




 本文档详细介绍了如何在本地设置和运行一个中文命名实体识别(NER)项目,基于ALBERT模型。首先,你需要克隆项目仓库,并从指定链接下载ALBERT的中文模型。接着,确保拥有合适的GPU运行环境,如tensorflow1.15.5和对应的CUDA/cudnn版本。然后,在虚拟环境中安装依赖。创建run.py文件以执行训练、评估和预测任务。项目中包含训练、评估和预测所需的不同文件,最终的预测结果会写入label_test.txt。
本文档详细介绍了如何在本地设置和运行一个中文命名实体识别(NER)项目,基于ALBERT模型。首先,你需要克隆项目仓库,并从指定链接下载ALBERT的中文模型。接着,确保拥有合适的GPU运行环境,如tensorflow1.15.5和对应的CUDA/cudnn版本。然后,在虚拟环境中安装依赖。创建run.py文件以执行训练、评估和预测任务。项目中包含训练、评估和预测所需的不同文件,最终的预测结果会写入label_test.txt。
1.首先将中文ner项目克隆到本地
项目地址:https://github.com/ProHiryu/albert-chinese-ner
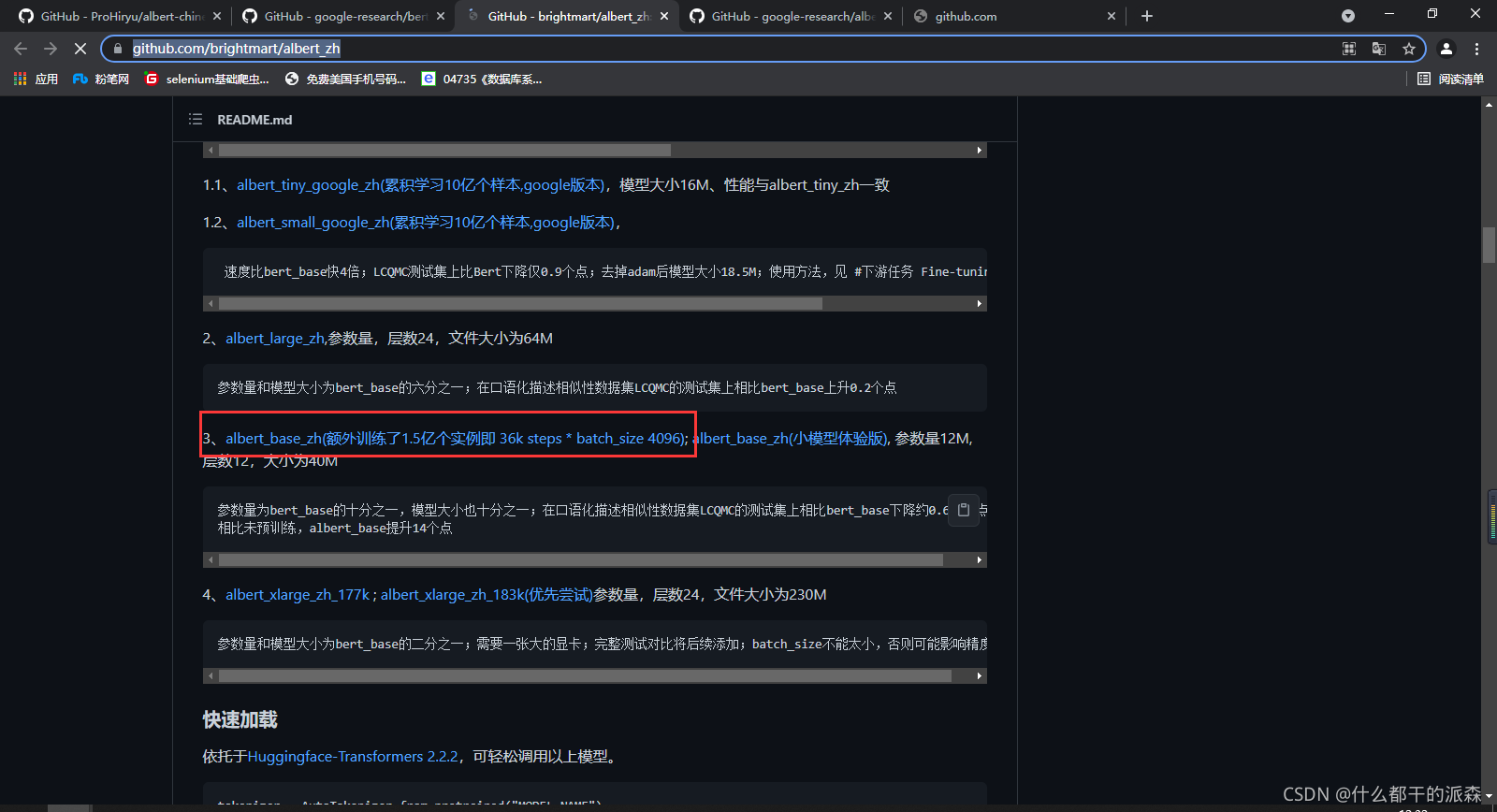
2.去ALBERT下载中文模型
地址:https://github.com/brightmart/albert_zh
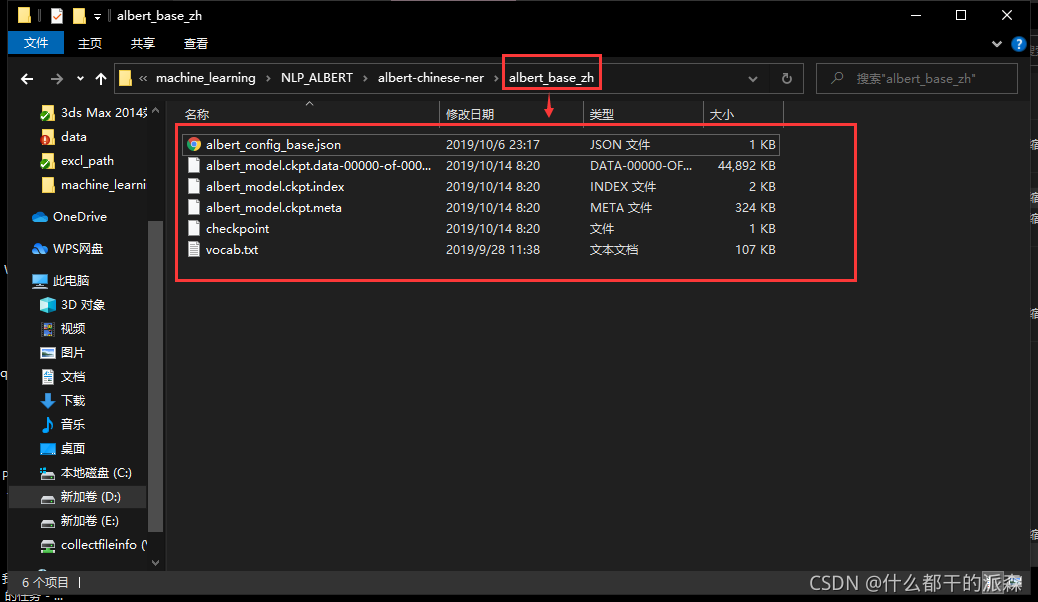
解压后放入项目下新建的 albert_base_zh 文件夹中
3.安装gpu运行环境
建议使用tensorflow1.15.5,因此需要下载并安装cuda10.0 和 cudnn7.6(如果没有显卡的话不用安装这两个)
4.配置虚拟环境
# gpu训练
pip install tensorflow-gpu==1.15.5
