







1.pytorch softmax 中参数 dim 的理解
在上周我发现我训练的测试集样本都很低,我本以为是输入到的loss出现了问题,后来才发现对于softmax中dim=1我将其设置为0,导致精度,为此我了解了一下参数dim的意义!
pytorch softmax 中参数 dim 的理解_GISer and Coder的博客-优快云博客_softmax的dim
具体解释为:
当 dim=0 时,是对每一维度相同位置的数值进行softmax运算;
当 dim=1 时,是对某一维度的列进行softmax运算;
当 dim=2 或 -1 时,是对某一维度的行进行softmax运算;

2.卷积padding参数
padding操作,以保证图像输入输出前后的尺寸大小不变
self.conv = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=7, padding=3)
padding,即边缘填充,可以分为四类:零填充,常数填充,镜像填充,重复填充。
3.鲁棒性和泛化性
鲁棒性、泛化 的解释和区别_wxianyou的博客-优快云博客_鲁棒性和泛化性
鲁棒性:
- 鲁棒是Robust的音译,也就是健壮和强壮的意思。它是在异常和危险情况下系统生存的关键。
- 在深度学习中常用于形容算法模型,当说算法模型具有鲁棒性时,表明对这个算法模型而言,一些异常的数据对整体的性能影响不大或者基本没有影响。
泛化性:
- 泛化能力指算法模型对未知数据的预测能力。
- 学习的目的是学到隐含在数据背后的规律,对具有同一规律的学习集以外的数据经过训练的网络也能给出合适的输出,该能力称为泛化能力。
4.端到端
5.注意力机制、
6.元级网络、元信息、元学习器
元学习(meta-learning)也叫做学会学习,是机器学习领域一个前沿的研究框架,针对于解决模型如何学习的问题。元学习的目的是让模型获得一种学习能力,这种学习能力可以让模型自动学习到一
些元知识,比如模型的超参数、神经网络初始参数、神经网络结构和优化器等。
7.agrmax 和softmax
pre = torch.max(F.softmax(prediction_y, dim=1), 1)[1]
pre = prediction_y.argmax(dim=1)这两个似乎是等价的,softmax是进行归一化,torch.max返回最大值标签
agrmax返回最大值标签
8.Dropout
针对全连接,在训练过程中随机地忽略一定比例的节点响应,减轻了传统全连接神经网络的过拟合问题。
9.conv2D、conv1D
conv2D一般情况用于图像,而conv1D用于nlp方面

