






 本文介绍如何用Pandas快速查询cc列特定值,包含字符串的操作,挑选数据类型,查看值分布与缺失率,以及内存优化技巧。涵盖了向量化操作和数据透视表的实战应用。
本文介绍如何用Pandas快速查询cc列特定值,包含字符串的操作,挑选数据类型,查看值分布与缺失率,以及内存优化技巧。涵盖了向量化操作和数据透视表的实战应用。
查询cc列取值为xx的记录
df[df["cc"] == xx]
df.query("cc = xx")
查询cc列取值包含xx字符串的记录
df[df[cc].str.contains(xx)]
挑选某些数据类型的列的记录
df.dtypes.value_counts()
df.select_dtypes(include = ['float64','int64'])
查看值分布
df[xx].value_counts()
缺失率
df["cc"].isna().mean()
#同理非空率
df["cc"].notna().mean()
def missing_cal(df):
"""
df :dataframe
return:每个变量的缺失率
"""
missing_series = df.isnull().sum()/df.shape[0]
missing_df = pd.DataFrame(missing_series).reset_index()
missing_df = missing_df.rename(columns={'index':'col',
0:'missing_pct'})
missing_df = missing_df.sort_values('missing_pct',ascending=False).reset_index(drop=True)
return missing_df
内存修剪
def reduce_mem_usage(df):
starttime = time.time()
numerics = ["int16", "int32", "int64", "float16", "float32", "float64"]
