






Hadoop之详解
Hadoop面试题: link.
1.查看依赖包源码,出现以下错误
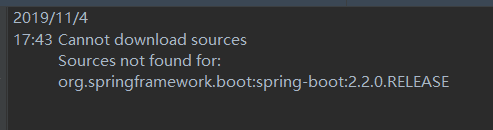
解决方法
链接: link.
入门
1.常用端口号
HDFS NameNode 内部通讯端口:8020、9000、9820
HDFS NameNode 对用户得查询端口:9870
Yarn查看任务运行情况得:8088
历史服务器:19888
2.常用配置文件
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
workers
2.集群
2.1集群的配置
集群部署规划
- NameNode和SecondaryNameNode 不要安装在同一台服务器上
- ResourceManager也很消耗内存,不要和NameNode、secondaryNameNode配置在同一台机器上
- 一个集群中,有一个ResourceManager和一个secondaryNameNode和一个NameNode
- 一个集群中的老大是ResourceManager,一台服务器上的老大是NodeManager,一个任务的老大是mrAppMaster
- 集群中,每台服务器上都有一个NodeManage和多个Datanodes
- 每个Datanodes上存储多个数据块
- container容器:容器就相当于一个小电脑,在拉镜像的时候,首先拉取的是centos或者Ubuntu,然后是javase等。他和宿主机共用一套硬件,但是是分开的。不同容器之间都是独立的。使用完就释放掉,和datanode没关系,datanode是存储数据的。为什么要用容器呢?
1.比如说某个应用程序只有在linux下才有,如果在windows下安装那么就需要配置环境,非常麻烦,这时候就可以开启一个容器,相当于一个linux系统,在windows下就可以开启容器,使用这个软件
2.在电脑1上写的程序想共用给其他电脑,那么就需要环境+代码完全一致,这时就可以把他封装为一个容器。
3.比如hadoop,是分布式计算框架,不同计算机之间交互。 - cpu:包括核、高速缓存等
- 线程:一个cpu一般会带动两个以上线程并发运行。可以理解为一个任务对应一个线程。
集群组成
| 项目 | Hadoop102 | Hadoop103 | Hadoop104 |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | DataNode SecondaryNameNode |
| YARN | NodeMamager | NodeMamager ResourceManager | NodeMamager |
2.2 HDFS、YARN、Mapreduce的关系
3HDFS
定义:本质是一个文件系统,但是其不只能存储文件,还可以进行分布式计算,HDFS分布式文件系统也是一个主从架构,主节点是我们的namenode,负责管理整个集群以及维护集群的元数据信息,从节点datanode,主要负责文件数据存储
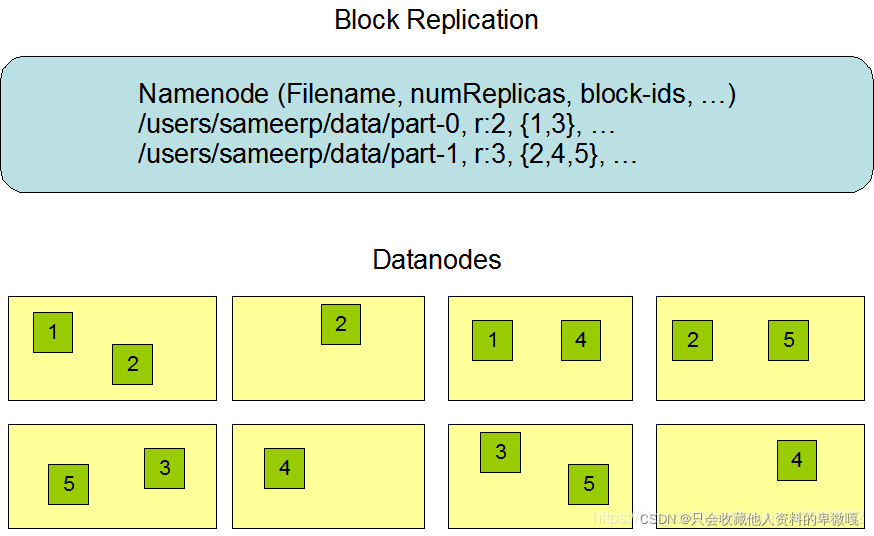
HDFS中包括NameNode和DataNode。
NameNode是整个文件系统目录,基于内存存储,存储的是一些文件的详细信息,比如文件名、文件大小、创建时间、文件位置等。
DataNode是文件的数据信息,也就是文件本身,但是是分割后的小文件(分块),以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和以及时间戳。
1.文件块大小
HDFS的文件在物理上是分块存储,不同的块可以在不同的服务器上,由datanode实际存储,所有datanode的元数据存储在namenode中,在企业中,一般是128m。
2.HDFS得shell操作
3.HDFS得读写流程
3.1写入数据的流程
相当于两个人的对话,目的是客户端要将数据传到集群上
- 首先,HDFS客户端要先创建一个分布式的文件系统(默认是本地local),向namenode请求,告诉它我要将某某文件传送到集群中的/use/atguigu/文件下
- namenode在接收到请求后,对其进行一个校验(不是谁想传什么就可以的),检查目录树是否可以创建文件(1)检查该客户端是否有权限写入(因为每一个文件都有所在的用户和用户组)(2)检查目录结构是否存在(如果该文件下,有这个文件,就不能再写入了)
- namenode检查之后,可以上传文件,对客户端有一个相应,告诉他可以上传
