







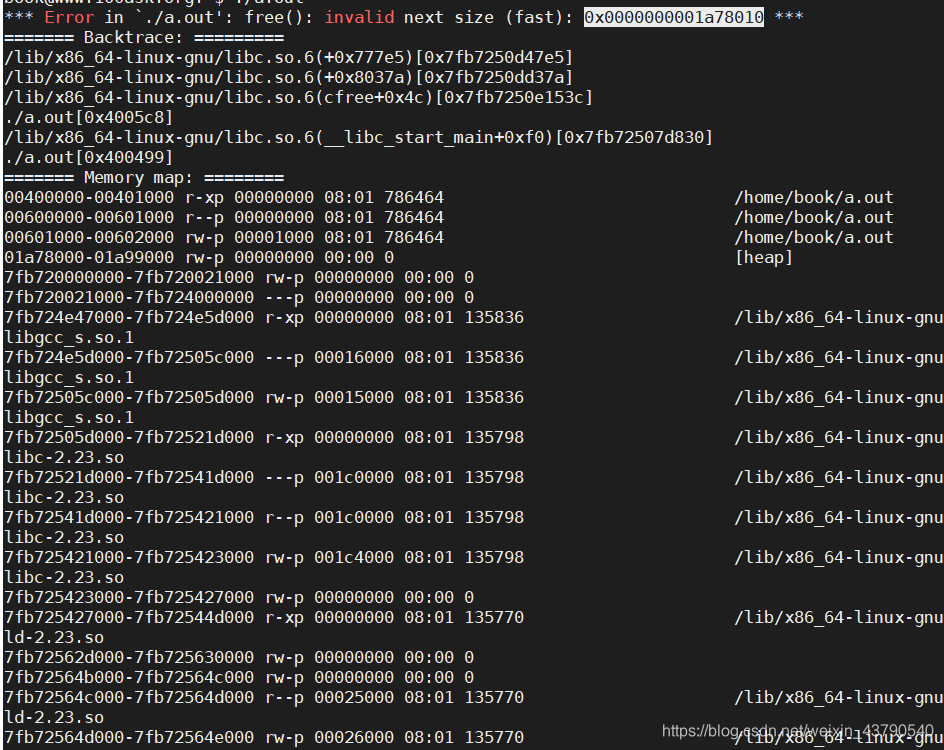
C语言复习第九天
内存操作经典问题
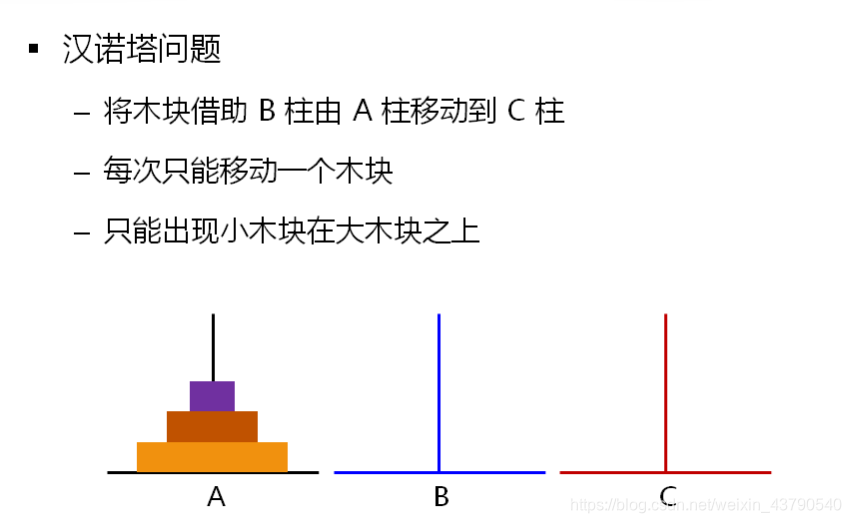
问题一
野指针
- 指针变量中的值是非法的内存地址,进而形成野指针
- 野指针不是NULL指针, 是指向不可用内存地址的指针
- NULL指针并无危害,很好判断,也很好调试
- C语言中 无法判断一个指针所保存的地址是否合法
野指针的由来
- 局部指针变量 没有被初始化
- 指针所指向的 变量在指针之前被销毁
- 使用已经释放过的指针
- 进行了错误的指针运算
- 进行了错误的强制类型转换
示例:
#include <stdio.h>
#include <malloc.h>
int main()
{
int* p1 = (int*)malloc(40);
int* p2 = (int*)1234567; //整形强制转换成指针,为野指针
int i = 0;
for(i=0; i<40; i++)
{
*(p1 + i) = 40 - i; //申请了40字节内存,这里访问越界了
}
free(p1);
for(i=0; i<40; i++)
{
p1[i] = p2[i]; //使用已经释放了的指针p1
}
return 0;
}
基本原则
- 绝不返回局部变量和局部数组的地址
- 任何变量在定义后必须0初始化
- 字符数组必须确认0结束符之后才能成为字符串
- 任何使用与内存操作相关的函数必须指定长度信息
示例:
#include <stdio.h>
#include <string.h>
#include <malloc.h>
struct Student
{
char* name;
int number;
};
char* func()
{
char p[] = "D.T.Software";
return p;
}
void del(char* p)
{
printf("%s\n", p);
free(p);
}
int main()
{
struct Student s; //成员char* name没有初始化
char* p = func(); //传递了局部数组的指针
strcpy(s.name, p);
s.number = 99;
p = (char*)malloc(5);
strcpy(p, "D.T.Software"); //p的内存不够,访问越界
del(p);
return 0;
}
修改后:
#include <stdio.h>
#include <string.h>
#include <malloc.h>
struct Student
{
char* name;
int number;
};
char* func()
{
static char p[] = "D.T.Software"; //返回静态局部指针变量,程序调用结束,内存不释放
return p;
}
void del(char* p)
{
printf("%s\n", p);
free(p);
}
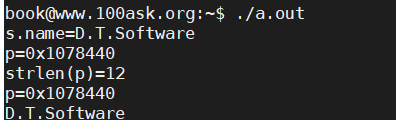
