







名词解析:
broker: 一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
topic: 主题 ,代表一类消息
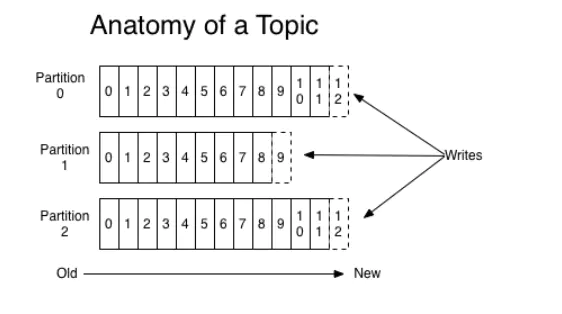
partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。每个partition都对应唯一的消费者!!!
offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息.同一个partition的offset是被顺序消费的
topic和partition以及offset关系如图所示
生产消息
import json
from kafka import KafkaProducer
kafka_data = [{'tracking_number':'WSHBR1210728857YQ' ,'write_date':'2020-05-27'} ]
servers = ['127.0.0.1:9092']
topic_name = 'return_picking_out_test'
def kafka_product(servers, topic_name, msg):
# 将数据放入kafka生产者中
producer = KafkaProducer(bootstrap_servers=servers)
message = json.dumps(msg).encode()
producer.send(topic, message)
producer.close()
kafka_product(servers=servers, topic_name=topic_name, msg=kafka_data)消费消息
此栗子为正常消费不会重复消费:
import json
from pykafka import KafkaClient
servers = ['127.0.0.1:9092']
topic_name = 'return_picking_out_test'
def kafka_customer_handle(servers,topic_name):
# kafka消费数据
servers = ','.join(servers) # '127.0.0.1:9092,127.0.0.2:9092,127.0.0.3:9092'
client = KafkaClient(hosts=servers)
topic = client.topics[topic_name]
consumer = topic.get_simple_consumer(consumer_group=topic_name, auto_commit_interval_ms=1, auto_commit_enable=True,consumer_id=b'rpo')
for message in consumer:
value = json.loads(message.value.decode(encoding='utf-8'))
print(value)
kafka_customer_handle(servers,topic_name)
你说要再消费两一两条数据?
好嘞,给你展示上
import json
from kafka import KafkaProducer
from pykafka import KafkaClient
servers = ['127.0.0.1:9092']
topic_name = 'return_picking_out_test'
def get_set_offset(params):
# 获取和设置记录用户的偏移量
customer_id = params['customer_id']
customer_method = params['customer_method']
import redis
conn_redis = redis.Redis(host='localhost', port=6379, db=2, password='')
if customer_method == 'set':
conn_redis.incr('kafka_offset_data_customer_%s'%customer_id,amount=1)
else:
offset = conn_redis.get('kafka_offset_data_customer_%s' % customer_id)
return int(offset.decode('utf-8')) if offset else 0
def kafka_customer_handle(*args,**kwargs):
# kafka消费数据
servers = ','.join(kwargs['servers']) # '127.0.0.1:9092,127.0.0.2:9092,127.0.0.3:9092'
client = KafkaClient(hosts=servers)
topic = client.topics[topic_name]
consumer = topic.get_simple_consumer(consumer_group=kwargs['topic_name'], auto_commit_interval_ms=1, auto_commit_enable=True,consumer_id=b'rpo')
# 获取topic物理上的分组
partition = topic.partitions[0]
# 获取偏移量
offset = get_set_offset({'customer_id':kwargs['customer_id'],'customer_method':'get'})
# 获取偏移量及设置偏移量
prev_offset = kwargs['prev_offset'] # 意味着每次向前取n-1条
consumer.reset_offsets([(partition, offset-prev_offset)])
number = 0
for message in consumer:
value = json.loads(message.value.decode(encoding='utf-8'))
number += 1
if offset ==0 or (number > 3 and offset!=0):
get_set_offset({'customer_id':kwargs['customer_id'],'customer_method':'set','offset':1})
print(value,message)
kafka_customer_handle(**{'servers':servers,'topic_name':topic_name,'customer_id':'zhen','prev_offset':4})
重点
设置偏移量: customer.reset_offsets([partition,读取消息的位置])
值自增: 字符串.incr(key,amount=1)
再学点 ! ! !

















 1263
1263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