拿这个为例子:
Conv2D,指定卷积核的大小为(2,8) 。
Conv1D,只需要指定卷积核的大小为2,因为每一行表示的是词向量,代表这个词的内容。
简便理解的话就是Conv2D是先横再竖,Conv1D就是竖着来。
10 自监督
模型直接从无标签数据中自行学习,无需标注数据。
自监督学习的核心,在于如何自动为数据产生标签。
自监督学习性能的高低,主要通过模型学出来的feature的质量来评价。feature质量的高低,主要是通过迁移学习的方式,把feature用到其它视觉任务中(分类、分割、物体检测...),然后通过视觉任务的结果的好坏来评价。目前没有统一的、标准的评价方式。
11.动态规划
原理就是利用前面的数值来快速计算该位置数值,达到一个减少空间和时间复杂度的效果,可参考爬楼梯。
12.BN,IN,LN,GN
BN适用于判别模型中,但是BN对batchsize的大小比较敏感,一般推荐较大batchsize.
IN适用于生成模型中,比如图片风格迁移。
Layer Normalization (LN) 的一个优势是不需要批训练,在单条数据内部就能归一化,所以用在RNN中比较多。
Group Normalization (GN) 适用于占用显存比较大的任务,batchsize可能为个位数的情况。
四图秒懂BN、LN和IN_罗小丰同学的博客-优快云博客_bn in ln\
这个博主讲的通俗易懂,及其nice
BN
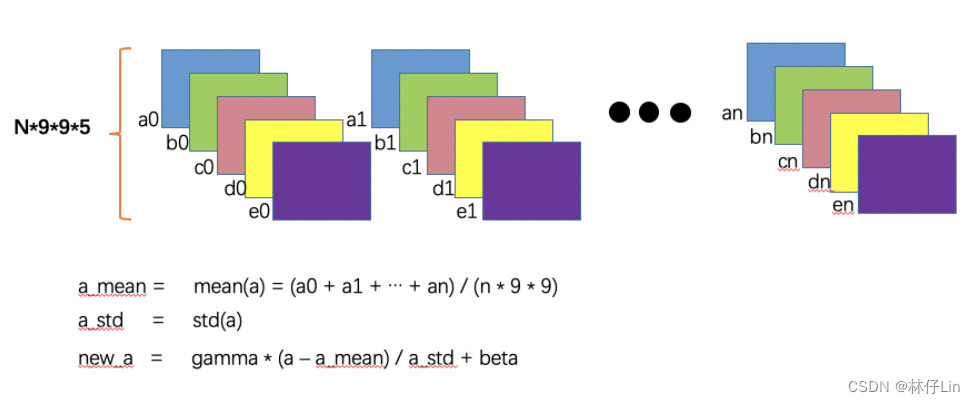
BN做了一件什么事呢。
(1)把不同batch_size的同一个channel的feature map进行求均值,得到mean
(2)把不同batch的同一个channel的feature map进行求标准差,得到std
(3)最后对每一个channel的每一个feature map减去对应channel的mean,再除以std,就得到了新的N*9*9*5的feature maps
LN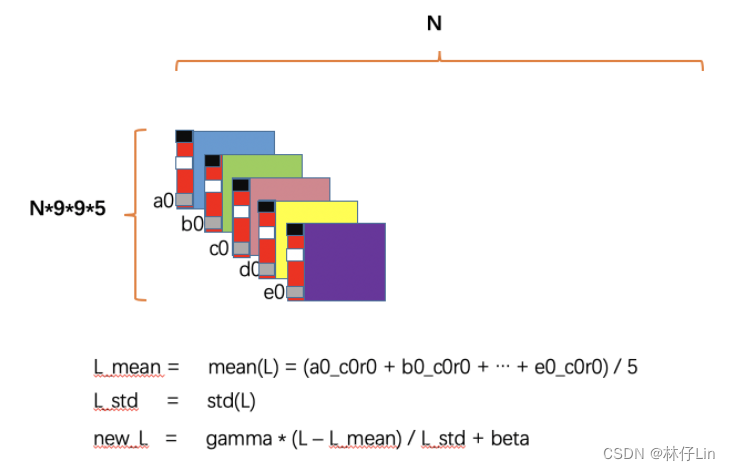
(1)第一梯队的所有通道的第一列的第一行,听清楚了,是第一列的第一行,给到我你们的均值(mean)
(2)给完以后,给到我你们的标准差(std)
(3)然后:把你们的数值减去mean,再除以std
(4)接着我会给你们一个gamma,把结果乘上去;还有一个beta,加上去
(5)OK,第一梯队的所有通道的第一列的第一行,给我最终结果。
(6)接下来,第一梯队的所有通道的第一列的其他行,按照第一列第一行的步骤,开始!
(7)接下来,第一梯队的所有通道的其他列,按照第一列步骤,开始!
(8)其他梯队,按照第一梯队的流程,GO!
这就是(才是实战中的)LN
IN
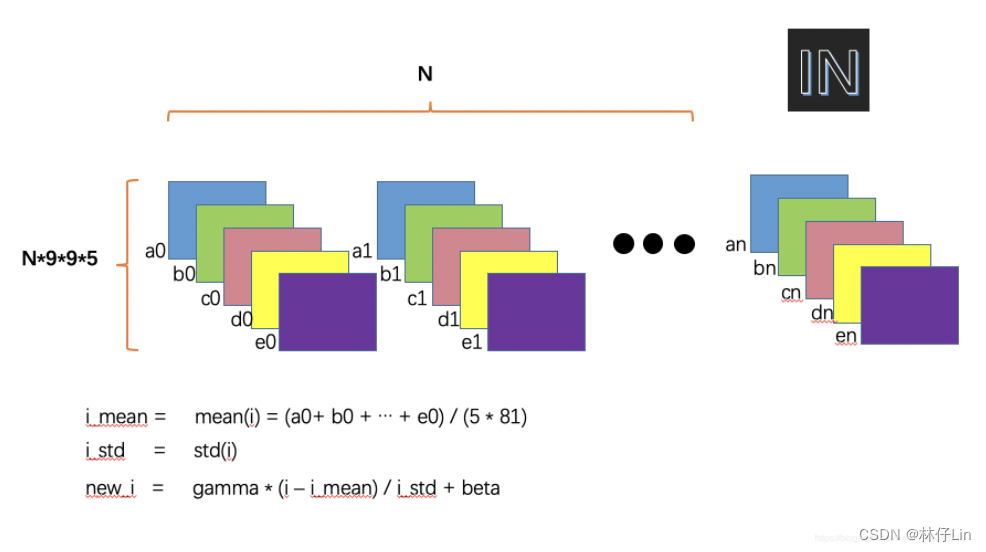
(1)第一梯队,给出你们所有通道所有行所有列的均值(mean)
(2)第一梯队,给出标准差(std)
(3)乘上gamma和beta,在给到我
(4)其他梯队,跟上!
13 交叉验证
sfolder = StratifiedKFold(n_splits=CFG.fold, random_state=CFG.seed, shuffle=True)
train_folds = []
val_folds = []
for train_idx, val_idx in sfolder.split(train_df.image, train_df.label_index):
train_folds.append(train_idx)
val_folds.append(val_idx)用于将训练集变成训练集和验证集,查看训练集精度

















 2963
2963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









