







 本文介绍了如何基于支持向量机(SVM)技术构建一个多因子量化投资模型,该模型利用沪深300成分股的交易与财务数据,结合数据清洗、预处理和特征提取,训练并测试SVM模型以预测股价上涨概率。通过网格搜索法优化SVM参数,并基于预测结果构建投资策略和回测框架,结果显示,该模型在收益率和风险控制方面表现出色。
本文介绍了如何基于支持向量机(SVM)技术构建一个多因子量化投资模型,该模型利用沪深300成分股的交易与财务数据,结合数据清洗、预处理和特征提取,训练并测试SVM模型以预测股价上涨概率。通过网格搜索法优化SVM参数,并基于预测结果构建投资策略和回测框架,结果显示,该模型在收益率和风险控制方面表现出色。
要求开发一个基于支持向量机技术的多因子量化投资模型,以近五年沪深300成分股的交易与财务数据为样本,结合大数据相关技术进行数据清洗,整理,存储,并构建投资策略与回测框架,输出量化投资模型的结果,为投资者选股与择时提供参考信号,具体要求如下:
- 从金融数据库(CSMAR、jqdata、tushare)获得2014-2020年股票行情数据以及公司的财务数据利用数据构造相关选股因子,并进行数据清洗、数据预处理等操作
- 以上述选股因子作为特征,并以下一期收益率数据作为标签,选取前 70%的数据作为训练集,后30%的数据样本作为测试集,构建支持向量机模型(包括提取特征因子、标签、分割数据集、模型参数寻优、利用样本训练模型、测试模型以及模型评价等步骤)来预测股价未来的上涨概率。
- 参数优化:本文选用网格搜索法来对SVM模型的重要参数进行优化。
- 构建投资策略:根据SVM 模型预测的未来上涨概率的预测值进行等权重选股投资。
- 参考tradebacker框架进行回测设计,根据上述选股结果和投资策略,构建模拟交易的回测框架,并对评价策略回测结果在收益以及风险方面的表现。
1 数据获取与预处理
