







 本文深入探讨Hive SQL的高级特性,包括groupby分组、distributeby数据分布、orderby与sortby排序、clusterby组合排序及不同存储格式如Parquet、RCFile、ORCFile、Avro和SequenceFile的性能对比,为大数据处理提供优化方案。
本文深入探讨Hive SQL的高级特性,包括groupby分组、distributeby数据分布、orderby与sortby排序、clusterby组合排序及不同存储格式如Parquet、RCFile、ORCFile、Avro和SequenceFile的性能对比,为大数据处理提供优化方案。
group by分组
-
group by 按照某些字段的值进行分组,有相同值放到一起
一般总爱和聚合函数AVG(),COUNT(),max(),main()等一块用例子:通过year来分组
hive> select year(ymd),avg(price_close) from stocks where exchange1 = 'NASDAQ' and symbol = 'AAPL' group by year(ymd); -
group by 和 distribute by的区别
都是按key值划分数据,都使用reduce操作
1)distribute by只是单纯的分散数据,distribute by col 按照col列把数据分散到不同的reduce。
2)而group by把相同key的数据聚集到一起,后续必须是聚合操作
排序
-
创建测试数据
【创建一张表】
hive>create table hive2.me(id int,name string) row format delimited fields terminated by ',';
【向表中加载数据】
hive>load data loca inpath '/home/dragon/test1' into table hive2.me;
【查看表中数据】
hive>select * from hive2.me;
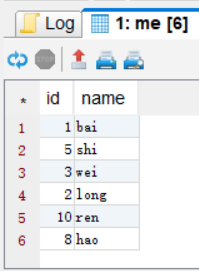
-
order by 全局排序(默认升序asc,降序为desc)
order by 对查询结果执行全局的排序,所有的数据都通过一个reduce处理,只能由一个partition
hive>select * from hive.test order by id asc ;【通过id来全局升序排序】
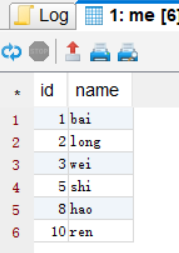
-
sort by 局部排序
sort by 会在每一个reduce中对数据进行排序,执行一个局部排序的过程
在排序之前要先设置reduce的数量,自定义,默认为1个
hive>set mapreduce.job.reduces=3;【默认为1个】
hive>select * from hive.test sort by id;
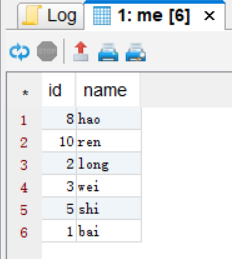
注意:如果mapreduce.job.reduces为1,那么order by和sort by等同!!! -
distribute by:按照指定的字段或表达式对数据进行划分,输出到对应的Reduce或者文件中
控制map结果的分发,它会将具有相同字段的map输出分发到一个reduce节点上做处理
例:
hive>set mapred.reduce.tasks=2;【设置redcuce任务数目,划分结果输出到2个文件】
hive>insert overwrite local directory '/home/hadoop/test/' SELECT id from hive2.me distribute by id;
【输出文件中的结果没有顺序,加 sort by 对结果排序,要在distribute by 后面加】 -
cluster by 是 (distribute by+sort by 一起的简写方式)只能降序排列
例:
hive> set mapred.reduce.tasks=2;
hive>insert overwrite LOCAL directory ‘/home/hadoop/test/’ SELECT id FROM hive.testcluster BY id;
等同于
hive>insert overwrite LOCAL directory ‘/home/hadoop/test/’ SELECT id FROM hive.testdistribute BY id sort by id;
存储格式
【hadoop权威指南494页】
- 默认存储格式为:纯文本
stored as textfile; - 二进制存储的格式
顺序文件、avro文件、parquet文件、rcfile文件、orcfile文件 - 转存parquet格式
hive> create table hive2.stocks_parquetstored as parquet asselect * from hive2.stocks
说明:原始数据大小为stocks表[200万条],111M,转存parquet格式后,hdfs上数据文件大小为26M,压缩比在4倍左右; - 转存rcfile格式
hive> create table hive2.stocks_rcfilestored as rcfile asselect * from hive2.stocks ;
说明:原始数据大小为stocks表[200万条],111M,转存rcfile格式后,hdfs上数据文件大小为84M,压缩比在0.8倍左右; - 转存orcfile格式【压缩后最小】
hive> create table hive2.stocks_orcfilestored as orcfile asselect * from hive2.stocks ;
说明:原始数据大小为stocks表[200万条],111M,转存orcfile格式后,hdfs上数据文件大小为22M,压缩比在5倍左右; - 转存avro格式
hive> create table hive2.stocks_avrostored as avro asselect * from hive2.stocks ;
说明:原始数据大小为stocks表[200万条],111M,转存avro格式后,hdfs上数据文件大小为106M,压缩比在0.9倍左右; - 转存sequencefile格式
hive> create table hive2.stocks_sequencestored as sequencefile asselect * from hive2.stocks ;
说明:原始数据大小为stocks表[200万条],111M,转存sequencefile格式后,hdfs上数据文件大小为134M,压缩比在-1.1倍左右;
测试对比各文件的执行时间:
1)text 执行时间:(111m,M:7.15s,R:2.75s)
检索语句:select symbol,avg(price_close) from hive2.stocks group by symbol;
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-08-31 13:03:26,421 Stage-1 map = 0%, reduce = 0%
2019-08-31 13:03:49,367 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 7.15 sec
2019-08-31 13:04:04,019 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 9.8 sec
