






准备数据
数据读入
训练集测试集生成
将输入特征和标签配对
#从sklearn包datasets读入数据集
from sklearn.datasets import datasets
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
#分训练集和测试集
x_train = x_data[:-30]#由开头到倒数第30个
y_train = y_data[:-30]
x_test = x_data[-30:]#由倒数第30个到最后
x_test = y_data[-30:]
#使用from_tensor_slices把训练集的输入特征和标签配对打包
train_db = tf.data.Datasets.from_tensor_slices((x_train,y_train)).batch(32)
test_db = tf.data.Datasets.from_tensor_slices((x_test,y_test)).batch(32)
有4列,即4个特征
每32组为一个batch喂入神经网络中
搭建网络
定义神经网络中所有可训练的参数
w1 = tf.Variable(tf.random.truncated_normal([4,3],stddev=0.1,seed=1))#输入特征是4个,只用了一层神经网络,输出节点是三分类,所以是3,是4行3列的张量
b1 = tf.Variable(tf.random.truncated_normal([3],stddev=0.1,seed))#b1要与w1中第二个维度的数字一致
参数优化
嵌套循环迭代,with结构求得损失函数loss对每个可训练参数的偏导数,更新参数,显示当前的loss函数
for epoch in range(epoch):#对整个数据集进行循环
for step,(x_train,y_train) in enumerate(train_db):#针对batch循环
with tf.GradientTape() as tape:
#计算前向传播过程y和总损失函数loss
grades = tape.gradient(loss,[w1,b1])#损失函数loss分别对参数w1和b1计算偏导数
w1.assign_sub(lr*grades[0])#更新参数w1和b1
b1.assign_sub(lr*grades[1])
print("Epoch{},loss{}".format(epoch,loss_all/4))
#打印出这一轮epoch后的损失函数值,训练集有120组数据,batch是32个,每个step只能喂入32组数据,需要batch级别循环4次,求得每次step迭代的平均loss
#在每次epoch循环后显示当前模型的效果,即识别准确率,在epoch循环中,嵌套了一个batch级别的循环
for x_test,y_test in test_db:
y = tf.matmul(x_train,w) + b #y为预测的结果,前向传播
y = tf.nn.softmax(y) #使其符合概率分布
pred = tf.argmax(y,axis = 1)# 返回y中最大值的索引,即预测的分类
pred = tf.cast(pred,dtype = y_test.dtype)#调整数据类型与标签一致
correct = tf.cast(tf.equal(pred,y_test),dtype=tf.int32)
correct = tf.reduce_sum(correct)#如果预测值和标签相等,correct自加一,将每个batch的correct数加起来
total_correct += int(correct)#将所有batch中的correct数加起来
total_number += x_test.shape[0]
acc = total_correct/total_number
print("test_acc:",acc)
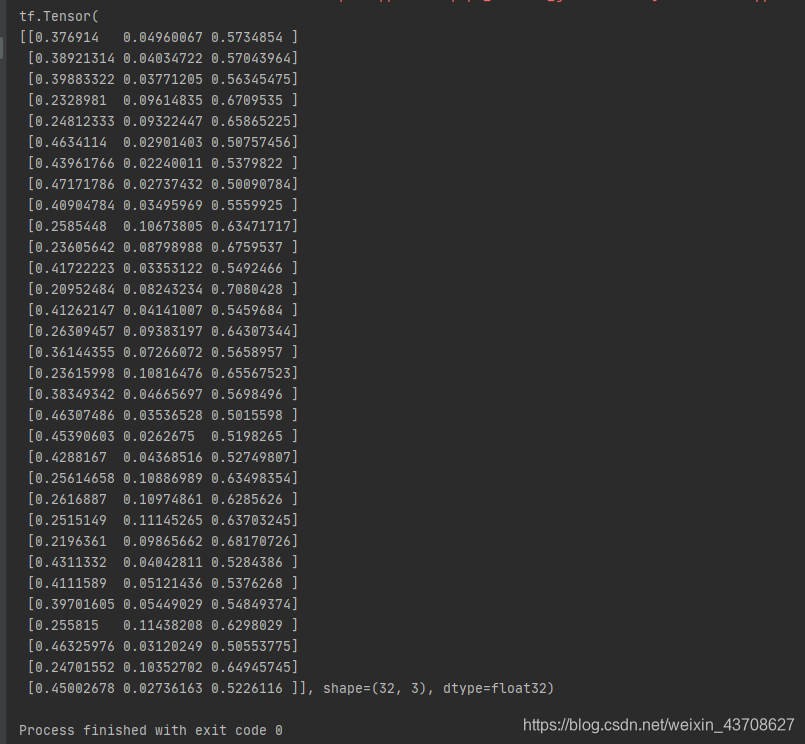
输出y值如下:

















 2426
2426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