- 客户端接收到namenode的回应后,请求上传第一个块文件(block),并且请求namenode返回datanode的结点,因为集群上有很多结点,不是客户端想传到哪里都可以的,所以需要namenode给它返回来一个datanode,也就是上传的结点位置 往哪一个位置上传
- 然后namenode返回给客户端dn1,dn2,dn3三个结点,告诉客户端这三个节点可以存储数据(如何选择副本存储节点,首先选择本地节点,然后是同一个机架的其他节点,然后是其他机架的节点)
- 然后,客户端创建一个数据流(FSDataOutputFormat) 往出写数据了
重点 :如何写数据呢???采用流式发送
- 首先与保存此文件第一个数据块最近的Datanode建立传输通道,请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将整个通信管道建立完成
- dn1,dn2,dn3逐级应答客户端
- 应答之后,客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存中缓存),Datanode1中,一份数据往磁盘里面写,另一份在内存中直接传给下一个节点
- 发送的这个数据流里面,最小单位是packet(64k)
- 首先,传输数据流的时候,首先产生一个缓冲队列,存储的是chunk是512字节,加上4个字节的校验位,当它攒到64k的时候,就会成为一个packet(线形成chunk,然后形成packet,形成一个一个的packet之后,发送给datanode)
详细流程
如果要将一个200m的文件存到HDFS集群中
链接: link.
3.2读数据的流程
- 集群中有数据,集群中有 NameNode ,存储着元数据,有什么文件,块信息在哪,DataNode 存储的是真正的块信息。
- 客户端向NameNode请求读取集群的数据。
- 首先客户端创建一个对象,和NameNode进行交涉,创建DistributedFileSystem分布式系统对象进行访问
- 向NameNode请求下载文件
- NameNode首先判断这个对象有没有访问权限,然后检查集群上有没有这个文件,检查完毕后
- 向分布式系统对象返回目标文件的元数据
- 客户端开始读取数据,创建一个FSDataInputStream流对象,请求读取blk-1,选择节点最近的读取数据,同时要考虑当前节点的负载能力,读取完blk-1之后,开始请求读取blk-2。
- 串行读取,先读取blk-1,存储之后,再读取blk-2
- 最后关闭资源
4MapReduce框架原理
1.切片与MapTask并行度
- MapTask是开启越多越好吗,不是,因为开启的时间会更长
- MapTask由切片数决定,一个切片分配一个MapTask并行处理
- 默认下,切片大小= 块大小(块是物理存储单位,一般为128m)
- 每个文件单独切片
2.job提交流程
- job提交的代码:waitForCompletion()
- 然后submit(),进入提交流程
- 进入到提交的代码中,setUseNewAPI 处理的是新旧API的兼容性问题
- (1)然后到connet() 连接:如果和集群连接,则会有一个yarn客户端;如果和本地的客户端连接
- 进入到connect()之后,进入到 return new Cluster(getConfiguration())
- 初始化initialize()
- (2)提交job信息submitter.submitJobInternal()
- checkSpecs 检验是否给了输出参数,并且校验给出的输出路径是否存在
- Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf) 创建给集群提交数据的stag路径,生成一个临时路径
- JobID jobId = submitClient.getNewJobID() 每提交一个任务,就会创建一个独一无二的JobID
- copyAndConfigureFiles(job, submitJobDir):如果是集群模式,会提交jar包(把jar包拷贝给集群),如果是本地模型,则不会提交jar包
- writeSplits(job, submitJobDir) 计算切片个数
maps = writeNewSplits(job, jobSubmitDir) 进入到方法里
input.getSplits(job),JobSplitWriter.createSplitFiles(jobSubmit,),在staging路径里面加上了split切片信息,真正形成了split切片文件 - conf.setInput