int main()
{
struct Student s;
s.name=NULL;
char* p = func();
s.name=(char*)malloc(strlen(p)+1); //申请足够大的内存
strcpy(s.name, p);
printf("s.name=%s\n",s.name);
s.number = 99;
p=NULL;
p = (char*)malloc(13); //申请足够大的内存
printf("p=%p\n",p);
strcpy(p, "D.T.Software");
printf("strlen(p)=%d\n", strlen(p));
printf("p=%p\n",p);
del(p);
return 0;
}
问题二
常见的内存错误
- 结构体成员指针未初始化
- 结构体成员指针未分配足够的内存
- 内存分配成功,但并未初始化
- 内存操作越界
示例:
#include <stdio.h>
#include <malloc.h>
void test(int* p, int size)
{
int i = 0;
for(i=0; i<size; i++)
{
printf("%d\n", p[i]);
}
free(p);
}
void func(unsigned int size)
{
int* p = (int*)malloc(size * sizeof(int));
int i = 0;
if( size % 2 != 0 )
{
return;
}
for(i=0; i<size; i++)
{
p[i] = i;
printf("%d\n", p[i]);
}
free(p);
}
int main()
{
int* p = (int*)malloc(5 * sizeof(int));
test(p, 5);
free(p); //多次释放,其次释放后,指针没有赋为NULL,为野指针
func(9); //函数内申请的指针未被释放
func(10);
return 0;
}
#include <stdio.h>
#include <malloc.h>
struct Demo
{
char* p;
};
int main()
{
struct Demo d1;
struct Demo d2;
char i = 0;
for(i='a'; i<'z'; i++)
{
d1.p[i] = 0; //d1.p并未申请内存,并且下表太大'a'==48
}
d2.p = (char*)calloc(5, sizeof(char)); //申请内存并且初始化为0,calloc会将内存初始化为0
printf("%s\n", d2.p);
for(i='a'; i<'z'; i++)
{
d2.p[i] = i; //下标访问越界
}
free(d2.p); //释放后,没有指向NULL,为野指针
return 0;
}
内存操作的交通规则
- 动态申请内存之后,应该立即检查指针值是否为NULL,防止使用NULL指针
int *p =(int *)malloc(56);
if(p!=NULL)
{
//Do something here!
