









 本文介绍了TimescaleDB中创建和优化索引的最佳实践,包括如何针对离散和连续值的列创建索引,以及如何利用复合索引提高查询效率。文章详细解释了索引在超文本上的工作原理,以及如何通过添加WHERE子句来优化稀疏数据的索引。
本文介绍了TimescaleDB中创建和优化索引的最佳实践,包括如何针对离散和连续值的列创建索引,以及如何利用复合索引提高查询效率。文章详细解释了索引在超文本上的工作原理,以及如何通过添加WHERE子句来优化稀疏数据的索引。
1、创建索引
TimescaleDB支持PostgreSQL索引类型的范围,并且在超文本(PostgreSQL文档)上创建,更改或删除索引将同样传播到其所有组成块。
数据通过SQL 命令编制索引。例如,CREATE INDEX
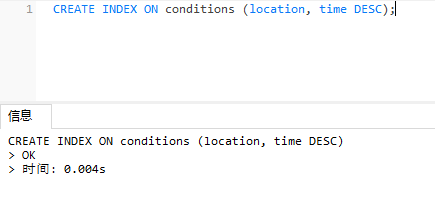
CREATE INDEX ON conditions (location, time DESC);
location:字段名称
conditions:表名
这可以在将表转换为超级表之前或之后完成。
提示:对于列通常为NULL的稀疏数据,我们建议在索引中添加一个子句(除非您经常搜索缺失的数据)。例如,WHERE column IS NOT NULL
CREATE INDEX ON conditions (time DESC, humidity)
WHERE humidity IS NOT NULL;
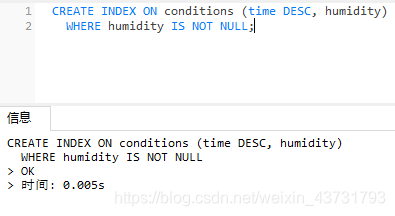
这创造了一个更紧凑,更有效的索引。
2、最佳实践
我们的经验表明,对于时间序列数据,最有用的索引类型取决于您的数据。
对于具有离散(有限基数)值的列的索引(例如,您最有可能使用“等于”或“不等于”比较器),我们建议使用这样的索引(使用我们的超文本作为示例):conditions
CREATE INDEX ON conditions (location, time DESC);
对于所有其他类型的列,即具有连续值的列(例如,您最有可能使用“小于”或“大于”比较器的位置),索引应采用以下形式:
CREATE INDEX ON conditions (time DESC, temperature);
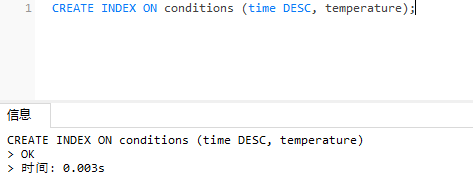
在索引中具有列规范允许按列值和时间进行有效查询。例如,上面定义的索引将优化以下查询:time DESC
SELECT * FROM conditions WHERE location = 'garage'
ORDER BY time DESC LIMIT 10
要理解为什么应该以这种方式定义复合索引,请考虑具有两个位置(“办公室”和“车库”)以及各种时间戳和温度的示例:
索引将按排序顺序组织如下:(location, time DESC)
garage-4
garage-4
garage-3
garage-2
garage-1
office-3
office-2
office-1
索引将按排序顺序组织如下:(time DESC, location)
4-garage
3-garage
3-office
2-garage
2-office
1-garage
1-office
可以认为索引的btree是从最高位向下构造的,因此它首先匹配第一个字符,然后匹配第二个等,而在上面的示例中,它们被方便地显示为两个单独的元组。
现在,使用类似的谓词,顶部使用起来要好得多:来自给定位置的所有读数都是连续的,因此索引的第一位精确地从“车库”中找到所有指标,然后我们可以使用任何其他时间谓词来进一步缩小选定的集合范围。对于后者,您必须查看所有时间记录[1,4],然后再次在每个记录中找到合适的设备。效率低得多。
WHERE location = 'garage' and time >= 1 and time < 4
另一方面,考虑我们的条件是否相反,特别是如果条件匹配更多的值。您仍然需要搜索与谓词匹配的所有时间值集合,但在每个值中,您的查询还会抓取(可能很大的)值的子集,而不是只捕获一个不同的值。temperature > 80
PS:要将索引定义为UNIQUE或PRIMARY KEY,时间列以及分区列(如果存在)必须是索引的一部分。也就是说,使用我们的运行示例,您可以仅在{ time,location } 字段定义唯一索引,或者包含其他列(例如,温度)。也就是说,我们发现时间序列数据中的UNIQUE索引比传统的关系数据模型更不普遍。
默认索引
默认情况下,TimescaleDB会在创建超文本时自动为数据创建时间索引。
CREATE INDEX ON conditions (time DESC);
此外,如果该命令除了指定时间(例如,列)之外还指定了可选的“空间分区” ,TimescaleDB将自动创建以下索引:create_hypertablelocation
CREATE INDEX ON conditions (location, time DESC);
执行命令时可以覆盖此默认行为。create_hypertable

















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









