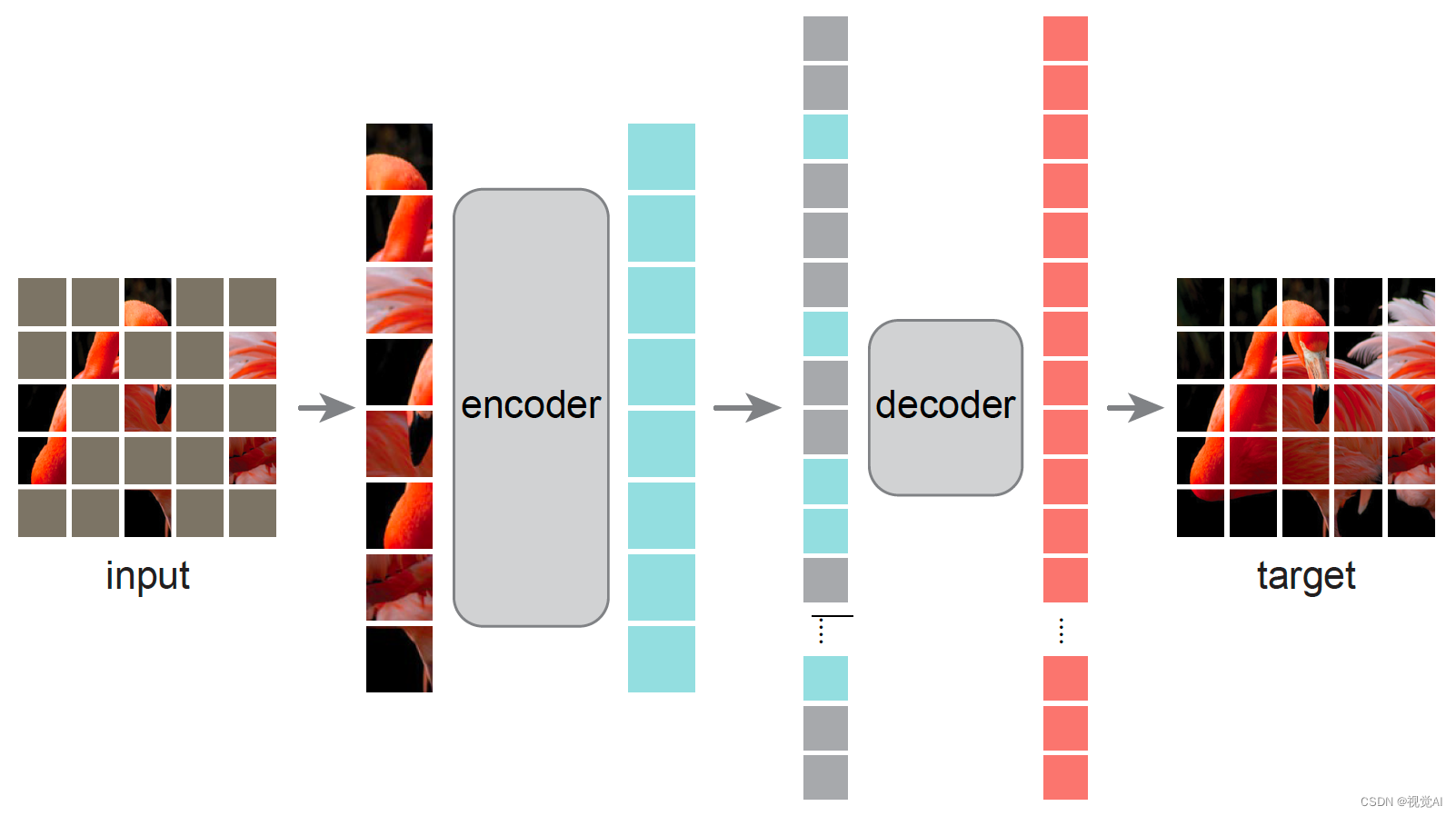
参考链接:https://zhuanlan.zhihu.com/p/518608011 (MAE, Kaiming He et al.)由于其从丰富的未标记数据中学习有用表示的能力而重新引起了人们的兴趣。直到最近,MAE及其后续工作已经推进了最先进的技术,并在研究(特别是视觉研究)中提供了有价值的见解。在这里,列出了MAE之后或同时进行的几项后续工作,以启发未来的研究。 Awesome Masked Autoencoders Fig. 1. Masked Autoencoders from Kaiming He et al. Vision 🔥Masked Autoencoders Are Scalable Vision Learners :octocat: :octocat:</









 超级会员免费看
超级会员免费看


 本文整理了Kaiming He等人提出的Masked Autoencoders(MAE)及其后续工作,展示了在图像处理领域的最新进展。SimMIM提供了一个简单但有效的框架,超越了先前的SOTA基准;BEiT则引入了BERT式的预训练方法到图像Transformer中。这些工作在无监督学习、预训练和图像表示方面取得了显著成果,推动了自动驾驶、医疗影像分析和视觉Transformer等多个领域的技术进步。
本文整理了Kaiming He等人提出的Masked Autoencoders(MAE)及其后续工作,展示了在图像处理领域的最新进展。SimMIM提供了一个简单但有效的框架,超越了先前的SOTA基准;BEiT则引入了BERT式的预训练方法到图像Transformer中。这些工作在无监督学习、预训练和图像表示方面取得了显著成果,推动了自动驾驶、医疗影像分析和视觉Transformer等多个领域的技术进步。

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



 5900
3239
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
5900
3239
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








