







Grain论文详解
Link: Grain: Improving Data Efficiency of Graph Neural Networks via Diversified Influence Maximization
Github Code: https://github.com/zwt233/Grain
本文主要介绍了一种使用影响力最大化(Influence Maximization)和多样性(diversity)方法的数据选择技术,使得我们只需要选择部分信息量最大的节点进行标记后训练,就可以让测试误差达到极小值。
1 Introduction
Grain提供了一个全新视角,在GNN的数据选择和社交影响力最大化(social influence maximization)之间搭建了桥梁。它介绍了一种新颖的特征传播概念和一个由影响力和多样化的双目标思想组成的多样化影响力最大化目标函数(diversified influence maximization)。并且它提供了一种有近似保证的贪心算法,用于改善数据选择的能力。
图神经网络在各个基于图的任务都达到了SOTA效果,例如节点分类和链接预测等等。但是它在训练的时候为了达到良好的效果需要大量的标注数据。因此在GNN领域中引入数据选择(data selection)是很重要的。
图神经网络从邻居节点汇聚了特征信息,但是目前的数据选择方法都忽略了图结构上的交互信息。
本文作者提出了Grain框架,一个为GNN准备的新颖的高效数据选择的框架。它的运行哲学如下:
- 选择GNN中最重要的特征传播部分,将其作为一种影响力的传播。
- 类比社交影响力最大化(social influence maximization)思想,用于最大化特征传播的高效性。即通过计算节点 u u u的输入特征在特征传播过程后对节点 v v v的汇聚特征的影响程度来衡量重要性。
Grain会最大化所选择的节点集对未标注节点的影响力。Grain高效地探索了节点间的交互,并且显示的最大化被标注节点影响的未标注节点个数。
此外,除了考虑直接影响力,Grain还考虑了间接影响力(indirect influence),在特征空间相近的节点倾向于为同一类。在这种思想下,Grain引入了多样化思想(diversity)来鼓励影响节点能够覆盖更多的节点。
Grain证明了上述的social influence和diversity influence在该问题(GNN数据选择)下都是单调和具有子模性质的,因此它提出了一种次优的贪心算法,并且通过分离出特征传播层来减少训练代价。
Grain的贡献如下:
- 通过active learning和social influence maximization来优化数据选择。
- 提出了一种新的数据选择准则–> diversified influence maximization,并提出了一种有近似保证的贪心算法。
- 提出了新的目标函数,既考虑了直接影响力,又考虑了简洁影响力。
- 高效和精准。
2 Preliminary
**Activate learning: **在训练中选择数据进行标注,使得训练出来的模型对测试集的误差小。
Core-set selection: 在所有训练集中选取一部分,使得这部分训练出来的结构与训练集差距最小。
social influence maximization: 选择部分节点,使得整个社交网络中被激活的节点最多。
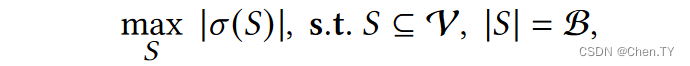
σ ( S ) \sigma(S) σ(S) 是指的某个传播模型下,整个节点集被选择出来的节点激活的个数。虽然计算该值是NP-Hard问题,但是由于它的不增和子模性质,我们可以给出精度在 1 − 1 e 1- \frac{1}{e} 1−e1的保证下的贪心次优解。
3 GRAIN FRAMEWORK