}
free(p);
- free指针之后必须立即赋值为NULL.
int *p =(int *)malloc(20);
free(p);
p=NULL;
- 任何与内存操作相关的函数都必须带长度信息
void print(int *p,int size)
{
int i=0;
char buf[128]={0};
snprintf(buf,sizeof(buf),"%s","rengeshuai");
for(int i=0;i<size;i++)
{
printf("%d\n",p[i]);
}
}
- malloc操作和free操作必须匹配,防止内存泄漏和多次释放
void func()
{
int *p=(int *)malloc(sizeof(int)*4);
free(p);
}
int main()
{
int *p=(int *)malloc(40);
func();
free(p);
return 0;
}
小结
- 内存错误的本质源于指针保存的地址为非法值
——指针变量未初始化,保存随机值
——指针运算导致内存越界 - 内存泄漏源于malloc和free不匹配
——当malloc次数多于free时,产生内存泄漏
——当malloc次数少于free时,程序可能崩溃
函数的意义
面向过程的程序设计
- 面向过程是一种以过程为中心的编程思想
- 首先将复杂的问题分解为一个个容易解决的问题
- 分解过后的问题可以按照步骤一步步完成
- 函数是面向过程在C语言中的体现
- 解决问题的每个步骤可以用函数来实现
声明和定义
- 声明的意义在于告诉编译器程序单元的存在
- 定义则明确指示程序单元的意义
- C语言中通过extern进行程序单元的声明
- 一些程序单元在声明时可以省略extern
tips
严格意义上的声明和定义并不相同
举例:
//global.c
#include <stdio.h>
int g_var = 10;
struct Test
{
int x;
int y;
};
void f(int i, int j)
{
printf("sizeof(struct Test)=%d\n",sizeof(struct Test));
printf("i + j = %d\n", i + j);
}
int g(int x)
{
return (int)(2 * x + g_var);
}
//test.c
#include <stdio.h>
#include <malloc.h>
extern int g_var;
extern struct Test;
int main()
{
extern void f(int i, int j);
extern int g(int x);
//struct Test* p = NULL;
struct Test* p =(struct Test*)malloc(sizeof(struct Test));
//printf("sizeof(struct Test)=%d\n",sizeof(struct Test));
//printf("p = %p\n", p);
//g_var = 10;
printf("g_var = %d\n", g_var);
f(1, 2);
printf("g(3) = %d\n", g(3));
//free(p);
return 0;
}
在这里根本找不到结构体Test 的定义,定义和声明是不一样的

小结
- 函数是面向过程思想在C语言的体现
- 面向过程是由上至下分解问题的设计方法
- 程序中的定义和声明完全不同
- C语言中通过extern对程序单元进行声明
函数参数的秘密(上)
程序中的顺序点
- 程序中存在一定的顺序点
- 顺序点指的是执行过程中修改变量值的最晚时刻
- 在程序到达顺序点的时候,之前所做的一切操作必须完成。
C语言中的顺序点
- 每个完整表达式结束时,即分号处
- &&,||,?:,以及逗号表达式的每个参数计算之后
- 函数调用时所有实参求值完成后(进入函数体之前)
示例:
#include <stdio.h>
int func(int i, int j)
{
printf("%d, %d\n", i, j);
return 0;
}
int main()
{
int k = 1;
func(k++, k++);
printf("%d\n", k);
return 0;
}
tips
从打印的结果可以看出,参数是从右往左传入的。

小结
- 函数的参数是在栈上分配空间
- 函数的实参并没有固定的计算次序
- 顺序点是C语言中变量修改的最晚时机
函数参数的秘密(下)
参数入栈顺序
函数参数的计算次序是依赖编译器实现的,那么函数参数的入栈次序是如何确定的呢?
