






 文章介绍了Cache的基本概念,强调其在提升处理器取数据速度中的作用。直接映射缓存将Cache分为固定大小的块,每个块包含数据和标签信息。两路组相连缓存则将Cache分为两部分,提供更大的地址映射灵活性,从而优化数据访问效率。
文章介绍了Cache的基本概念,强调其在提升处理器取数据速度中的作用。直接映射缓存将Cache分为固定大小的块,每个块包含数据和标签信息。两路组相连缓存则将Cache分为两部分,提供更大的地址映射灵活性,从而优化数据访问效率。
Cache 学习
Cache指的是高速缓存简称缓存,原始意义是指访问速度比一般随机存取存储器(RAM)快的一种RAM,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。
Cache的容量大小一般只有1KB到32KB,而这相较于内存存储的几个GB甚至TB的数据来说,Cache的容量是微乎其微的,Cache只能缓存内存的一小部分数据,但是Cache依然能够让处理器取到大部分需要的数据,其中的原理是内存中“程序执行与数据访问的局域性行为”
直接映射缓存
cache的大小被称为 cache size,表示cache可以缓存的最大数据的大小,我们将cache平均分为很多块,每一块被称为cache line,其大小为cache line size。
现在的硬件设计中,一般cache line的大小是4-128 Bytes。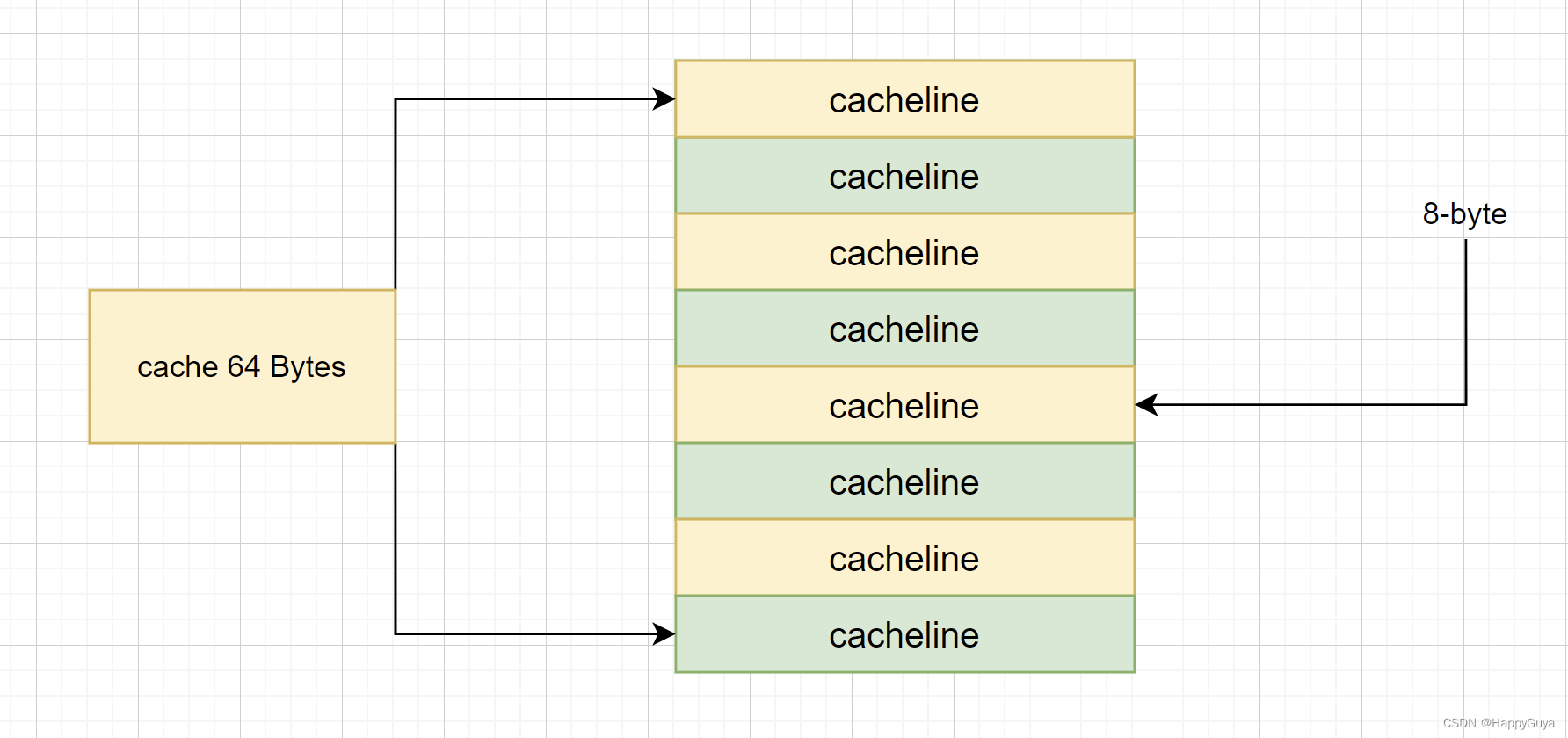
cache与主存之间的对应,在硬件中完成,从而确保了较小的cache能够映射到更大的主存中。
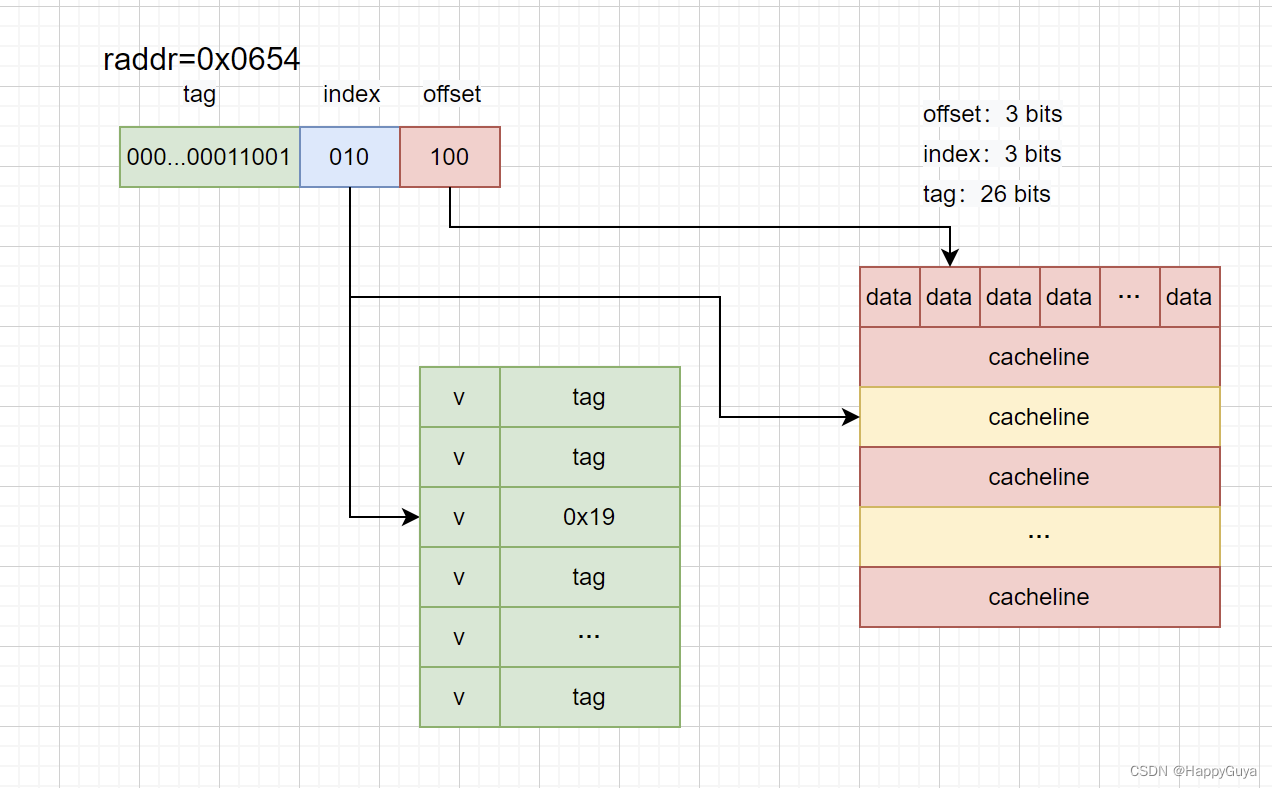
