







基本模式
本节介绍基本模式和解决方案,它们是 SPARQL 查询的主要组成部分。
解决方案
在 SPARQL 查询中,"解决方案"指的是变量与值之间的一组配对。在一个 SELECT 查询中,解决方案直接作为查询结果集公开出来(在应用了排序/限制/偏移等操作之后)。而其他查询形式则使用这些解决方案来构建一个图形。解决方案是描述模式匹配的方式,即变量必须取哪些值,才能使一个模式得以匹配。
在 SELECT 查询中,查询返回的是一系列解决方案,每个解决方案包含了在查询中定义的变量及其对应的值。这些解决方案可以被用于从查询结果中提取信息。在其他查询形式(如CONSTRUCT、DESCRIBE、ASK)中,解决方案用于构建查询结果的图形表示。
第一个查询示例只有一个解决方案。将模式改为第二个查询: (q-bp1.rq):
SELECT ?x ?fname
WHERE {?x <http://www.w3.org/2001/vcard-rdf/3.0#FN> ?fname}
在上面给定的SPARQL查询中, ?fname 和 ?x 都是变量。在SPARQL查询中,以问号(?)开头的标识符被视为变量。该语句有4个解决方案,每个VCARD名称属性对应一个数据源中的三元组。
----------------------------------------------------
| x | fname |
====================================================
| <http://somewhere/RebeccaSmith/> | "Becky Smith" |
| <http://somewhere/SarahJones/> | "Sarah Jones" |
| <http://somewhere/JohnSmith/> | "John Smith" |
| <http://somewhere/MattJones/> | "Matt Jones" |
----------------------------------------------------
Java 代码如下:
package come.xbmu.sparql;
import org.apache.jena.query.Query;
import org.apache.jena.query.QueryExecution;
import org.apache.jena.query.QueryExecutionFactory;
import org.apache.jena.query.QueryFactory;
import org.apache.jena.query.QuerySolution;
import org.apache.jena.query.ResultSet;
import org.apache.jena.rdf.model.Model;
import org.apache.jena.rdf.model.ModelFactory;
public class Test02 {
static final String inputFileName = "java01/src/main/java/come/jena/rdf/vc-db-1.rdf";
public static void main(String[] args) {
// Load RDF data into a model
Model model = ModelFactory.createDefaultModel();
model.read(inputFileName); // Load your RDF data file
// Define a SPARQL query
String queryString =
"PREFIX pr:<http://www.w3.org/2001/vcard-rdf/3.0#>" +
" SELECT ?x ?fname WHERE { ?x pr:FN ?fname }";
Query query = QueryFactory.create(queryString);
// Execute the query
try (QueryExecution qexec = QueryExecutionFactory.create(query, model)) {
ResultSet results = qexec.execSelect();
// Process the query results
while (results.hasNext()) {
QuerySolution soln = results.nextSolution();
//System.out.println(soln);
System.out.println("x: " + soln.get("x") + " | fname:" + soln.get("fname"));
}
}
catch (Exception e){
e.printStackTrace();
}
}
}
运行结果:
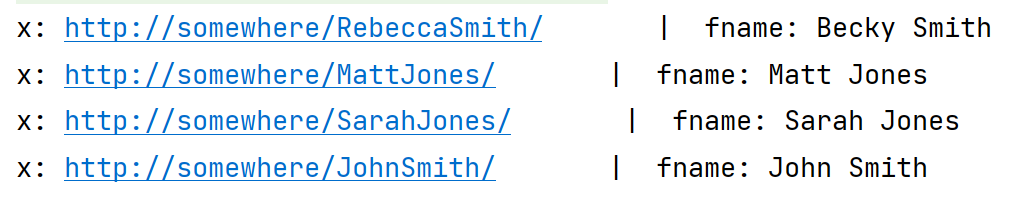
到目前为止,通过三元组模式和基本模式,在每个解决方案中,每个变量都会被定义。一个查询的解决方案可以看作是一张表,但在一般情况下,它是一张并不是每一行都对每一列都有一个值的表。对于给定的 SPARQL 查询,所有的解决方案不必在每个解决方案中为所有变量提供值,这一点我们稍后会看到。这说明了在 SPARQL 查询中,解决方案的数据结构可以是不规则的,不同的解决方案可能会为不同的变量提供值。
基础模式
基本模式是一组三元组模式。当这些三元组模式中的所有模式都使用相同的值来匹配每次使用具有相同名称的变量时,基本模式将会匹配成功。
SELECT ?givenName
WHERE
{ ?y <http://www.w3.org/2001/vcard-rdf/3.0#Family> "Smith" .
?y <http://www.w3.org/2001/vcard-rdf/3.0#Given> ?givenName .
}
这个查询(q-bp2.rq)涉及两个三元组模式,每个三元组模式都以 ". " 结尾(但最后一个模式后面的点可以省略,就像在一个三元组模式示例中一样)。每个三元组模式匹配的变量 y 必须相同。解决方案如下:
-------------
| givenName |
=============
| "John" |
| "Rebecca" |
-------------
Java 代码如下:
package come.xbmu.sparql;
import org.apache.jena.query.Query;
import org.apache.jena.query.QueryExecution;
import org.apache.jena.query.QueryExecutionFactory;
import org.apache.jena.query.QueryFactory;
import org.apache.jena.query.QuerySolution;
import org.apache.jena.query.ResultSet;
import org.apache.jena.rdf.model.Model;
import org.apache.jena.rdf.model.ModelFactory;
public class Test02 {
static final String inputFileName = "java01/src/main/java/come/jena/rdf/vc-db-1.rdf";
public static void main(String[] args) {
// Load RDF data into a model
Model model = ModelFactory.createDefaultModel();
model.read(inputFileName); // Load your RDF data file
// Define a SPARQL query
String queryString = "SELECT ?givenName " +
"WHERE { ?y <http://www.w3.org/2001/vcard-rdf/3.0#Family> \"Smith\"." +
"?y <http://www.w3.org/2001/vcard-rdf/3.0#Given> ?givenName.}";
Query query = QueryFactory.create(queryString);
// Execute the query
try (QueryExecution qexec = QueryExecutionFactory.create(query, model)) {
ResultSet results = qexec.execSelect();
// Process the query results
while (results.hasNext()) {
QuerySolution soln = results.nextSolution();
//System.out.println(soln);
System.out.println("?givenName: " + soln.get("?givenName"));
}
}
catch (Exception e){
e.printStackTrace();
}
}
}
运行结果:

