def plot_roc_curve(fpr,tpr,label=None):
plt.plot(fpr,tpr,linewidth=2,label=label)
plt.plot([0,1],[0,1],'k--')
plt.axis([0,1,0,1])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plot_roc_curve(fpr,tpr)
plt.show()
from sklearn.metrics import roc_auc_score # 计算面积,面积越大越好
roc_auc_score(y_train_5,y_scores)

from sklearn.ensemble import RandomForestClassifier # 使用随机森林分类器试试看
forest_clf = RandomForestClassifier(random_state=42)
y_probas_forest = cross_val_predict(forest_clf,X_train,y_train_5,cv=3,method="predict_proba")
y_scores_forest = y_probas_forest[:,1]
fpr_forest,tpr_forest,thresholds_forest = roc_curve(y_train_5,y_scores_forest)
plt.plot(fpr,tpr,"b:",label="SGD")
plot_roc_curve(fpr_forest,tpr_forest,"Random Forest")
plt.legend(loc="best")
plt.show()
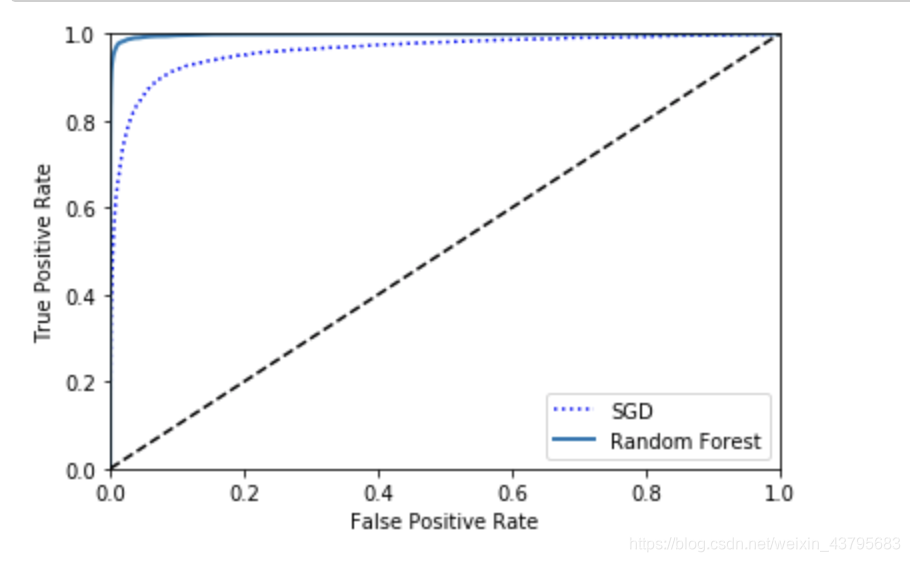
roc_auc_score(y_train_5,y_scores_forest)