Grain结合了influence和diversity为一个准则,最大化diversified influence,以及在这一准则下选择一些节点。Grain将会一直迭代知道满足节点集大小的budget
B
\mathcal{B}
B。
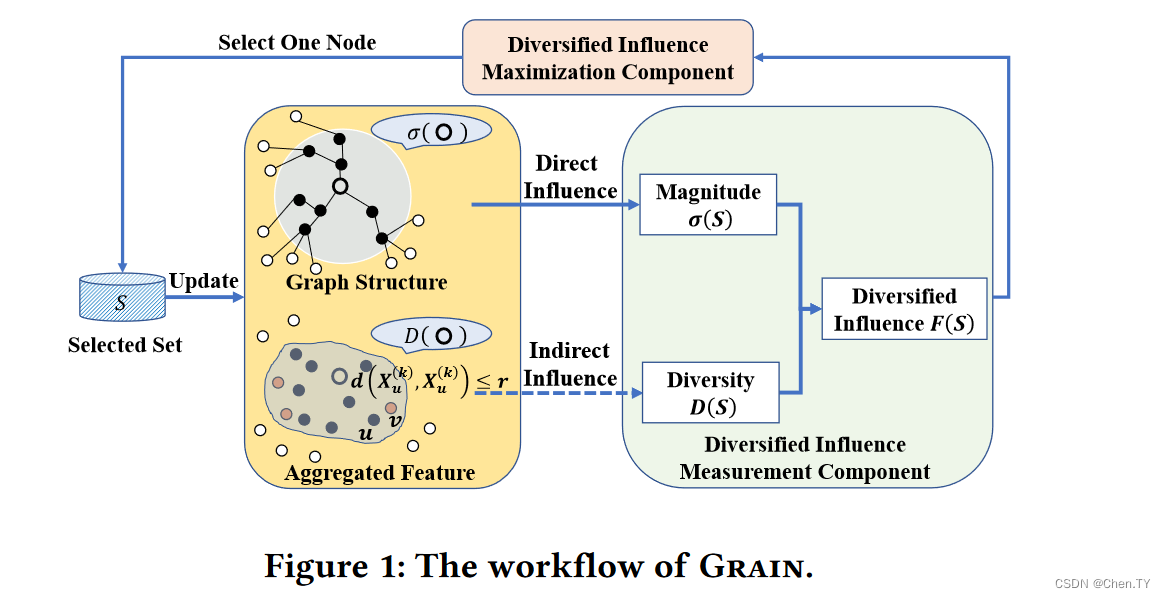
3.1 Feature Influence Model
Decoupled Feature Propagation: 在一些研究中指出GNN最重要的是message passing而不是激活函数,因此我们只取GNN中最重要的特征传播模块用于我们计算,并且构建一个不含参数的方式来计算影响力,即不考虑W权值矩阵(我并不确定这个是否合理)。
Feature Influence Viewpoint:在这种传播模式下,每个节点的
X
k
X^k
Xk就是以它为中心的K层子树汇聚信息,当我们引入IM之后,我们想要知道的是一个节点u的初始特征经过K层迭代后会对其他节点V造成多少影响。

图中的IM函数考虑到了K次迭代中,节点U在不同更新路径上对V的影响。在某些传播模型下,可以理解为在随机游走的情况下U结束在V的点的概率。
tips: 个人理解(还没看过IM的原始定义):原始期望雅可比矩阵可以理解为 X u X_u Xu的初始特征信息在不同路径下对 X v X_v Xv的K层特征信息进行影响,因此可以通过求偏导期望来定义它的影响力。期望公式中的概率就可以认为是随机游走的概率。
[1]证明了一定条件下,GCN影响力分布等同于随机游走分布。(直觉上也很好理解)
3.2 Diversified Influence Maximization
Influence Function:从直觉上来看,u对v的影响会受到影响路径过少而变少,即 I v ( u , k ) I_v(u,k) Iv(u,k)小。
我们定义 I v ( S , k ) = m a x u ∈ S I v ( u , k ) I_v(S,k) = \mathop{max}_{u \in S} I_v(u,k) Iv(S,k)=maxu∈SIv(u,k) 大于阈值时v点被激活。
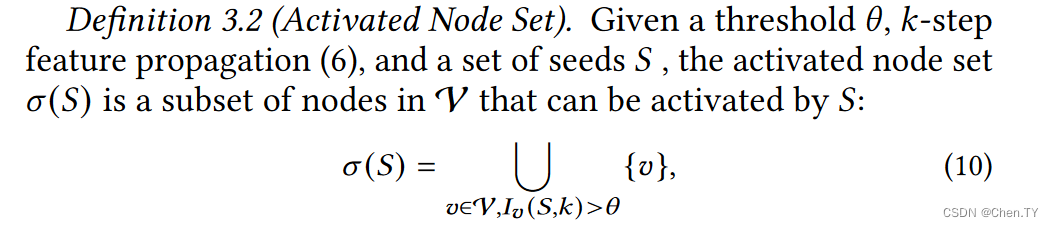
我们可以简单观察得出 ∣ σ ( S ) ∣ |\sigma(S)| ∣σ(S)∣是非降的,且具有子模性质。(首先显然非降,其次被激活过的节点不会影响答案,所以具有子模性质)。
Influence Maximization and Introducing Diversity:
影响力越大,精确度越高。
相似影响力,多样化对精确度有一定的影响。这是因为激活一个节点,往往会对激活其他的节点造成连带影响。
我们可以合理猜测,在节点分类问题当中,特征空间相似的一些节点将会很有可能分为同一个类别。所以当一个节点被激活后,它将很有可能对特征信息相似的一些节点产生间接作用,提供了一个平滑的信号给它们。这被我们定义为间接信息。
也就是说,我们喜欢所获取的节点集处于特征空间的不同区域,有一定的分散性质,这样可以使得未被标注的节点在相似的特征空间内能找到属于 σ ( S ) \sigma(S) σ(S)的节点。
所以我们定义如下的目标函数:
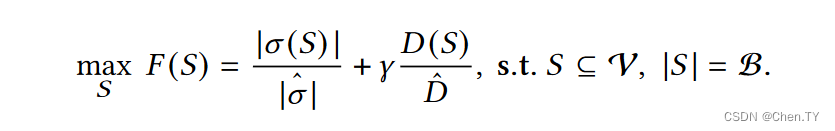
σ ( S ) \sigma(S) σ(S) 表示激活的个数, D ( S ) D(S) D(S)表示多样化程度, γ \gamma γ表示trade-off参数,分母为正则项。多样化程度一般用度量距离表示,比如特征空间的欧几里得距离。
3.3 Submodular Diversity Functions
由于pair-wise距离不是单调和具有子模的,因此我们需要新的diversity来保证贪心的正确率。