上面是一个例子,8行cachelin,每个大小为 8个字节,上述图片中,index利用三位来映射cache编号,offset利用三位来映射字节编号,引入tag array区域,tag array和data array一一对应。每一个cache line都对应唯一一个tag,tag中保存的是整个地址位宽去除index和offset使用的bit剩余部分。
为什么不用1byte作为cacheline,因为每个cacheline中都放有tag的信息,如果每个都有tag的信息那么会浪费很大的内存。
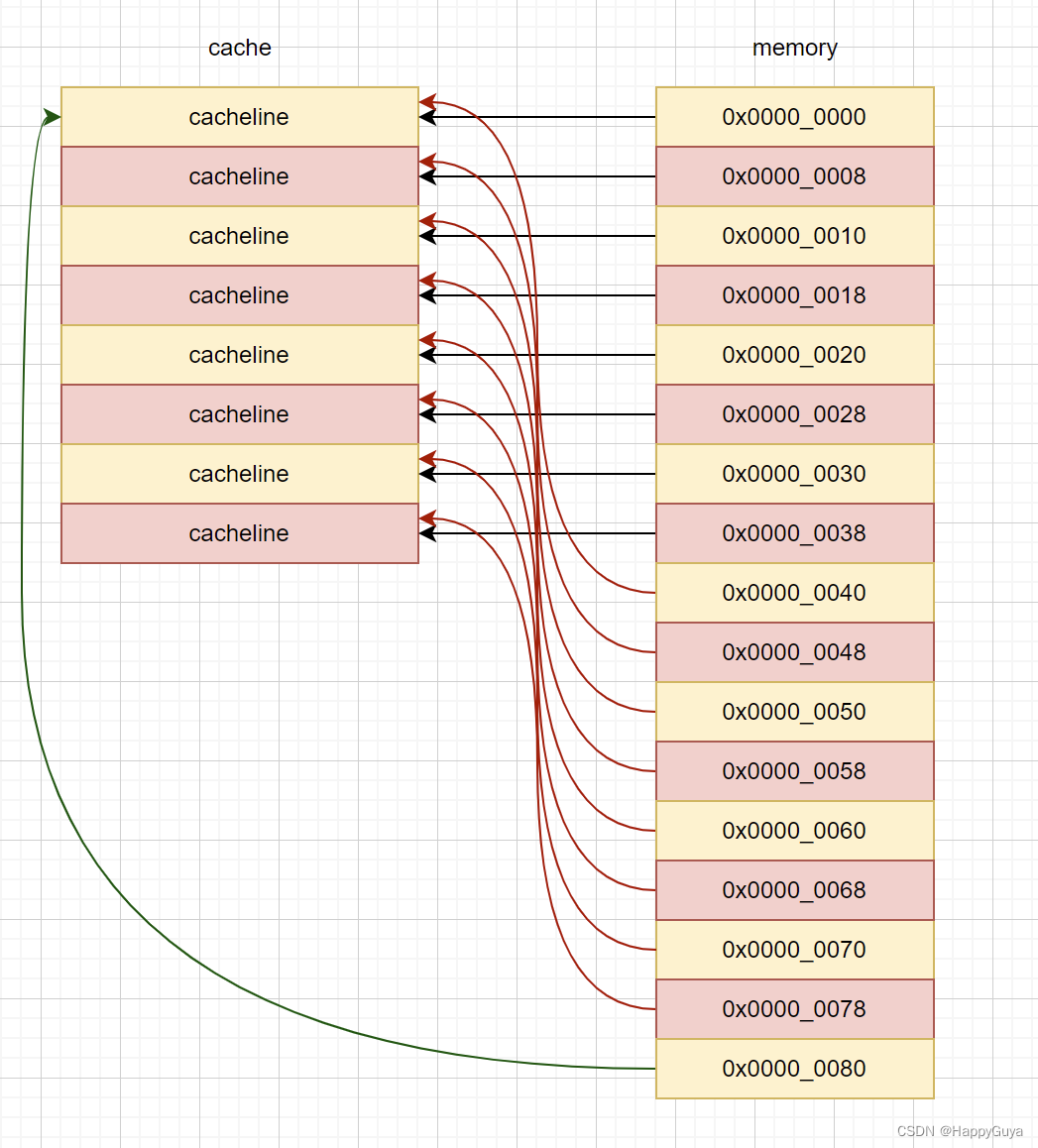
上述是一个直接缓存相连的例子,此时,若读取0x00的信息,cache缺失,cpu从主存中读取数据,随后读取0x40的信息,cache