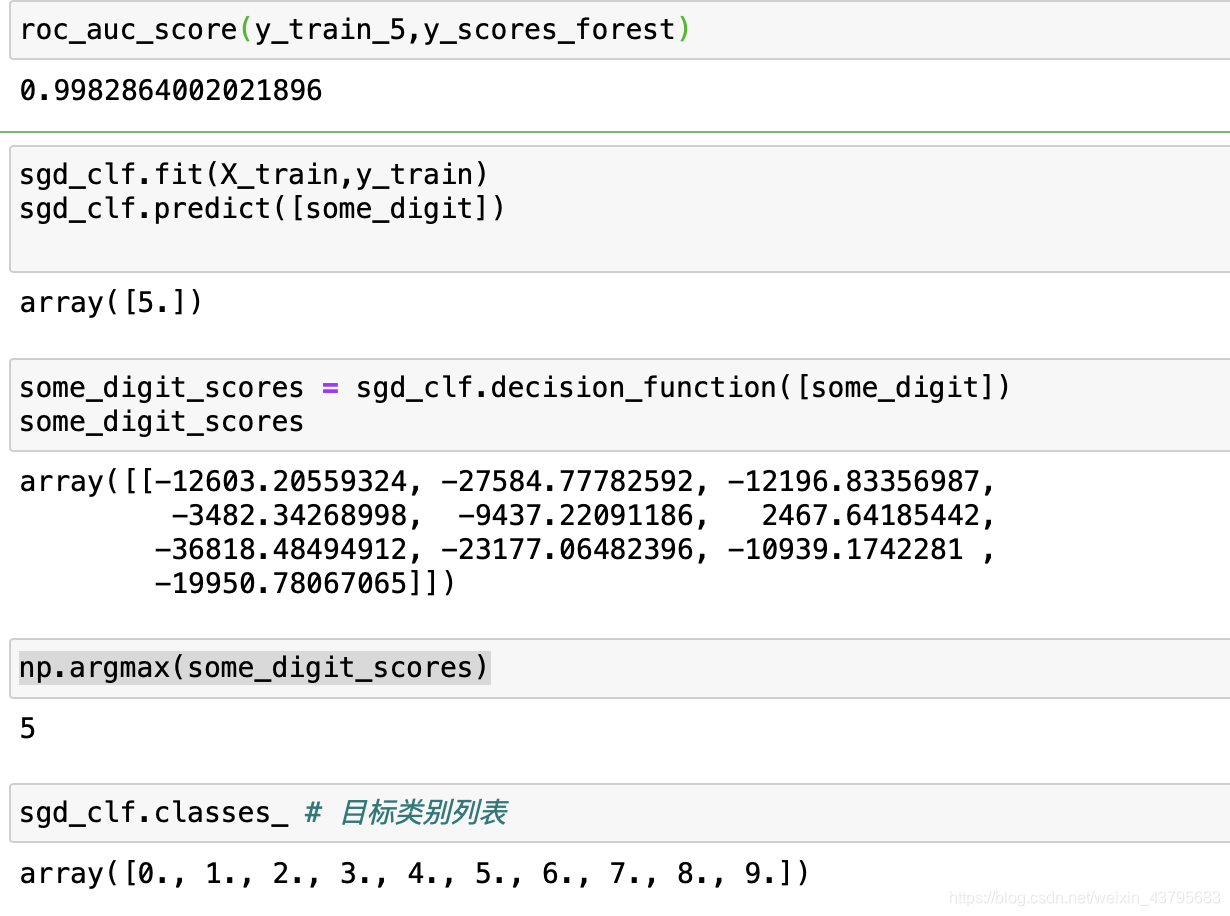
sgd_clf.fit(X_train,y_train)
sgd_clf.predict([some_digit])
some_digit_scores = sgd_clf.decision_function([some_digit])
some_digit_scores
np.argmax(some_digit_scores)
sgd_clf.classes_ # 目标类别列表
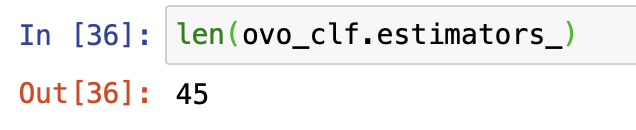
from sklearn.multiclass import OneVsOneClassifier # 开始尝试multiclass分类
ovo_clf = OneVsOneClassifier(SGDClassifier(random_state=42)) #两个分类器组合
ovo_clf.fit(X_train,y_train)
ovo_clf
forest_clf.fit(X_train,y_train)
forest_clf.predict([some_digit])

forest_clf.predict_proba([some_digit])

cross_val_score(sgd_clf,X_train,y_train,cv=3,scoring="accuracy")

# 缩放,StandardScaler
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
cross_val_score(sgd_clf,X_train_scaled,y_train,cv=3,scoring="accuracy")

y_train_pred = cross_val_predict(sgd_clf,X_train_scaled,y_train,cv=3)
conf_mx = confusion_matrix(y_train,y_train_pred)
conf_mx

plt.matshow(conf_mx,cmap=plt.cm.gray)
plt.show()
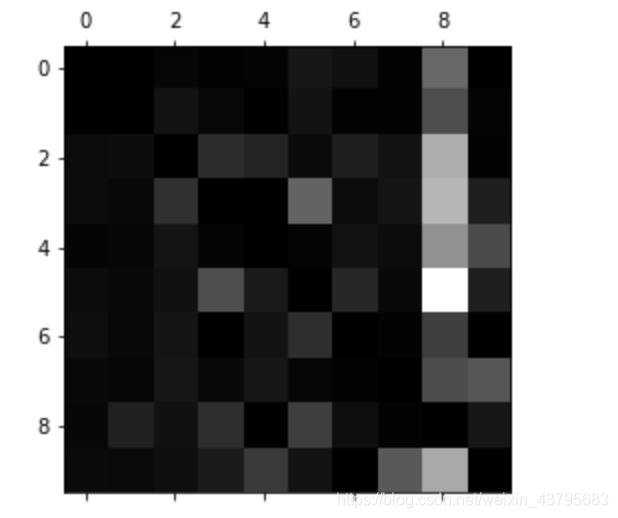
row_sums = conf_mx.sum(axis=1,keepdims=True)
norm_conf_mx = conf_mx/row_sums
np.fill_diagonal(norm_conf_mx,0)
plt.matshow(norm_conf_mx,cmap=plt.cm.gray) # 亮的代表分类错误
plt.show()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