本文基于聚宽(JQDATA)平台提供的数据支持,利用其python版API编写代码,在线获取相关数据,数据量的选取需要有代表性,且样本余越充足,得到的结果实用性就越强,模型也就越有效,因此在充分考虑上述因素与数据可得性的前提下,数据选取如下:
股票池:本文在沪深300指数(HS300)成分股里进行选股,剔除ST股票、剔除上市月份不足三个月的股票以及停牌退市的股票,同时考虑到银行这一金融机构的特殊性,许多数据无法获得以及财务指标具有行业特性等原因,因此剔除银行行业股票,剩下股票为股票池,每个股票为一个样本。
样本区间:2014年12月31日至2020年12月31日之间的月末截面数据。
1.1 风险因子的选取
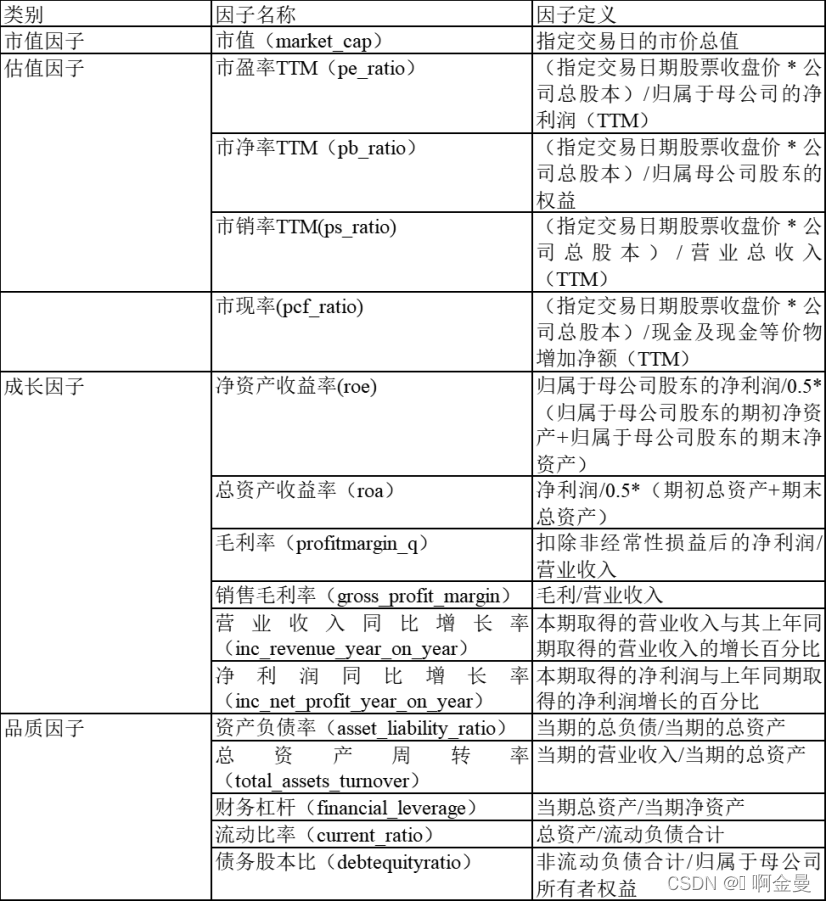
3.1.2 数据预处理
- 百分位法去极值:对每一个风险指标进行升序排列,最小的百分之10和最大的10%定义为极值,即超过[10%,90%]以外的数据为极值,10%对应的值为下临界值,90%对应的值为上临界值,对极值进行缩尾处理,即将所有大于上临界值的值用上临界值来替代,所有小于下临界值的值用下临界值来替代。
- 缺失值处理:调用sklearn.impute中的SimpleImputer 库进行缺失值填充,首先获取各个行业每个风险因子的平均值,然后用行业均值对缺失值进行填充。
- 行业市值中性化处理:中性化实质是对因子进行提纯,去除掉由共同特质带来的多余的风险暴露,其中最常见的是行业与市值中性化。由于各个行业的特质性,不同行业的财务指标有很大差异,直接进行对比没有可比性,例如不同行业之间的市净率无法比较大小,因为需要考虑行业的特性,有可能某一个行业由于重资产的特性,导致普遍市净率偏高,因此需要剔除行业影响才能使得不同个股间的因子具备可比性。同理,市值这一因素也与各个指标之间具有很强的相关性,因此需要剔除不同行业与市值大小导致的误差影响,,具体做法是将因子数据对市值变量和行业哑变量做线性回归,得到的残差即为去除行业与市值影响的因子序列。