QNames
有一种使用前缀书写长 URI 的简写机制。上面的查询可以更清楚地写成查询 (q-bp3.rq):
PREFIX vcard: <http://www.w3.org/2001/vcard-rdf/3.0#>
SELECT ?givenName
WHERE
{ ?y vcard:Family "Smith" .
?y vcard:Given ?givenName .
}
这是一种前缀机制,即从前缀声明中获取的部分和从“:”后面获取的部分的URI会被连接在一起。虽然这不是XML qname的严格定义,但它使用了RDF的规则,通过连接这些部分来将qname转换为URI。这种机制在RDF中用于将简化的qname表示法转换为完整的URI,以便更方便地表示和处理资源的标识。
空白结点
稍微修改查询以返回变量 y(q-bp4.rq):
PREFIX vcard: <http://www.w3.org/2001/vcard-rdf/3.0#>
SELECT ?y ?givenName
WHERE
{ ?y vcard:Family "Smith" .
?y vcard:Given ?givenName .
}
结果将会出现空白节点:
--------------------
| y | givenName |
====================
| _:b0 | "John" |
| _:b1 | "Rebecca" |
--------------------
开头的奇怪 qnames “ _:.”,它们不是空白节点的内部标签,而是 ARQ 打印它们时分配的 :b0、:b1 等标签,用于显示两个空白节点是否相同。虽然在使用 Java API 时可以使用空白节点的内部标签,但它并没有显示该标签。
Java 代码如下:
import org.apache.jena.query.Query;
import org.apache.jena.query.QueryExecution;
import org.apache.jena.query.QueryExecutionFactory;
import org.apache.jena.query.QueryFactory;
import org.apache.jena.query.QuerySolution;
import org.apache.jena.query.ResultSet;
import org.apache.jena.rdf.model.Model;
import org.apache.jena.rdf.model.ModelFactory;
public class Test02 {
static final String inputFileName = "java01/src/main/java/come/jena/rdf/vc-db-1.rdf";
public static void main(String[] args) {
// Load RDF data into a model
Model model = ModelFactory.createDefaultModel();
model.read(inputFileName); // Load your RDF data file
// Define a SPARQL query
String queryString = "PREFIX pr:<http://www.w3.org/2001/vcard-rdf/3.0#>" +
"SELECT ?y ?givenName " +
"WHERE { ?y pr:Family \"Smith\"." +
"?y pr:Given ?givenName.}";
Query query = QueryFactory.create(queryString);
// Execute the query
try (QueryExecution qexec = QueryExecutionFactory.create(query, model)) {
ResultSet results = qexec.execSelect();
// Process the query results
while (results.hasNext()) {
QuerySolution soln = results.nextSolution();
//System.out.println(soln);
System.out.println( soln);
}
}
catch (Exception e){
e.printStackTrace();
}
}
}
运行结果:

Jena 官方文档:https://jena.apache.org/tutorials/sparql_basic_patterns.html

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