调用约定
- 当函数调用发生时
——参数会传递给被调用的函数
——二返回值会被返回给函数调用者 - 调用约定描述参数如何传递到栈中以及栈的维护方式
——参数传递顺序
——调用栈清理
——调用约定是预定义的可理解为调用协议
——调用约定通常用于库调用和库开发的时候
——从右到左依次入栈:_stdcall, _cdecl(C语言的方式),_thiscall
——从左到右依次入栈:_pascal,_fastcall
可变参数
- C语言可以定义参数可变的函数
- 参数可变函数的实现依赖于stdarg.h头文件
——va_list -参数集合
——va_arg -取具体参数值
——va_start- 标识参数访问的开始
——va_end-标识参数访问的结束
示例:1.普通函数求平均 2.可变参数求int 类型的平均值
#include <stdio.h>
#include <stdarg.h>
float average_arg(int n,...)
{
va_list args;
float sum=0;
va_start(args,n);
for(int i=0;i<n;i++)
{
sum+=va_arg(args,int);
}
va_end(args);
return sum/n;
}
float average(int array[], int size)
{
int i = 0;
float avr = 0;
for(i=0; i<size; i++)
{
avr += array[i];
}
return avr / size;
}
int main()
{
int result=average_arg(3,1,2,3);
int result_1=average_arg(5,1,2,3,4,5);
printf("result=%d\n",result);
printf("result_1=%d\n",result_1);
return 0;
}

可变参数的限制
- 可变参数必须从头到尾按照顺序逐个访问
- 参数列表中至少要存在一个确定的命名参数
- 可变参数函数无法确定实际存在的参数的数量
- 可变参数函数无法确定参数的实际类型
注意:
va_arg中如果指定了错误的类型,那么结果是不可预测的。
小结
- 调用约定指定了函数参数的入栈顺序以及栈的清理方式
- 可变参数是C语言提供的一种函数设计技巧
- 可变参数的函数提供了一种更方便的函数调用方式
- 可变参数必须顺序的访问,无法直接访问中间的参数值
函数与宏分析
函数与宏
- 宏是由预处理器直接替换展开的,编译器不知道宏的存在
- 函数是由编译器直接编译的实体,调用行为由编译器决定
- 多次使用宏会导致最终可执行程序的体积增大
- 函数是跳转执行的,内存中只有一份函数体存在
- 宏的效率比函数要高,因为是直接展开,无调用开销
- 函数调用时会创建活动记录,效率不如宏
示例:
#include <stdio.h>
#define RESET(p, len) \
while( len > 0 ) \
((char*)p)[--len] = 0
void reset(void* p, int len)
{
while( len > 0 )
((char*)p)[--len] = 0;
}
int main()
{
int array[] = {1, 2, 3, 4, 5};
int len = sizeof(array);
int i = 0;
for(i=0; i<5; i++)
{
printf("array[%d] = %d\n", i, array[i]);
}
return 0;
