







spark简单案例
开启本地模式
[dragon@master 桌面]$ spark-shell --master local[2]【并行度我给了2个】
[dragon@master 桌面]$ jps
2925 SparkSubmit
3007 Jps
//查看/home/dragon/目录下student文件的行数
scala> val lines =sc.textFile("file:///home/dragon/student")
lines: org.apache.spark.rdd.RDD[String] = file:///home/dragon/student MapPartitionsRDD[3] at textFile at <console>:24
scala> lines.count
res1: Long = 14
scala> lines.first
res3: String = 1,bai,nan
开启集群的独立模式再测试
[dragon@master 桌面]$ start-master.sh
[dragon@master 桌面]$ start-slaves.sh
[dragon@master 桌面]$ spark-shell --master spark://master:7077
[dragon@master 桌面]$ jps
3843 Jps
3685 Master
3772 SparkSubmit
scala> val lines =sc.textFile("file:///home/dragon/student")
lines: org.apache.spark.rdd.RDD[String] = file:///home/dragon/student MapPartitionsRDD[1] at textFile at <console>:24
scala> lines.count
报错(文件找不异常): java.io.FileNotFoundException: File file:/home/dragon/student does not exist
当在本地模式时,lines.count 命令直接在master节点上去找student文件,
而此时为独立集群模式,所以lines.count会去worker节点找该文件,worker节点(计算节点)为从节点salve01、slave02、slave03
解办法就是将master节点上的文件拷贝到worker节点上
[dragon@master ~]$ scp student dragon@slave01:/home/dragon/
[dragon@master ~]$ scp student dragon@slave02:/home/dragon/
[dragon@master ~]$ scp student dragon@slave03:/home/dragon/
scala> lines.count
res1: Long = 14
一般情况下我们不使用file:// 应该为:sc.testFile("/student"),默认是加载 hdfs里的路径
所以应该开启Hadoop集群 start-dfs.sh 将该文件上传到 Hadoop 集群上
开启Hadoop集群后来查看一下 每个节点的守护进程,发新每个worker节点 都会自动开启CoarseGrainedExecutorBackend (worker的执行器)
例如:
2673 Worker
2739 CoarseGrainedExecutorBackend
3450 DataNode
3037 QuorumPeerMain
3630 Jps
3550 JournalNode
//上传到 hdfs后,再进行测试
scala> val line1=sc.textFile("/student.txt")
line1: org.apache.spark.rdd.RDD[String] = /student.txt MapPartitionsRDD[3] at textFile at <console>:24
scala> line1.count
res3: Long = 14
// glom是根据你并行度进行分区,再独立集群模式下,并行度的值取决于你的核心数,可以在8080上查看核心数cores
scala> line1.glom.collect
res4: Array[Array[String]] = Array(Array(1,bai,nan, 2,long,nv, 3,xian, 4.sheng, 5,wang, 5,xian, 6,sheng), Array(1,dou, 3,shi, 5,xian, 9,sheng,bai, 10,long, xian, sheng))
//过滤包含字符串“xian”的行
scala> val line1_xian =line1.filter(x=>x.contains("xian"))
line1_xian: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[5] at filter at <console>:26
scala> line1_xian.count
res5: Long = 4
scala> line1_xian.collect
res6: Array[String] = Array(3,xian, 5,xian, 5,xian, xian)
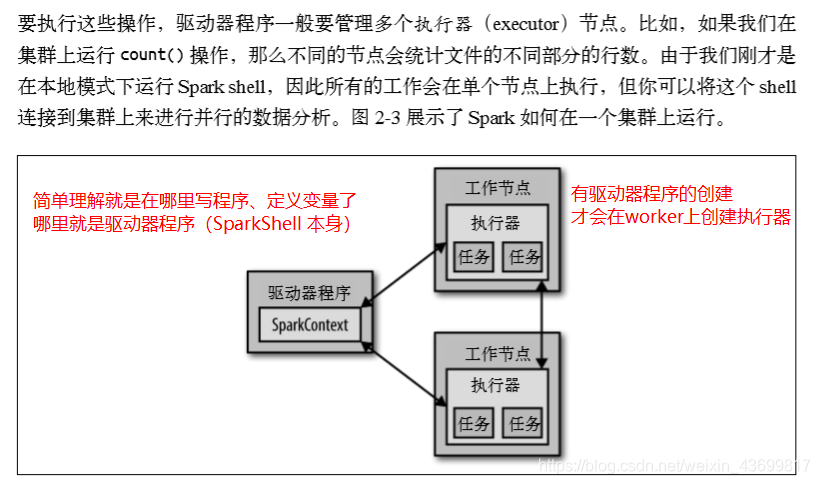
每个 Spark 应用都由一个驱动器程序(driver program)来发起集群上的各种 并行操作。
驱动器程序包含应用的 main 函数,并且定义了集群上的分布式数据集,还对这 些分布式数据集应用了相关操作。
驱动器程序通过一个 SparkContext 对象来访问 Spark。
这个对象代表对计算集群的一个连 接。shell 启动时已经自动创建了一个 SparkContext 对象,是一个叫作 sc 的变量。