MapReduce Total cumulative CPU time: 9 seconds 800 msec
2)parquet 执行时间:(26m,M:6.7s,R:3s)
hive> select symbol,avg(price_close) from hive2.stocks_parquet group by symbol;
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-08-31 13:20:23,534 Stage-1 map = 0%, reduce = 0%
2019-08-31 13:20:57,709 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 6.69 sec
2019-08-31 13:21:21,019 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 8.68 sec
2019-08-31 13:21:28,414 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 9.73 sec
MapReduce Total cumulative CPU time: 9 seconds 730 msec
3)rcfile 执行时间:(84m,M:6.9s,R:2.32s)
hive> select symbol,avg(price_close) from hive2.stocks_rcfile group by symbol;
doop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-08-31 13:23:57,286 Stage-1 map = 0%, reduce = 0%
2019-08-31 13:24:24,720 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 6.9 sec
2019-08-31 13:24:39,198 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 9.22 sec
MapReduce Total cumulative CPU time: 9 seconds 220 msec
4)orcfile 执行时间:(22m,M:4.9s,R:2.2s)
hive> select symbol,avg(price_close) from hive2.stocks_orcfile group by symbol;
Kill Command = /home/dragon/soft/hadoop/bin/hadoop job -kill job_1567275973105_0011
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-08-31 13:26:13,031 Stage-1 map = 0%, reduce = 0%
2019-08-31 13:26:32,922 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.87 sec
2019-08-31 13:26:48,392 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.1 sec
MapReduce Total cumulative CPU time: 7 seconds 100 msec
5) avro 执行时间:(106m,M:17.34s,R:2.86s)
hive> select symbol,avg(price_close) from hive2.stocks_avro group by symbol;
Kill Command = /home/dragon/soft/hadoop/bin/hadoop job -kill job_1567275973105_0013
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-08-31 13:30:16,406 Stage-1 map = 0%, reduce = 0%
2019-08-31 13:30:40,585 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 17.34 sec
2019-08-31 13:30:51,977 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 20.2 sec
MapReduce Total cumulative CPU time: 20 seconds 200 msec
6)sequencefile 执行时间:(134m,M:12s,R:3.2s)
hive> select symbol,avg(price_close) from hive2.stocks_sequence group by symbol;
2019-08-31 13:35:30,740 Stage-1 map = 0%, reduce = 0%
2019-08-31 13:35:53,101 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 12.09 sec
2019-08-31 13:36:07,101 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 15.2 sec
MapReduce Total cumulative CPU time: 15 seconds 200 msec
UDF自定义函数
自定义函数类型:
- UDF:单行进–>单行出
- UDAF:多行进–>单行出
- UDTF:单行进–>多行出
-
首先创建JAVA类,继承UDF.class
-
重写evaluate(…)方法;
package com.dragon.hive.udf; import org.apache.hadoop.hive.ql.exec.UDF; //举例:简单的两整数相加求和 public class Sum_udf extends UDF{ public int evaluate(int a,int b){ return a+b; } } -
打jar包;
[File]->[Export]->[JAR file]->选择要打的jar包->[next]->[finish] -
加载自定义函数的jar包;
hive>add jar /home/dragon/XXX.jar ;
hive>create temporary function {function_name} as 'com.dragon.hive.udf.类名' -
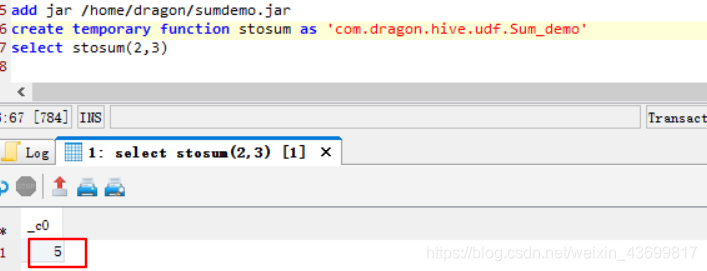
测试:
hive> add jar /home/dragon/mnt/hgfs/share/sumdemo.jar【添加jar包】
hive> create temporary function stosum as ‘com.dragon.hive.udf.Sum_demo’ 【创建临时函数stosum】
hive> select stosum(cast(floor(price_open) as int),cast(floor(price_close) as int)) from hive2.stocks_parquet limit 5;
【案例属性值为浮点型,先向下转型,再强制转换为int】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