- writeConf(conf,submitJobFile) 提交xml信息,默认配置提交三样东西,split,xml,jar包(如果是集群模式)
- status由define变成running,开始运行job
3.切片流程
FileInputFormat实现类:下面包括TextFileInputFormat和CombineFileInputFormat
- 1.每个文件单独切片
- 2.切片大小和块大小相同
- 3.如果想改变切片大小,把最小值调成大于32m,那么切片大小就大于32m,如果最大值调成小于32m,那么切片大小就小于32m,为什么是32m,因为本地模式的块大小默认是32m,集群模式是128m
- 4.如果是32.1m的文件,物理上仍然在两块上,但是只有一个切片,只存一片,相除大于1.1倍,分成两片,如果小于1.1倍,分成一片处理 while(((double) bytesRemaining)/splitsize >SPLIT_SLOP)
- isSpiltable(Job,Path),说的是文件是否支持切片,有的情况,比如压缩就不支持切片
切片过程:
- 首先,程序要先找到存储数据的目录
- 然后,开始遍历目录下的每一个文件
- 遍历第一个文件
-
- 获取文件大小fs.sizeOf(ss.txt)
-
- 计算切片大小
-
- 默认情况下,切片大小等于块大小
-
- 将切片信息写入到一个切片规划文件中split文件
-
- 整个切片的核心过程在getSplit()方法中完成
-
- InputSplit只记录了切片的元数据信息,比如起始位置等
- 提交切片规划文件到YARN上,YARN上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数
TextInputFormat
CombineInputFormat
4.MapReduce
1. InputFormat
(1)默认得式TextInputFormat kv,key是偏移量,v是一行内容
(2)处理小文件CombineTextInputFormat 把多个文件合并到一起统一切片
2.Mapper
setup():处理初始化
mapper():用户得业务逻辑
clearup():关闭资源
3.Shuffle
一、首先分区:默认分区HashPartitioner,默认按照key得hash值 % numreducetask个数
二、排序:1)部分排序,每个输出得文件内部有序,
2)全排序:一个reduce,对所有数据大排序
3)二次排序:自定义排序范畴,实现一个writableComparable接口,重写compareTo方法
4.combiner
前提:不影响最终得业务逻辑(求和可以,平均值不行)
提前预聚合,是在map端完成的,解决数据倾斜得方法
5.reducer
用户得业务逻辑
setup():初始化
reduce:用户逻辑
clearup():关闭资源
6.outputFormat
默认是textoutputFormat
- 首先,有一个待处理的文本
- 客户端:Job任务提交submit前,获取待处理数据的信息,然后submit()提交之后,根据参数配置,形成一个任务分配的规划。
- 客户端提交之后,会准备split,xml(job运行的一些参数)和jar提交给yarn
- yarn会开启Mrappmaster:整个任务运行的老大,读取客户端的信息,最主要的就是读取split切片信息来计算出MapTask的数量( 在这之前都是job的提交流程,还没有进入到map方法)
- Mrappmaster开启对应的 MapTask,启动之后开始工作,首先读取待处理文件,使用InputFormat(使用默认的TextInputFormat),这里面有两个方法,RecorderReader(按行进行读取)和isSplitable是否切割,k是偏移量,v是一行内容。(read读取阶段)
- 读取完之后,返回给Mapper(用户自定义的逻辑运算,按照业务需求)(map阶段)
- Mapper处理之后,输出到环形缓冲区(相当于内存)一般是索引(元数据),另一半是数据。环形缓冲区默认是100m,当到达80%之后反向溢写,指的是新开一个线程把在环形缓冲区的数据溢写到磁盘上,因为还没有达到100%,所以另一个线程继续把从Mapper来的数据写到内存中。
- 从Mapper到环形缓冲区的数据,首先就把数据标记了分区信息,在溢写的时候,对分区内部的数据进行排序(使用快排),什么时候开始排序呢?是在缓冲区数据达到80%进行溢写的时候进行排序,对索引(元数据)进行排序。(在环形缓冲区的分区排序都属于collect阶段)