独立应用搭建–基于Maven构建Spark应用程序
Spark 也可以在 Java、Scala 或 Python 的独立程序中被连接使用。这与在 shell 中使用 的主要区别在于你需要自行初始化 SparkContext
连接 Spark 的过程在各语言中并不一样。在 Java 和 Scala 中,只需要给你的应用添加一 个对于 spark-core 工件的 Maven 依赖
1.创建Maveng工程
可参考我之前的文章:https://blog.youkuaiyun.com/weixin_43699817/article/details/100552077
2.配置pom文件,选择你需要的版本,添加 spark-core 工作组件的 maven 依赖
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.2</version>
</dependency>
3.一旦完成了应用与 Spark 的连接,接下来就需要在你的程序中导入 Spark 包并且创建 SparkContext。
可以通过先创建一个 SparkConf 对象来配置你的应用,然后基于这个 SparkConf 创建一个 SparkContext 对象
1)在scala中初始化Spark:
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
val conf = new SparkConf().setMaster("local").setAppName("My App") //
val sc = new SparkContext(conf)
2)在java中初始化Spark:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
SparkConf conf = new SparkConf().setMaster("local").setAppName("My App");
JavaSparkContext sc = new JavaSparkContext(conf);
3)在python中初始化Spark
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
传递的两个参数 setMaster 和 setAppName
- 集群 URL:告诉 Spark 如何连接到集群上。在这几个例子中我们使用的是 local,这个特殊值可以让 Spark 运行在单机单线程上而无需连接到集群。
- 应用名:在例子中我们使用的是 My App。当连接到一个集群时,这个值可以帮助你在 集群管理器的用户界面中找到你的应用。
4.编写WC程序
// 创建一个Scala版本的Spark Context
val conf = new SparkConf().setAppName("wordCount")
val sc = new SparkContext(conf)
// 读取我们的输入数据
val input = sc.textFile(inputFile)
// 把它切分成一个个单词
val words = input.flatMap(line => line.split(" "))
// 转换为键值对并计数
val counts = words.map(word => (word, 1)).reduceByKey{case (x, y) => x + y}
// 将统计出来的单词总数存入一个文本文件,引发求值
counts.saveAsTextFile(outputFile)
1)编写WC程序,在本地测试
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("WC").setMaster("local")
val sc = new SparkContext(conf)
val testfile = sc.textFile("hdfs://master:9000/student");
println(testfile.count())
val wc = testfile.flatMap(x=>x.split(" "))
.map(x=>(x,1))
.reduceByKey(_+_)
println(wc.collect().toList)
}
2)编写 WC程序,在 Standalone 模式调试步骤:
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("WC").setMaster("spark://master:7077")
.setJars(List("D:\IDEA2019.1\Projects\sparkdemo\out\artifacts\sparkdemo_jar\sparkdemo.jar"))
val sc = new SparkContext(conf)
val testfile = sc.textFile("hdfs://master:9000/studentdemo");
println(testfile.count())
val wc = testfile.flatMap(x=>x.split(" "))
.map(x=>(x,1))
.reduceByKey(_+_)
println(wc.collect().toList)
}
打jar包。
【File】–>【Project structure】–>【Artifacts】–>【+】–>【add–Jar–from modules】
编译生成Jar包
【Build】–>【Build Artifacts】–选择生成的Jar文件,进行编译
在代码中,添加 setjar()
conf.setJars(List(“D:\IDEA2019.1\Projects\sparkdemo\out\artifacts\sparkdemo_jar\sparkdemo.jar”))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









