







原文地址:DenseASPP
收录:CVPR2018
代码: PyTorch
目录
3.2 更加密集的特征金字塔和更大的 receptive field
2.Visualization of receptive field 感受野可视化
3. Illustration of scale diversity 规模多样性的阐述
设计的Idea:DenseNet 实际上是 DenseNet + ASPP(Deeplab)的结合体。
DenseNet can be viewed as a special case of DenseASPP by setting dilation rate as 1. 因此,DenseASPP 拥有DenseNet的优点: alleviating gradient-vanishing problem 和substantially fewer parameters
摘要
objects in autonomous driving exhibit very large scale changes, which poses great challenges for high-level feature representation in a sense that multi-scale information must be correctly encoded.
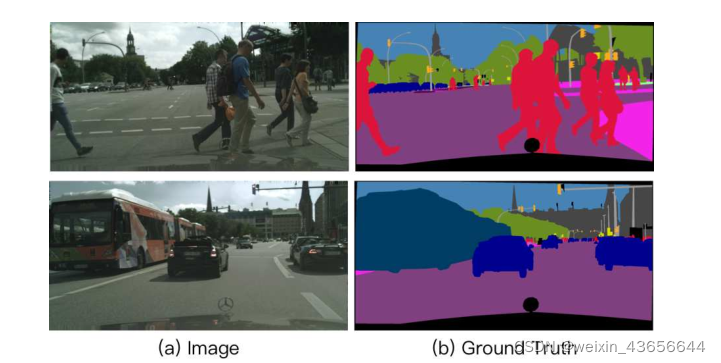
如图一,人的大小在变化;图二中,离的很近的公交车,非常远的小车
为了解决这个问题,atrous convolution 被提出。 Atrous Spatial Pyramid Pooling (ASPP) in DeepLab V3 was proposed to concatenate multiple atrous-convolved features using different dilation rates into a final feature representation.
But feature resolution in the scale-axis is not dense enough for the autonomous driving scenario.
So we propose Densely connected Atrous Spatial Pyramid Pooling (DenseASPP), which connects a set of atrous convolutional layers in a dense way, such that it generates multi-scale features that not only cover a larger scale range, but also cover that scale range densely, without significantly increasing the model size.
1.Introduction
高级特征对我们的分割很有作用。To extract high level information, FCN uses multiple pooling layers to increase the receptive field size of an output neuron.但是做下采样和池化,会降低图片分辨率。 However, increased number of pooling layers leads to reduced feature map size, which poses serious challenges to up-sample the segmentation output back to full resolution. 另一外面,我们又不能不增大感受野。 if we output the segmentation from an early layer with larger resolution, we were not able to make use of higher level semantics for better reasoning.
这个时候空洞卷积就派上用场了。A feature map produced by an atrous convolution can be as the same size as the input, but with each output neuron possessing a larger receptive field, and therefore encoding higher level semantics.
但空洞卷积还是有缺点的:1. 生成单一scale的特征图。all neurons in the atrous-convolved feature map share the same receptive field size, which means the process of semantic mask generation only made use of features from a single scale. 这一点上ASPP能解决
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 208
208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