}
- 宏的效率比函数稍高,但是其副作用巨大
- 宏是文本替换,参数无法进行类型检查
- 可以用函数完成的功能绝对不用宏
- 宏的定义中不能出现递归调用
示例:
#include <stdio.h>
#define _ADD_(a, b) a + b
#define _MUL_(a, b) a * b
#define _MIN_(a, b) ((a) < (b) ? (a) : (b))
int main()
{
int i = 1;
int j = 10;
printf("%d\n", _MUL_(_ADD_(1, 2), _ADD_(3, 4)));
printf("%d\n", _MIN_(i++, j));
return 0;
}
预编译后的结果:(宏定义就是文本替换)
int main()
{
int i = 1;
int j = 10;
printf("%d\n", 1 + 2 * 3 + 4);
printf("%d\n", ((i++) < (j) ? (i++) : (j)));
return 0;
}
宏的妙用
- 用于生成一些常规性的代码
- 封装函数,加上类型信息
示例:
#include <stdio.h>
#include <malloc.h>
#define MALLOC(type, x) (type*)malloc(sizeof(type)*x)
#define FREE(p) (free(p), p=NULL)
#define LOG_INT(i) printf("%s = %d\n", #i, i)
#define LOG_CHAR(c) printf("%s = %c\n", #c, c)
#define LOG_FLOAT(f) printf("%s = %f\n", #f, f)
#define LOG_POINTER(p) printf("%s = %p\n", #p, p)
#define LOG_STRING(s) printf("%s = %s\n", #s, s)
#define FOREACH(i, n) while(1) { int i = 0, l = n; for(i=0; i < l; i++)
#define BEGIN {
#define END } break; }
int main()
{
int* pi = MALLOC(int, 5);
char* str = "D.T.Software";
LOG_STRING(str);
LOG_POINTER(pi);
FOREACH(k, 5)
BEGIN
pi[k] = k + 1;
END
FOREACH(n, 5)
BEGIN
int value = pi[n];
LOG_INT(value);
END
FREE(pi);
LOG_POINTER(pi);
return 0;
}
小结
- 宏和函数并不是竞争对手
- 宏能够接受任何类型的参数,效率高,易出错
- 函数的参数必须是固定类型,效率稍低,不易出错
- 宏可以实现函数不能实现的功能
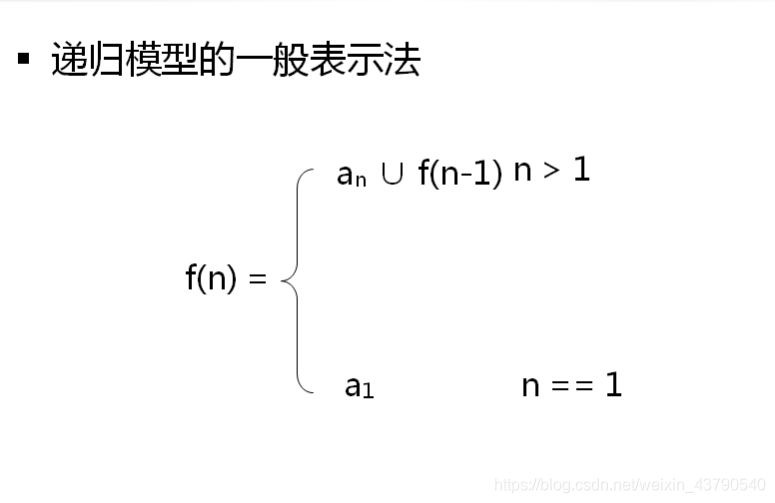
递归函数分析
递归的数学思想
- 递归是一种数学上分而自治的思想
- 递归需要有边界条件
——当边界条件不满足时,递归继续进行
——当边界条件满足时,递归停止
tips:
递归将大型复杂问题转化为与原问题相同但规模较小的问题进行处理
递归函数
- 函数体内部可以调用自己
- 递归函数
——函数体中存在自我调用的函数 - 递归函数是递归的数学思想在程序设计中的应用
——递归函数必须有递归出口
