 DiffusionDet:基于扩散模型的目标检测框架
DiffusionDet:基于扩散模型的目标检测框架





提出了一种新的框架——DiffusionDet,它将目标检测定义为一个从有噪声的盒子到目标盒子的去噪扩散过程。在训练阶段,目标盒从真实值盒扩散到随机分布,模型学会了逆转这个噪声过程。
在推理中,该模型以渐进的方式将一组随机生成的框细化为输出结果。
贡献:
- 我们将目标检测制定为生成式去噪过程,这是据我们所知第一个将扩散模型应用于目标检测的研究。
- 我们的噪声到框检测范例具有几个吸引人的特性,例如动态框的解耦训练和评估阶段以及迭代评估。
- 我们对COCO、CrowdHuman 和LVIS 基准进行了广泛的实验。与之前成熟的检测器相比,DiffusionDet 取得了良好的性能,尤其是跨不同场景的zero-shot transferring。
1、介绍
之前存在的问题:
DETR提出了可学习的目标查询,消除了手工设计的组件,建立了端到端检测管道,引起了极大的关注。虽然这些工作实现了简单而有效的设计,但它们仍然依赖于一组固定的可学习查询。一个自然的问题是:有没有一种更简单的方法,甚至不需要可学习查询的代理?
为了回答这个问题,我们设计了一个新的框架,它可以直接从一组随机盒子中检测对象。从纯随机盒子开始,不包含训练阶段需要优化的可学习参数,我们期望逐步细化这些盒子的位置和大小,直到它们完美覆盖目标对象。这种噪声盒方法既不需要启发式目标先验,也不需要可学习查询,进一步简化了目标候选,并推动了检测基线的发展。
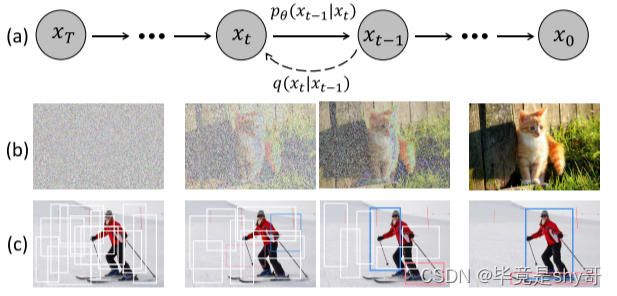
图1。用于目标检测的扩散模型。(a)扩散模型,其中q是扩散过程,pθ是相反过程。(b)图像生成任务的扩散模型。©我们建议将目标检测作为去噪扩散过程,从有噪声的箱子到目标箱子。
我们的动机如图1所示。我们认为noise-to-box范式的原理类似于去噪扩散模型中的noise-to-image过程,这是一类基于似然的模型,通过学习的去噪模型逐渐去除图像中的噪声,从而生成图像。扩散模型在许多生成任务中都取得了很大的成功,并开始在图像分割等感知任务中得到探索。然而,就我们所知,还没有先前技术成功地将其应用于目标检测。
在这项工作中,我们提出了 DiffusionDet,它通过将检测任务作为 图像中 边界框的位置(中心坐标)和大小(宽度和高度)在空间上的 生成任务,使用扩散模型来处理对象检测任务。
在训练阶段,将由方差表控制的高斯噪声添加到真实图片框以获得噪声框。
然后,这些噪声框用于从主干编码器的输出特征图中裁剪 感兴趣区域(RoI)的特征,例如 ResNet 、Swin Transformer 。
最后,这些 RoI 特征被送到检测解码器,该解码器经过训练可以预测无噪声的真实框。通过这个训练目标,DiffusionDet 能够从随机框中预测真实框。
在推理阶段,DiffusionDet 通过反转学习的扩散过程来生成边界框,该过程将噪声先验分布调整为边界框上的学习分布。
作为一种概率模型,DiffusionDet 具有令人着迷的灵活性优势,即我们可以训练一次网络,并在推理阶段的不同设置下使用相同的网络参数,主要包括:
(1)动态框数。利用随机框作为候选对象,我们解耦了 DiffusionDet 的训练和评估阶段,即我们可以用 Ntrain \ N_ {train}\, Ntrain 个随机框训练 DiffusionDet,同时用 Neval \ N_ {eval}\, Neval 个随机框评估它,其中 Neval \ N_ {eval}\, Neval 是任意的,不需要等于 Ntrain \ N_ {train}\, Ntrain<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1637
1637







 到【灌水乐园】发言
到【灌水乐园】发言