- 到达80%的时候,就会将环形缓冲区的数据溢写到磁盘上,有多个溢写文件,此时的数据是分区且区内有序的。(溢写阶段)
- 然后进行merge归并排序将文件合并为一个大文件,保证每一个分区内是有序的,分区整体之间没有序,因为将来要发送到不同的reducetask上,归并之后的文件永久存在磁盘上(merge阶段)
- Combiner是在reduce之前可以进行预聚合的,优化的手段,但不是所有场景都适合
- yarn的MrappMater会观察到,所有的MapTask任务完成后,启动相应数量的ReduceTask
- reduceTask主动从多个MapTask对应的分区拉取数据(copy阶段)
- 然后,将从不同MapTask拉取过来的数据,进行一个全局归并排序(为什么进行排序呢,因为进入到reduce方法里的是相同key的内容)(sort阶段)
- reducer一次读取一组,相同的key进入到reduce方法
- reduce处理完之后,往出写。由核心组件OutPutFormat中默认的TextOutputFormat的RecoderWriter方法往出写,形成了对应的文件。(reduce阶段)
MapTask工作机制
- 一共分成五个阶段read、map、collect、溢写、merge
MapTask源码解析
- 首先进入到context.write方法
- 进入到collect收集器,收集器里有个参数partitioner,有个方法getpartition(),因此首先进行分区
- 然后再进入到collect环形缓冲区,注意一下keystart和valstart支持序列化
- 写出一条即一行内容,然后又回到map方法
- 到最后一行内容之后,进入到collect,结束之后
- 不进入到map方法,而是cleanup方法,跳出来,走到close()
- 进入到close()之后,走到collector.flush()刷写,进入到flush之后,走到sortandSpill,进入,走到sort方法,有快排的方法,然后按照分区开始溢写
- 然后走到mergeParts进行归并,遍历所有的溢写文件,进行merge排序,归并之后,产生file.out.index文件
- 然后,collector.close()收集器结束
ReduceTask工作阶段
- 一共分成三个阶段copy、sort、reduce
ReduceTask源码
- if(isMapOrReduce())进入
- 首先初始化
Shuffer机制
在map和reduce端都有,在Map方法之后,Reduce之前的数据处理流程
,混洗过程
- 最先进入到getPartition方法,标记数据的分区
- 标记完分区后,进入到环形缓冲区,缓冲区的大小是100m,左侧索引,右侧数据,当缓冲区的数据达到80%时候,进行反向溢写,即新开一个线程将数据从缓冲区存入到磁盘中,原来的线程继续将数据存到环形缓冲区
- 在溢写之前,对分区内数据进行排序,排序方式是快排,对key的索引排序,按照字典顺序排序
- 排序之后,第一次溢写,溢写会产生两个文件,spill.index和spill.out,combiner是可选的流程,在溢写前
- 然后将每个分区内的文件进行归并排序,然后还可以进行combiner,combiner之后,还可以进行压缩(压缩之后传输的效率高)
- 最后,所有的内容写到磁盘上
- map之后,reduce将对应分区的数据拉取,首先拉取到内存中,内存不够则溢写到磁盘上,然后进行归并排序
- 按照相同的key分组,相同key的数据进入到reduce方法中
分区
- 需求:要求将统计结果按照条件输出到不同文件中
- 默认分区partition:哈希分区,原理是根据key的hashcode对ReduceTask个数取模得到的,因此用户没法控制哪个key存储到哪个分区
- 用户可以自定义partitioner,首先自定义类继承partitioner,重写getPartition()方法,然后在Job驱动中,设置自定义Partition(job.setPartitionerClass(CustomPartitioner.class));自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的ReduceTask(job.setNumReduceTasks(5))
- 分区总结
(1)如果ReduceTask的个数大于getPartition的结果数,则会产生几个空的输出文件
(2)如果ReduceTask的个数小于getPartition的结果数,则会报错
(3)如果ReduceTask的个数等于1,则不管MapTask输出几个分区文件,最终结果都会交给一个ReduceTask,最终只会产生一个文件
