







 本文通过分析sklearn中的乳腺癌数据集,探讨不同核函数(linear, poly, rbf, sigmoid)在SVM中的表现。线性核函数在特定情况下效果良好,但计算成本较高;多项式核函数poly在大量特征时可能无法计算,调整degree为1可改善;非线性核函数中,rbf在适当调参后展现出优秀性能。通过网格调参优化C和gamma参数,可以进一步提升模型效果。"
127955619,16550489,IM文件传输优化:职场网络链路提速,"['后端开发', '网络优化', '性能提升', '通信协议', '职场网络']
本文通过分析sklearn中的乳腺癌数据集,探讨不同核函数(linear, poly, rbf, sigmoid)在SVM中的表现。线性核函数在特定情况下效果良好,但计算成本较高;多项式核函数poly在大量特征时可能无法计算,调整degree为1可改善;非线性核函数中,rbf在适当调参后展现出优秀性能。通过网格调参优化C和gamma参数,可以进一步提升模型效果。"
127955619,16550489,IM文件传输优化:职场网络链路提速,"['后端开发', '网络优化', '性能提升', '通信协议', '职场网络']
前言
前面我们了解了在不同的数据分布下,不同核函数的表现效果,但是实际应用中我们的数据往往有很多的特征,导致我们很难知道具体的数据分布情况,让我们比较难选择较好的核函数。当然了选择“rbf”一直是一个不错的选择。
但是每个核函数都有自己的优势和弊端,这篇文章我们会试着对这些核函数进行探索,使用的数据集是sklearn中的乳腺癌数据集。
本文中使用到的所有依赖库
from sklearn.datasets import load_breast_cancer # 乳腺癌数据集
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV # 网格搜索
from sklearn.preprocessing import StandardScaler # 标准化,使得数据服从0-1分布
from sklearn.decomposition import PCA # 降维
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import warnings
import time
%matplotlib inline
warnings.filterwarnings("ignore")
原始数据集探索
导入 数据
datas = load_breast_cancer()
X, y = datas.data, datas.target
X.shape # (569, 30)
尝试画出数据的分布
# 对于这样的有30个特征的数据集,就比较难以知道它的分布了
# 但是我们可以试着使用PCA降维来看看保留两个特征剩余的信息量,试着画出分布图
pca2 = PCA(n_components=2).fit(X)
X_new = pca2.transform(X)
print("剩余信息量: %.3f" % pca2.explained_variance_ratio_.sum())
plt.scatter(X_new[:, 0], X_new[:, 1], c=y)
# 看起来感觉是线性的,但是有一部分的点可能是覆盖在一起了,也可能是样本不均衡
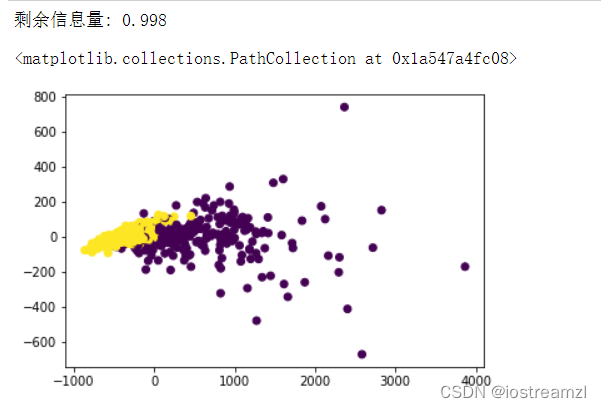
这里降维后的数据集所包含的信息量达到了99%,基本上上面的分布就是实际的数据分布了,这里数据选择的比较巧合,实际中是很少有这种情况的。
训练测试集分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
核函数性质探究
看不同核函数的表现
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