——函数的无限递归将导致程序栈溢出而崩溃
递归函数设计技巧
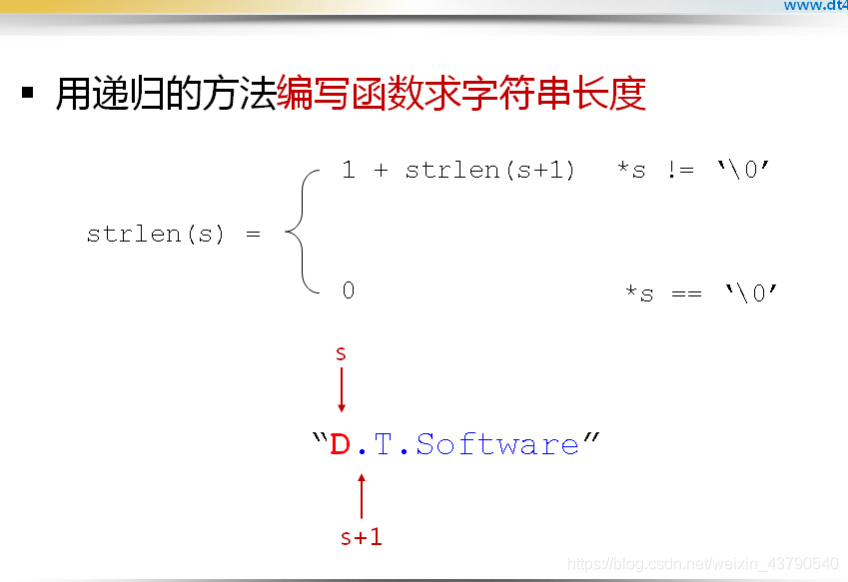
示例:
#include <stdio.h>
int strlen_r(const char* s)
{
if( *s )
{
return 1 + strlen_r(s+1);
}
else
{
return 0;
}
}
int main()
{
printf("%d\n", strlen_r("abc"));
printf("%d\n", strlen_r(""));
return 0;
}

#include <stdio.h>
int fac(int n)
{
if( n == 1 )
{
return 1;
}
else if( n == 2 )
{
return 1;
}
else
{
return fac(n-1) + fac(n-2);
}
return -1;
}
int main()
{
printf("%d\n", fac(1));
printf("%d\n", fac(2));
printf("%d\n", fac(9));
return 0;
}
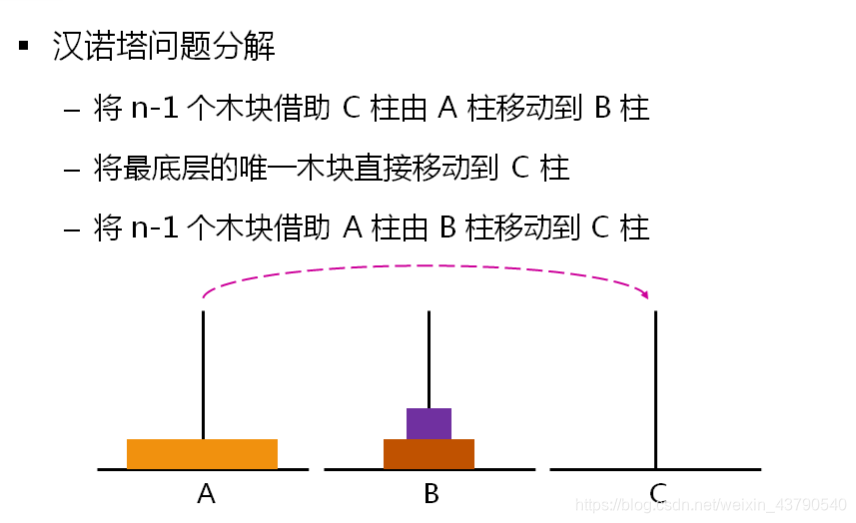
#include <stdio.h>
void han_move(int n, char a, char b, char c)
{
if( n == 1 )
{
printf("%c --> %c\n", a, c);
}
else
{
han_move(n-1, a, c, b);
han_move(1, a, b, c);
han_move(n-1, b, a, c);
}
}
int main()
{
han_move(3, 'A', 'B', 'C');
return 0;
}
小结
- 递归是一种将问题分而自治的思想
- 用递归解决问题首先要建立递归的模型
- 递归解法必须要有边界条件,否则无解
函数设计原则
函数设计原则
- 函数从意义上应该是一个独立的功能模块
- 函数名要在一定程度上反映函数的功能
- 函数参数名要能够体现参数的意义
- 尽量避免在函数中使用全局变量
void sc(char*s1,char*s2);
void str_copy(char* str_dest,char *str_src);
- 当函数参数不应该在函数体内部修改时,应加上cosnt声明
- 如果参数是指针,且仅作输入参数,则应加上const声明
void str_copy(char *str_dest,const char * str_src);
- 不能省略返回值的类型
——如果函数没有返回值,那么应声明为void 类型 - 对参数进行有效性检查
——对于指针参数的检查尤为重要 - 不要返回指向"栈内存"的指针
——栈内存在函数体结束时被自动释放 - 函数体的规模要小,尽量控制在80行代码之内
- 相同的输入对应相同的输入,避免函数带有"记忆"功能
- 避免函数有过多的参数,参数个数尽量控制在4个以内
- 有时候函数不需要返回值,但为了增加灵活性,如支持链式表达,可以附加返回值
char s[64];
int len=strlen(strcpy(s,"android"));
- 函数名与返回值类型在语义上不可冲突
char c=getchar(); // 实际上getchar()返回的是int类型,字符的ascill值
if(EOF==c)
{
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