(4)分区号必须从0开始,逐一累加
排序
- 在Map阶段,进行了两次排序,分别是快速排序和归并排序,一次是溢写到磁盘之前,对缓冲区中的数据进行一次快速排序,另一次是当所有数据处理之后,对磁盘上的所有溢写文件进行归并排序,两者都是在分区内排序,都是对key的索引进行排序。最终磁盘上存储的是,每个MapTask有一个区内排序的文件,每个MapTask一个文件
- 在Reduce阶段,进行了一次归并排序,首先是拉取每个MapTask中的相应分区的文件,进行一次归并排序
- map和reduce过程均会对数据按照key进行排序,是默认行为,必须排序
- 如果要进行自定义排序怎么办呢
案例:对手机号的流量进行排序,如果将bean对象做为key传输,必须支持排序,因此需要实现WritableComparable接口(集成了Writable和Compatable接口),重写里面的CompareTo方法(序列化的时候是实现的Writable接口)
combiner组件
5 Yarn
5.1Yarn的工作机制
两个角色:job 和 ResourceManger
- 在命令行上执行wc.jar ,main()方法里面job.waitForCompletion(),创建一个YarnRunner,在本地模式得时候是LocalRunner
- YarnRunner向集群申请一个Application——运行一个应用
- ResourceManager(集群得老大)让YarnRunner把运行得job资源和application_id放在指定的集群路径上
hdfs://…/.staging以及任务的application_id
- job将job.split、job.xml、wc.jar(是在job.submit()生成的) 提交到集群给的资源路径里面
形成hdfs://…/.staging/application_id路径
- 资源提交完毕后,向resourcemanager申请运行mrAppMaster
- 在ResourceManager内部,会产生一个任务Task,同时,其他客户端也会产生任务,所以,ResourceManager内部有多个任务,将其放在一个任务队列
- 空闲的NodeManager会把在ResourceManager队列里的任务领取走
- 创建容器 ,任何任务的执行都在容器中,每个容器中有cpu,ram。启动一个mrAPPmaster进程
- mrAPPmaster 去集群资源的路径上读取Job.split,读取切片信息,然后向集群申请运行对应的MapTask容器,如果是两个split,开启两个maptask,开启两个容器(可能在一个节点上,也可能在两个)
- 空闲的nodemanager领取任务,创建容器
- MRAppmaster向两个nodemanager上发送启动脚本,运行Maptask任务,开启两个yarnchild,开始运行
- MapTask运行结束之后,把数据按照分区存储在磁盘上,计算结束之后,MRAPPmaster知道任务执行完了
- Mrappmaster再次向ResourceManager申请两个2个容器用来运行ReducerTask程序,因此ResourceManager中的任务队列中又有了两个任务task
- 空闲的NodeManager领取到任务后,开启容器,运行reducetask程序,开启yarnchild,开始运行任务
- reducetask执行完之后,整个程序运行完了,mrAppMater向ResourceManager注销自己,释放资源
5.2的调度器
- FIFP/容量/公平
- apache默认调度器 容量;CDH默认调度器 公平
- 公平 /容量默认一个default队列,满足不了需求,需要创建多个队列
- 多个调度器的命名 :中小企 hive spark flink mr; 大企业:业务模块 登录/注册/购物车/营销
- 好处 :解耦 降低风险 11.11 6.18降级使用
- 每个调度器的特点
1.相同点:支持多队列,可以借调资源,支持多用户
2.不同点:容量:优先满足先进来的任务执行;公平:进入到队列里面的任务公平享有队列资源(在一定时间内) - 生产环境下: 中小企业:对并发度不高,容量 ;重大企业:对并发度要求高,选择公平。
5.3开发需要重点掌握
- 队列运行原理
- yarn命令:查看日志,容器
- 核心参数配置
- 配置容量调度器和公平调度器
- tool接口使用

















 2269
2269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









