







-
partition:用来指定map输出的key交给哪个reuducer处理
默认是通过对map输出的key取hashcode对指定的reduce个数取余
partition数决定reduce数,业务又决定reduce数 -
默认情况下,作业的ReduceNum=1,每一个Reduce对应生成一个结果文件。如果ReduceNum=0,则没有reduce阶段。
-
partition如何分区:
默认情况下,分区器采用:【org.apache.hadoop.mapreduce.Partitioner】抽象类
类说明:分区器按key(k2中间值)进行分区,它提供了getPartition()方法用于获取当前key值对应的分区号(partition number)
通常情况下,采用hash函数。分区总数与Job的reduce数量相同。public class HashPartitioner<K, V> extends Partitioner<K, V> { /** Use {@link Object#hashCode()} to partition. */ public int getPartition(K key, V value,int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } } -
建议:分区数等于reduce数
如果分区数小于reduce数,则浪费资源
如果分区数大于reduce数,则抛异常,如下:(此时我的partition数为3,NumReduceTasks数为2)
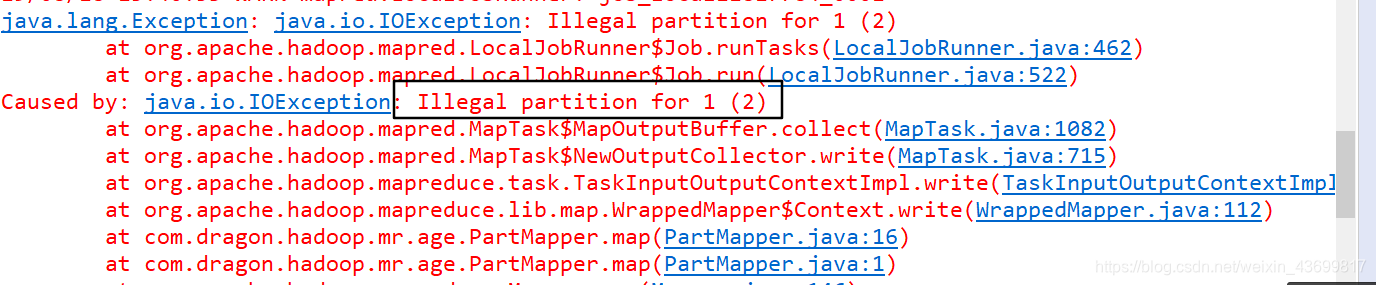
-
自定义分区:继承Partitioner抽象类,重写getPartition()方法
例如:将一个年龄文件分三个阶段:
1)构建自定义的Partition类public class MyPartitioner extends Partitioner<IntWritable , IntWritable>{ //继承Partitioner抽象类 @Override public int getPartition(IntWritable key, IntWritable value, int numPartitions) { if(key.get()>=50){ return 0;//指定结果到第0个分区,part-r-00000 }else if(key.get()>10 && key.get()<50){ return 1;//part-r-00001 }else{ return 2;//part-r-00002 } } }2)在job文件中设置分区类和reduce数
job.setPartitionerClass(MyPartitioner.Class);//设置自定义的分区类 job.setNumReduceTasks(3);//与分区数保持一致

















05-13
 2728
2728
2728
08-14
1636
1636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