- 均值方差标准化:标准化的目的是去除不同指标之间量纲的影响,调用sklearn.preprocessing中的StandardScaler对数据进行均值方差规范化,(观察值-均值)/标准差得到近似于标准正态分布的序列。
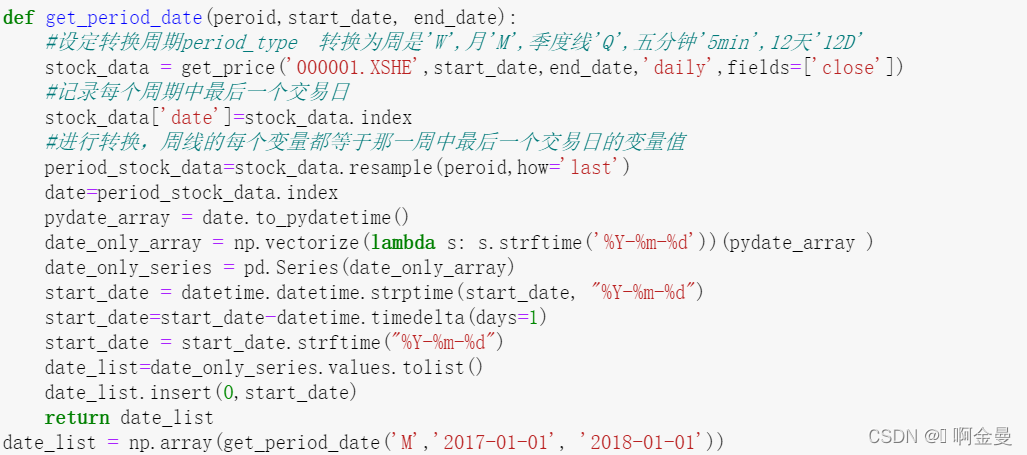
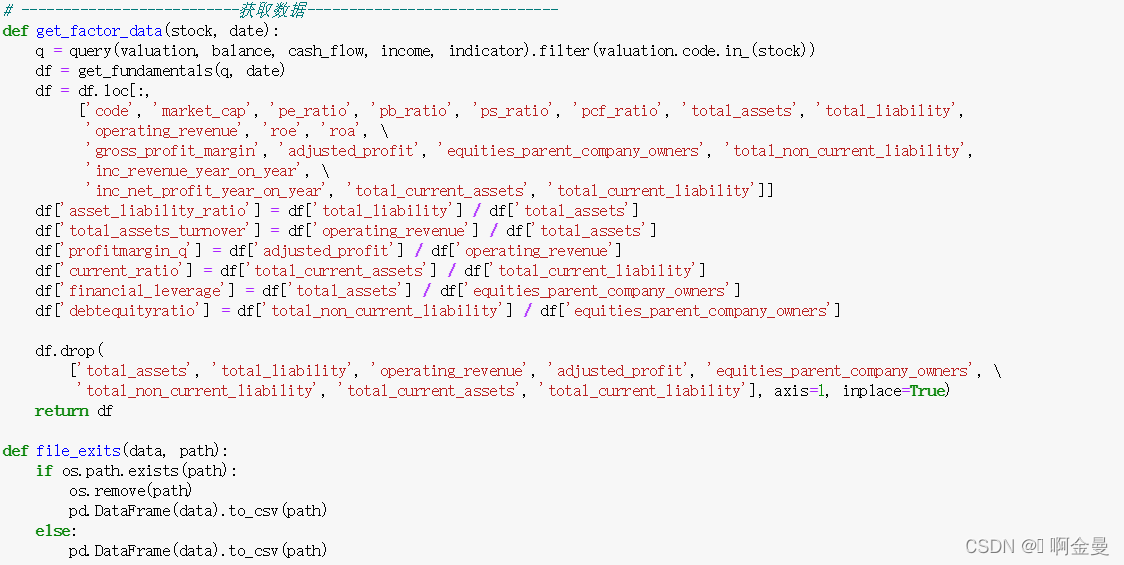
代码实现:



2 特征值、分割数据集与标签标记
2.1特征和标签的提取
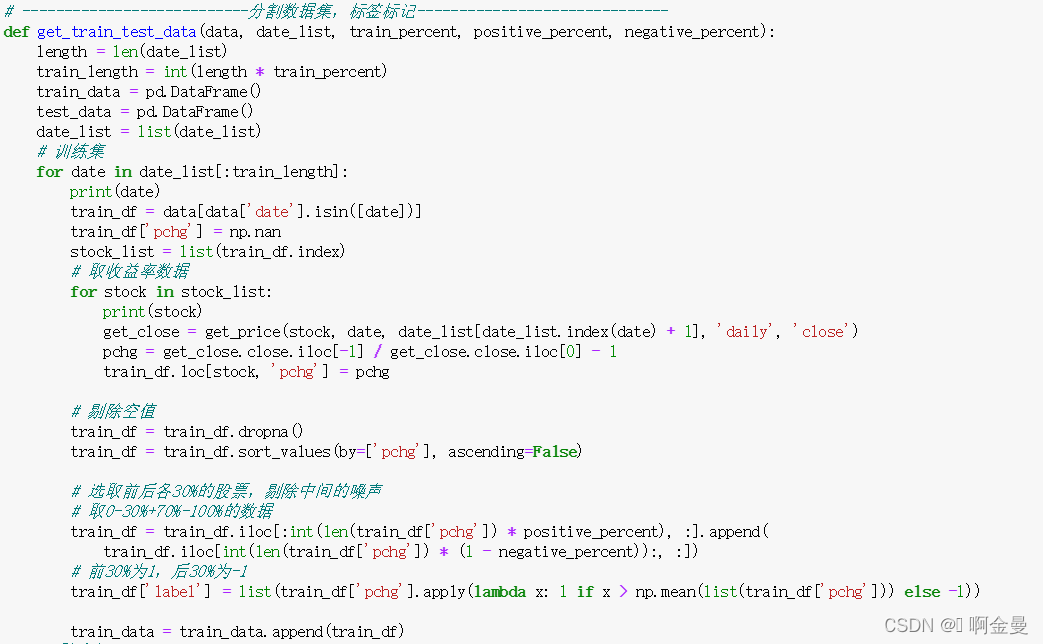
计算个股下个月的收益率,收益率(pchg)=(当月最后一个交易日收盘价—下月最后一个交易日收盘价)-1,将pchg设为Y,也就是样本标签,每个月最后一个交易日提取15个风险因子的数据,进行预处理后作为样本特征,即Xi。
2.2分割数据集
构建机器学习方法,首先要训练模型,再用模型进行测试,因此先要对数据集进行分割,将其分为训练集和数据集,本文按照70%的比例进行分割,即2014年12月31日至2018年10月30日的数据集作为训练数据集,至2020年12月31日的数据集为测试数据集。
2.2标签标记
由于SVM模型本质是分类器,因此需要将收益率(pchg)指标数据转换成分类标签,在每一个月末,将收益率从高到低进行排序,收益率排在前30%的股票设为正类,此时Y=1,后30%的股票设为反类,此时Y=-1。
代码实现:

3 模型的训练与测试
3.1训练支持向量机模型的步骤
(1)根据前人经验表明,采用K折交叉验证法可以更好地实现模型参数设计,做法是将数据分成K组,随机选择训练集中10%的样本作为交叉验证集,剩下90%作为训练集。
(2)利用训练集建立SVM模型,利用训练好的模型预测交叉验证集的标签
(3)将预测的标签结果与实际的标签结果进行对比,从而得到模型的正确率与AUC等评价指标。
(4)重复上述步骤N次,用评价指标的均值判断模型的有效性。
3.2利用网格搜索法参数寻优
