




有如下场景:
某公司网站每日访问量达到10亿级别的访问量,每次访问记录一条数据,数据包含如下字段:用户ID,访问时间(毫秒级),访问页面。
要求使用hive求出所有在5分钟内访问次数达到100次的用户(求出用户ID即可)
思路:利用窗口函数Lag
详细思路:
1.选出当天访问次数达到100次的用户(即当天有100及以上条数据的用户):根据用户ID分组,count
2.在每个 用户ID小组内(步骤1已进行分组)按 访问时间进行升序排序
3.计算time-lag(time,100),若time-lag(time,100)<=5601000(毫秒),即为满足条件的用户,筛选出。
HQL语句书写
select t.id from{
select
id,
time-lag(time,100,time-5601000-1) over(partition by id order by time) as time_length
from log
group by id
} t
group by id
having min(time_length)<=5601000
注释:time-lag(time,100,time-5601000-1) 中100表示取前100行的数据,若无前100行的数据,则取默认值time-5601000-1。当去默认值time-5601000-1时,time-(time-5601000-1)为5min零1毫秒,大于5min,不满足条件,后续过滤掉。
ps:该HQL只表示大致思路,有优化空间。
拓展思考:该方式为离线分析,若要实时分析,改如何实现?
补充知识点:
LAG和LEAD函数
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,
第二个参数为往上第n行(可选,默认为1),
第三个参数为默认值(当往上第n行为NULL时候,则为null,如超出指定的行数怎可以自己定义字段)
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,
第二个参数为往下第n行(可选,默认为1),
第三个参数为默认值(当往下第n行为NULL时候,则为null,如超出指定的行数怎可以自己定义字段)
=================================================
二
需求:每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数,结果数据格式如下
字段解释: aname(名字),amon(月份),access(访问次数)
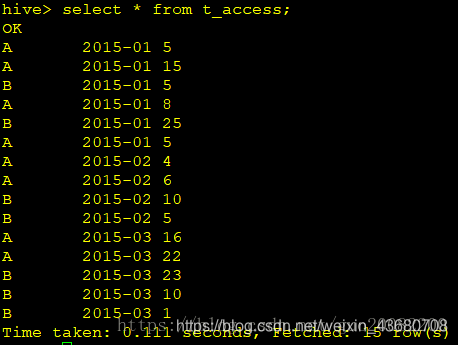
最终结果是这个样子的:
select tt.aname,tt.amon,tt.t_acount max(acount) over (partition by tt.aname order by tt.amon ) max_access sum(t_acount) over (partition by tt.aname order by tt.amon ) sum_access from (select aname,amon,count(access) acount from t_access group by aname,amon order by aname,amon )tt
=================================
三.
有一张很大的表:TRLOG
该表大概有2T左右
TRLOG:
CREATE TABLE TRLOG
(PLATFORM string,
USER_ID int,
CLICK_TIME string,
CLICK_URL string)
row format delimited
fields terminated by ‘\t’;
数据:
PLATFORM USER_ID CLICK_TIME CLICK_URL
WEB 12332321 2013-03-21 13:48:31.324 /home/
WEB 12332321 2013-03-21 13:48:32.954 /selectcat/er/
WEB 12332321 2013-03-21 13:48:46.365 /er/viewad/12.html
WEB 12332321 2013-03-21 13:48:53.651 /er/viewad/13.html
WEB 12332321 2013-03-21 13:49:13.435 /er/viewad/24.html
WEB 12332321 2013-03-21 13:49:35.876 /selectcat/che/
WEB 12332321 2013-03-21 13:49:56.398 /che/viewad/93.html
WEB 12332321 2013-03-21 13:50:03.143 /che/viewad/10.html
WEB 12332321 2013-03-21 13:50:34.265 /home/
WAP 32483923 2013-03-21 23:58:41.123 /m/home/
WAP 32483923 2013-03-21 23:59:16.123 /m/selectcat/fang/
WAP 32483923 2013-03-21 23:59:45.123 /m/fang/33.html
WAP 32483923 2013-03-22 00:00:23.984 /m/fang/54.html
WAP 32483923 2013-03-22 00:00:54.043 /m/selectcat/er/
WAP 32483923 2013-03-22 00:01:16.576 /m/er/49.html
…… …… …… ……
需要把上述数据处理为如下结构的表ALLOG:
CREATE TABLE ALLOG
(PLATFORM string,
USER_ID int,
SEQ int,
FROM_URL string,
TO_URL string)
row format delimited
fields terminated by ‘\t’;
整理后的数据结构:
PLATFORM USER_ID SEQ FROM_URL TO_URL
WEB 12332321 1 NULL /home/
WEB 12332321 2 /home/ /selectcat/er/
WEB 12332321 3 /selectcat/er/ /er/viewad/12.html
WEB 12332321 4 /er/viewad/12.html /er/viewad/13.html