我们的目标是整个节点集V当中的所有点,都能在 σ ( S ) \sigma(S) σ(S)中找到相近的节点。基于这种考虑,本文提出了两个Submodular Diversity Function—NN based diversity和coverage based diversity。
Nearest Neighbor (NN)-based Diversity:我们对于每个节点的间接影响定义为到的距离。 d m a x = max u , v ∈ V d ( X u k , x v k ) d_{max} = \mathop{\max}_{u,v \in V} \ d(X_u^{k},x_v^{k}) dmax=maxu,v∈V d(Xuk,xvk)
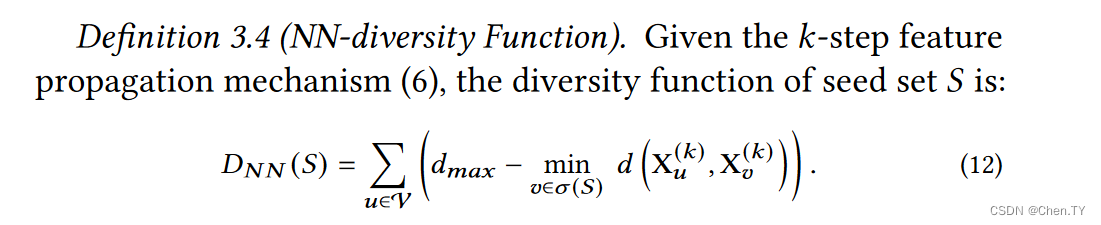
也就是定义多样化为V中点到我们选择集合内的点最近距离的总和。
Coverage-based Diversity : D N N : D_{NN} :DNN描述的是一个总距离,因此可能会导致方差过大的情况,所以coverage-based方法是一个减小方差的方法,即控制在r-radius的半径范围内进行计算。
G u = { v ∣ ∀ v ∈ V , d ( X u ( k ) , X v ( k ) ) ≤ r } G_u = \left\{ v| \forall v \in V, d(X_u^{(k)},X_v^{(k)}) \le r \right\} Gu={v∣∀v∈V,d(Xu(k),Xv(k))≤r}
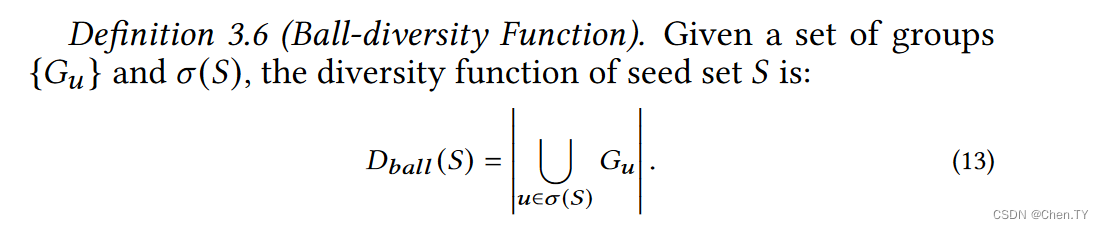
并且我们易得Ball-diversity function也是子模的,因为当|S|越大,说明它的边际效用越低,因为已经有很多的节点被激活了。
简单的总结一下,diversified influence function就是包含了直接影响力和间接影响力的一个函数,覆盖集由图上的传播结构和特征空间的相似性来共同决定,这也是和传统方法不同的地方。
3.4 Selection Algorithm
文中的伪代码已经给出,这个贪心算法比较简单。值得注意的是,当我们选出了一个节点后,需要用新的节点集更新函数值。然后我们根据marginal gain选择下一个节点。由于单调性和子模性质,我们的答案是有一定精度保证的。
Efficiency Optimization:相比learning算法,本文的算法不用大量神经网络的计算。并且可以通过一些过滤手法,筛选出许多不重要的节点。
4 EXPERIMENTS
该算法针对的是节点分类问题,值得一提的是,由于算法基于的是GNN中的message-passing,所以这个算法将能被轻松使用到大部分基于空域的GNN模型当中。
具体的实验细节和结果可以查看原文。
5 CONCLUSION
GNN是新兴的深度学习模型,是在图上应用神经网络模型的要求下自然产生的。对于GNN训练来说,高效和可扩展的数据选择要求很高,但由于其固有的复杂性,仍然具有挑战性。本文通过将GNN数据选择与社会影响力最大化联系起来,倡导了一种新的视角。通过展示这种联系的可行性和潜力,Grain代表了这个方向上的关键一步。为此,本文定义了一个新的特征影响模型,以利用GNN的common pattern,并提出了新的多样性函数。实验表明,Grain在模型性能和效率方面都远远超过了baseline。
Reference
的可行性和潜力,Grain代表了这个方向上的关键一步。为此,本文定义了一个新的特征影响模型,以利用GNN的common pattern,并提出了新的多样性函数。实验表明,Grain在模型性能和效率方面都远远超过了baseline。
Reference
[1] Representation Learning on Graphs with Jumping Knowledge Networks



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