在构建机器学习模型的过程中,找到使模型表现最好的参数直接决定了模型的优劣,因此参数寻优是关键步骤,而网格搜索法是常用的参数寻优方法,且被多篇文献证明是对支持向量机模型的参数寻优十分有效。
网格搜索法的原理是:
(1)根据经验,确定出可能得到较优结果的待搜索的范围。
(2)将需要搜索的参数值网格离散化,再设定搜索长度,按照搜索参数的不同增长方向生成网格,网格中的节点就是对应的参数对。
(3)在待搜索的范围里对每个参数都取一系列的待检验的离散值,分别将所有可能的参数值组合用来训练模型并对模型的有效性以及推广能力进行评价。
(4)选择能使训练模型得到最好结果的参数作为最优的参数。
综上所述,网格搜索法就是采用暴力式地穷举待优化的参数组合值,然后评估不同参数组合下的模型性能,选出获得最优参数组合。
综上,需要优化的参数有:
(1)惩罚系数C,它表示SVM模型对错误分类的容忍度,当C取值较大时,模型对误差的容忍度较低,此时模型将尽可能以训练集的正确率出发,保证分类的正确,这样可能会导致过拟合现象,尽管训练集准确率高,但是模型预测的测试集的正确率并不高;当C取值较小时,则模型能够容忍一定的误差,模型将倾向于以最大间隔的原则进行分类,但会牺牲一定的训练集和测试机的正确率。
(2)核函数gamma值,由于高斯核函数和sigmoid核函数处理大样本时效果更好,高斯核函数和多项式核在处理向量维数较高的问题上效果更好,因此核函数的选择也是需要进行优化的,判断哪种核函数更适合当下的数据集特征。其中,高斯核、sigmoid核和多项式核都含有一个重要参数——γ值,gamma值越大,说明样本在空间中散布越稀疏,数据点的间隔越远,越容易被分类平面分开,训练集正确率也就越高,但也容易出现过拟合现象。
网格搜索法对SVM模型参数寻优流程如图二所示:

图3.2 网格搜索法的寻优流程
具体代码如下:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