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if pd.isnull(c_min) or pd.isnull(c_max):
continue
if str(col_type)[:3] == "int":
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
print("-- Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction),time spend:{:2.2f} min".format(end_mem,
100*(start_mem-end_mem)/start_mem,
(time.time()-starttime)/60))
return df
#################################
>>> ii16 = np.iinfo(np.int16)
>>> ii16.min
-32768
>>> ii16.max
32767
>>> ii32 = np.iinfo(np.int32)
>>> ii32.min
-2147483648
>>> ii32.max
2147483647
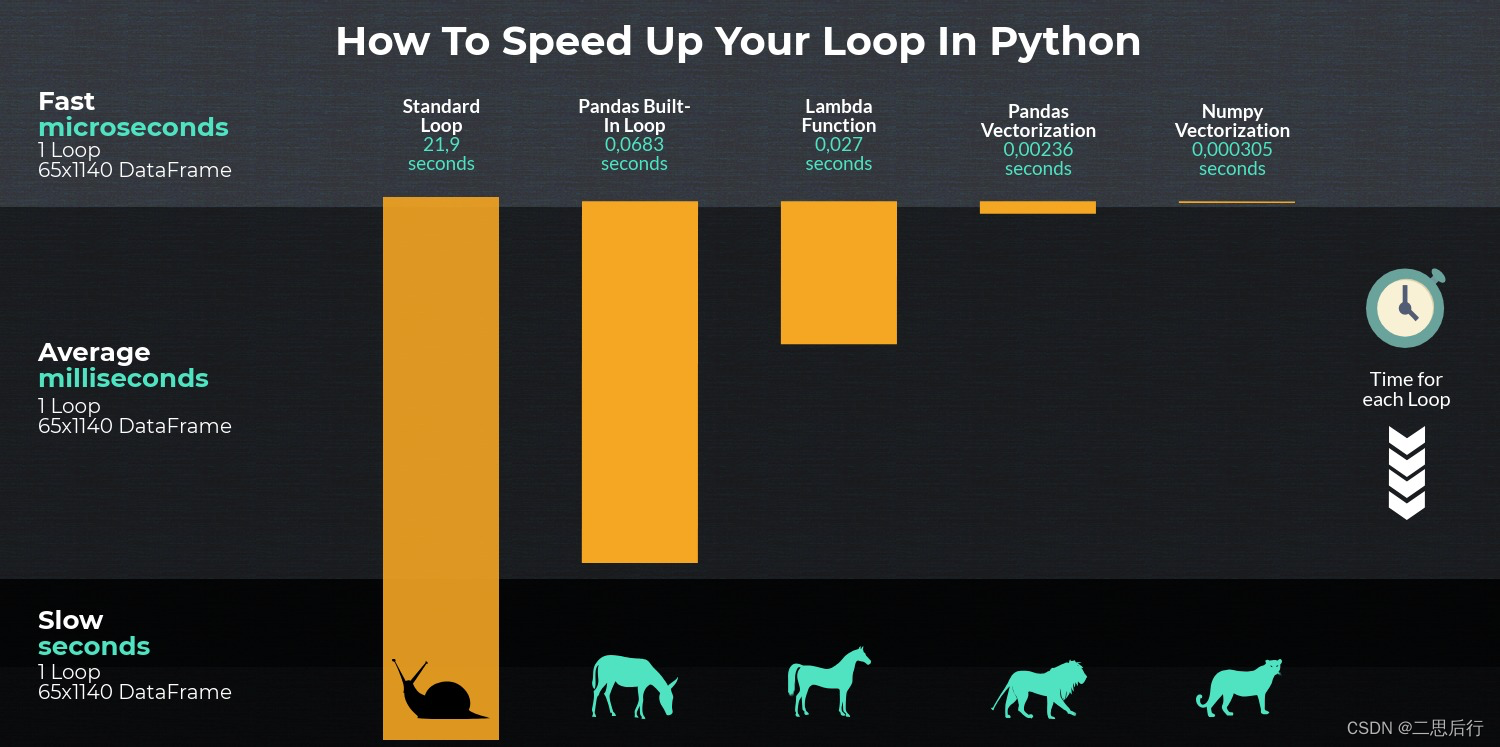
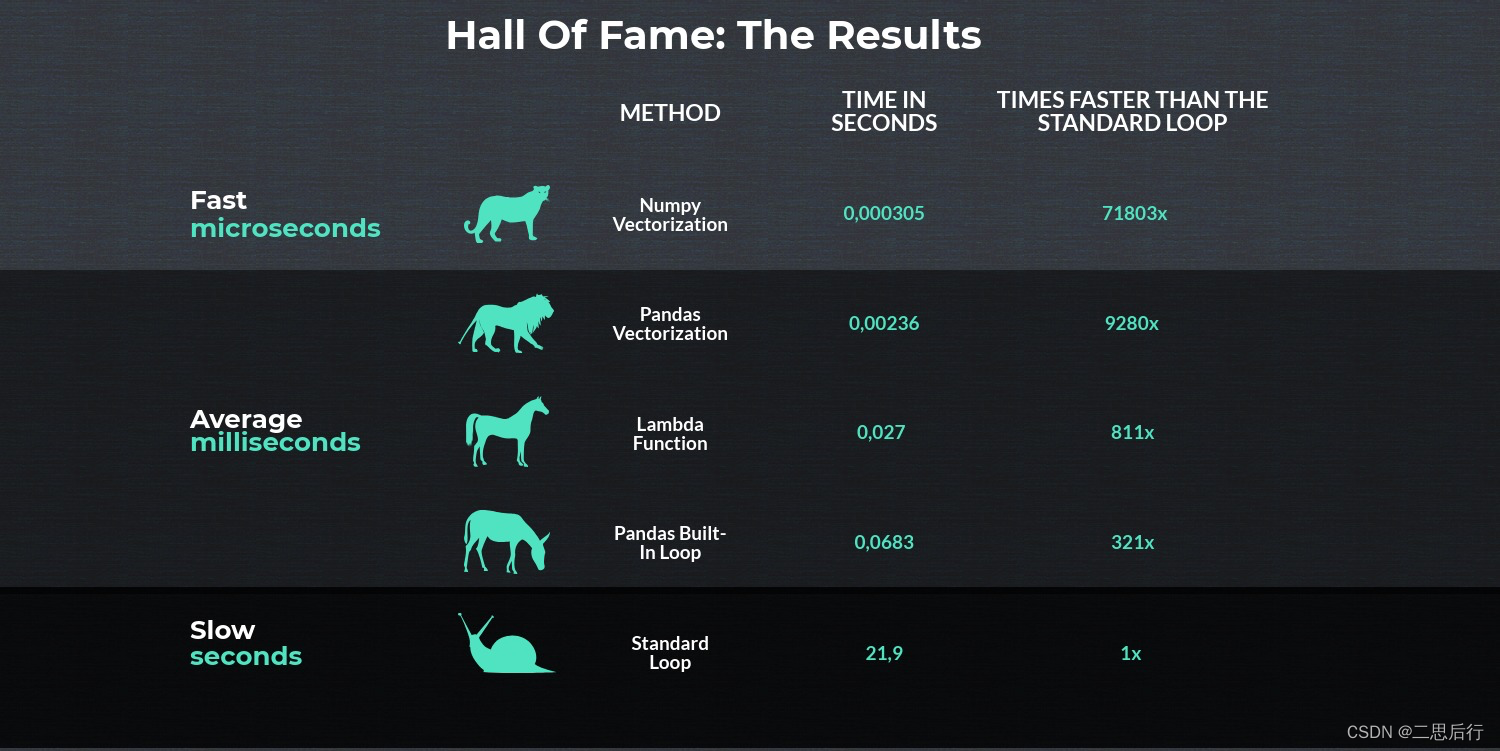
尽量使用向量化
如果确定需要使用循环,则应始终选择apply方法。
否则,矢量化始终是可取的,因为它要快得多。
numpy 矢量化就是df.values()之间进行计算
透视表
df = pd.DataFrame({'姓名':['张 三','李 四','王 五'],
'所在地':['北京-东城区','上海-黄浦区','广州-白云区']})
df
df.姓名.str.split(' ', expand=True)
Out[8]:
0 1
0 张 三
1 李 四
2 王 五


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