仍然确缺失,cpu从主存中读取数据,随后读取0x80的信息,仍然缺失,本质上和读取主存没有任何区别,并且浪费了更多的时间在控制的过程中。
两路组相连缓存(Two-way set associative cache)
我们依然假设64 Bytes cache size,cache line size是8 Bytes。什么是路(way)的概念。我们将cache平均分成多份,每一份就是一路。因此,两路组相连缓存就是将cache平均分成2份,每份32 Bytes。如下图所示。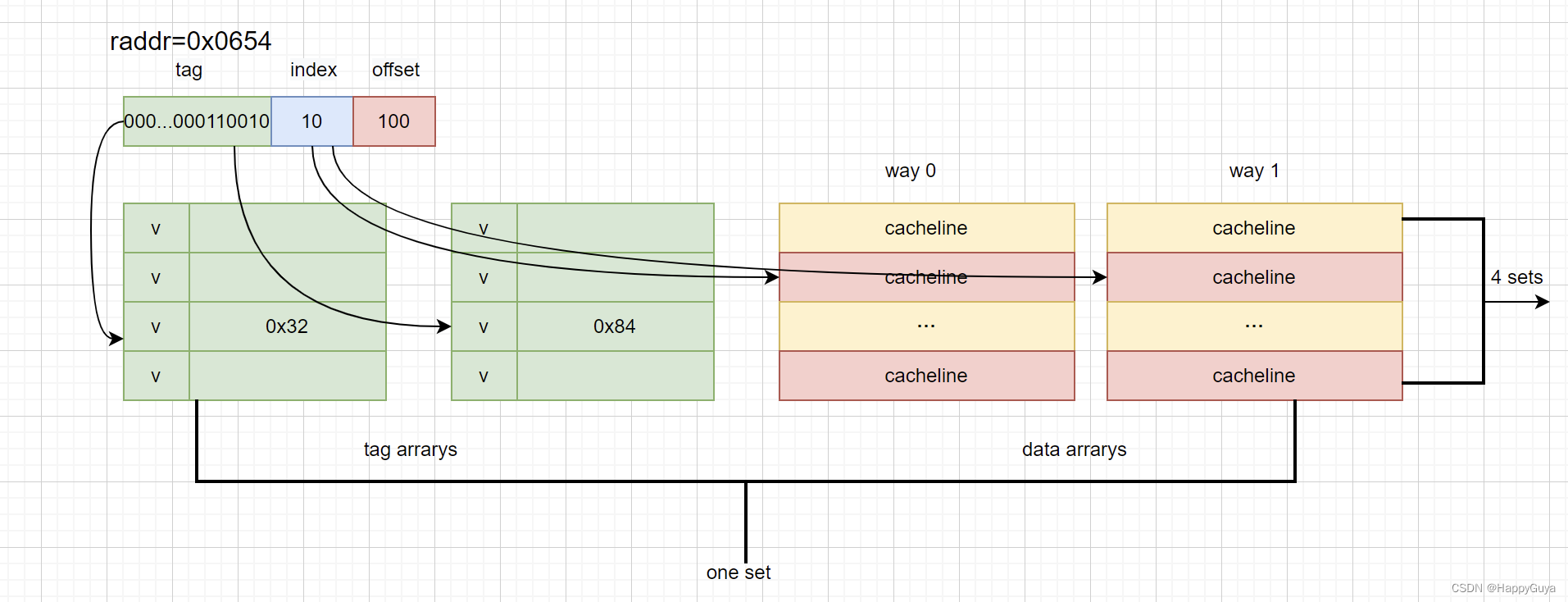

















 2951
2951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