WEB 12332321 5 /er/viewad/13.html /er/viewad/24.html
WEB 12332321 6 /er/viewad/24.html /selectcat/che/
WEB 12332321 7 /selectcat/che/ /che/viewad/93.html
WEB 12332321 8 /che/viewad/93.html /che/viewad/10.html
WEB 12332321 9 /che/viewad/10.html /home/
WAP 32483923 1 NULL /m/home/
WAP 32483923 2 /m/home/ /m/selectcat/fang/
WAP 32483923 3 /m/selectcat/fang/ /m/fang/33.html
WAP 32483923 4 /m/fang/33.html /m/fang/54.html
WAP 32483923 5 /m/fang/54.html /m/selectcat/er/
WAP 32483923 6 /m/selectcat/er/ /m/er/49.html
…… …… …… ……
PLATFORM和USER_ID还是代表平台和用户ID;SEQ字段代表用户按时间排序后的访问顺序,FROM_URL和TO_URL分别代表用户从哪一页跳转到哪一页。对于某个平台上某个用户的第一条访问记录,其FROM_URL是NULL(空值)。
纯sql解法:
成功了
select
platform,
user_id,
row_number() over(partition by user_id order by click_time) SEQ,
lag(click_url,1,‘null’) over(partition by user_id order by click_time) from_url,
click_url
from
trlog;
思路一,第一个值变不成null 因为第一个值永远在窗口范围内,可以在结果出来之后替换
SELECT
TRLOG.PLATFORM,
TRLOG.USER_ID,
TRLOG.CLICK_TIME,
ROW_NUMBER() OVER(PARTITION BY USER_ID ORDER BY CLICK_TIME) AS SEQ,//这一步计算的日期的顺序
FIRST_VALUE(CLICK_URL) OVER(PARTITION BY USER_ID ORDER BY CLICK_TIME ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS FROM_URL ,//这一步计算的是前一个窗口到当前行的第一个值
FIRST_VALUE(CLICK_URL) OVER(PARTITION BY USER_ID ORDER BY CLICK_TIME ROWS BETWEEN CURRENT ROW AND FOLLOWING) AS FROM_URL //这一步计算的是当前窗口到最后一行窗口中的第一个值
求:所有数学课程成绩 大于 语文课程成绩的学生的学号
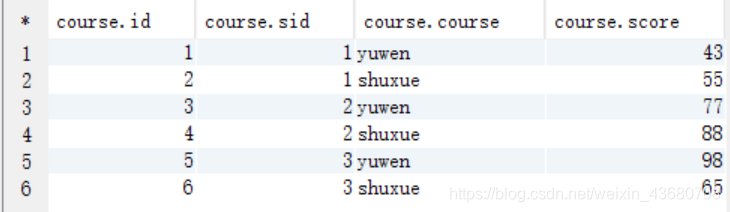
思路一使用with as
with q1 as (select sid,score from course where course ='shuxue'),//拿出姓名和数学成绩
q2 as (select sid,score from course where course='yuwen')//拿出姓名和语文成绩
select q1.sid from q1 join q2 on q1.sid=q2.sid and q1.score>q2.score;//用on和where感觉区别不大
思路二使用case when
select
sid
from
(select
sid,
max(case when course='yuwen' then score else 0 end) yuwen ,
max(case when course ='shuxue' then score else 0 end) shuxue
from course
group by sid) tt
where shuxue >yuwen;
---------------
需求:现在要求使用hive,计算每一年出现过的最大气温的日期+温度。
解释:2010012325表示在2010年01月23日的气温为25度
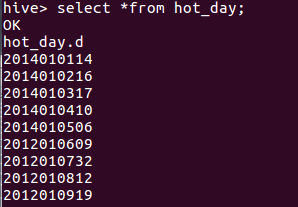
思路一用的自关联才能拿到具体的日期
select
tt.hot,
ttt.dys
from
(select
max(hot) hot,
dt
from
(select
substr(d,1,4) dt,
substr(d,9)hot
from
hot_day ) t
group by dt) tt //这个表里面拿到是年份里最热的温度,因为本想在这里拿具体日期,但是后面的group by 很尴尬要么就也得加上日期这样就没有意义了,所以我选择了自关联让下一个表拿具体的时间
join
(select
substr(d,9)hot,
substr(d,1,4) dt,
substr(d,1,8) dys
from
hot_day) ttt //这个表的作用就是拿出具体的时间 与上面表的年份对比
on tt.hot=ttt.hot and tt.dt=ttt.dt;//先是温度判断,再是年份判断就可以保证质量了
------------------
编写Hive的HQL语句求出每个店铺的当月销售额和累计到当月的总销售额
shopping.shop shopping.mon shopping.money
a 01 150
a 01 200
b 01 1000
b 01 800
c 01 250
c 01 220
b 01 6000
a 02 2000
a 02 3000
b 02 1000
b 02 1500
c 02 350
c 02 280
a 03 350
a 03 250
思路先求出每个月的销售金额然后在使用窗口函数
select //利用窗口函数很轻松的出来了
shop,
mon,
sum(money) over(partition by shop order by mon) money
from
(select //计算每个月的销售金额
shop,
mon,
sum(money) money
from
shopping
group by
shop,
mon) t1;

















 2622
2622



 到【灌水乐园】发言
到【灌水乐园】发言