# 没有显卡安装这个
pip install tensorflow==1.15.5
5.创建命令执行脚本
目录下新建run.py文件,内容如下
import os
cmd = ' '.join([
'python albert_ner.py',
'--task_name ner',
'--do_train true', # 训练
'--do_eval true', # 评估
# '--do_predict true', # 预测
'--data_dir data',
'--vocab_file ./albert_config/vocab.txt',
'--bert_config_file ./albert_base_zh/albert_config_base.json',
'--max_seq_length 128',
'--train_batch_size 16',
'--learning_rate 2e-5',
'--num_train_epochs 3',
'--output_dir albert_base_ner_checkpoints'
])
os.system(cmd)
先注释掉预测,执行训练、评估,
然后再注释掉训练、评估,进行预测就好了
6.补充说明
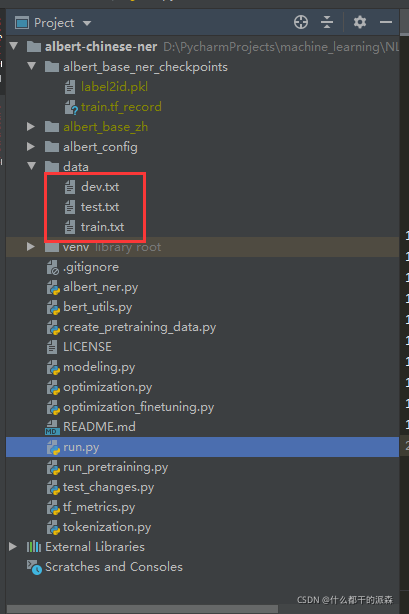
1.dev.txt是待评估文件
train.txt是待训练文件
test,txt是待预测文件
2.预测结果在label_test.txt中
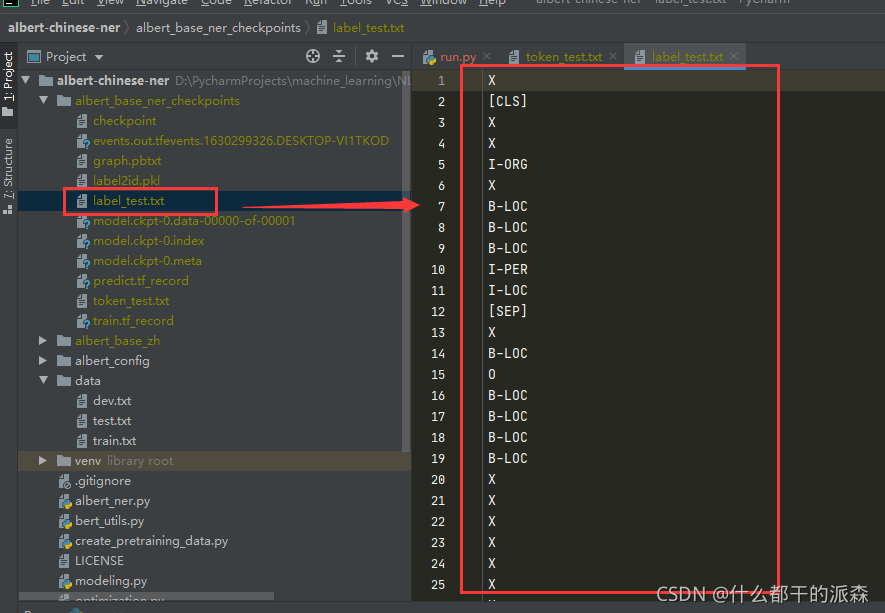
3.项目来自 github,贡献者如下





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











