




 本文探讨了深度学习中常见的问题及解决方案,包括处理分类任务时的标签越界错误、神经网络权重初始化方法的选择、自定义评分函数以优化模型、利用层冻结进行迁移学习、调整学习率策略以及固定随机种子确保实验可复现性。
本文探讨了深度学习中常见的问题及解决方案,包括处理分类任务时的标签越界错误、神经网络权重初始化方法的选择、自定义评分函数以优化模型、利用层冻结进行迁移学习、调整学习率策略以及固定随机种子确保实验可复现性。
1. IndexError: Target ** is out of bounds.
在做分类情况中,我只有10分类的情况,所以在最后维度输出也是10,但是最终还是报IndexError: Target 10 is out of bounds。
后来查了情况,说是因为标签是从1开始的原因,导致出现了这种情况
解决方法:
1.改变标签的起始,改成0开始(未尝试)
2.将最终的输出维度增加1来测试
2.神经网络初始值设置
(参考文献 : 如何选择合适的初始化方法 | 神经网络的初始化方法总结 - 知乎)
在做实验的过程中发现每次运行的结果可能很好,可能没有达到理想结果。
对于梯度消失问题,权重更新很小,导致收敛速度变慢,在最坏的情况下,可能会阻止网络完全收敛。相反,使用过大的权重进行初始化可能会导致在前向传播或反向传播过程中梯度值爆炸。
常见的初始化方法:
1. 全零或等值初始化
2. 正态初始化(Normal Initialization)
均值为零,标准差设置一个小值。这种正常的随机初始化方法不适用于训练非常深的网络,尤其是那些使用 ReLU激活函数的网络。
3. 均匀初始化(Uniform Initialization)
均匀分布的区间通常为【-1/sqrt(fan_in),1/sqrt(fan_in)】
其中fan_in表示输入神经元的数量,fan_out表示输出神经元的数量。
4. Xavier Initialization、
根据sigmoid函数图像的特点,它在初始化权重时考虑了网络的大小(输入和输出单元的数量)。这种方法通过使权重与前一层中单元数的平方根成反比来确保权重保持在合理的值范围内。
两个变体:
Xavier Normal:正态分布的均值为0、方差为sqrt( 2/(fan_in + fan_out) )。
Xavier Uniform:均匀分布的区间为【-sqrt( 6/(fan_in + fan_out)) , sqrt( 6/(fan_in + fan_out))】。
Xavier 初始化适用于使用tanh、sigmoid为激活函数的网络。
5. He Initialization
He Initialization也有两种变体:
He Normal:正态分布的均值为0、方差为sqrt( 2/fan_in )。
He Uniform:均匀分布的区间为【-sqrt( 6/fan_in) , sqrt(6/fan_in) 】
He Initialization适用于使用ReLU、Leaky ReLU这样的非线性激活函数的网络。
6. Pre-trained
使用预训练的权重作为初始化,相比于其它初始化,收敛速度更快,起点更好。
3.GridSearchCV自定义score
以svm为例子
def get_score(actual, predic): #这个格式是固定的
...
from sklearn.metrics import make_scorer
new_score = make_scorer(get_score,greater_is_better = False)#设置自己的score
grid = GridSearchCV(SVC(), param_grid={"C":[0.1, 1, 10], "gamma": [1, 0.1, 0.01]}, cv=4,scoring=new_score)
grid.fit(x, y.ravel())
print(grid.grid_scores_, grid.best_params_, grid.best_score_)4.层冻结训练方法
看了一下迁移学习,对层冻结这个知识点存在盲区,稍微查看了一下资料,总结如下:
迁移学习一般情况是想要用大样本学习后的模型进行迁移用于小样本上面,但是在大样本学习的过程中,模型的参数是已经训练好的,我们不希望在后续的学习上面改变这些参数权重,所以使用了层冻结方法,一般情况都是针对除全连接层之前的所有层,在图像中也是针对backbone模块,比如LeNet5、AlexNet、VGG等。这边在网上看到一个例子,这边是设置了两层lstm模型,针对一般情况,就是把红框框里面的模型都冻结住,因为activation这边就是softmax层了。
for layer in model.layers [:-3]:
print(layer.name)
layer.trainable = False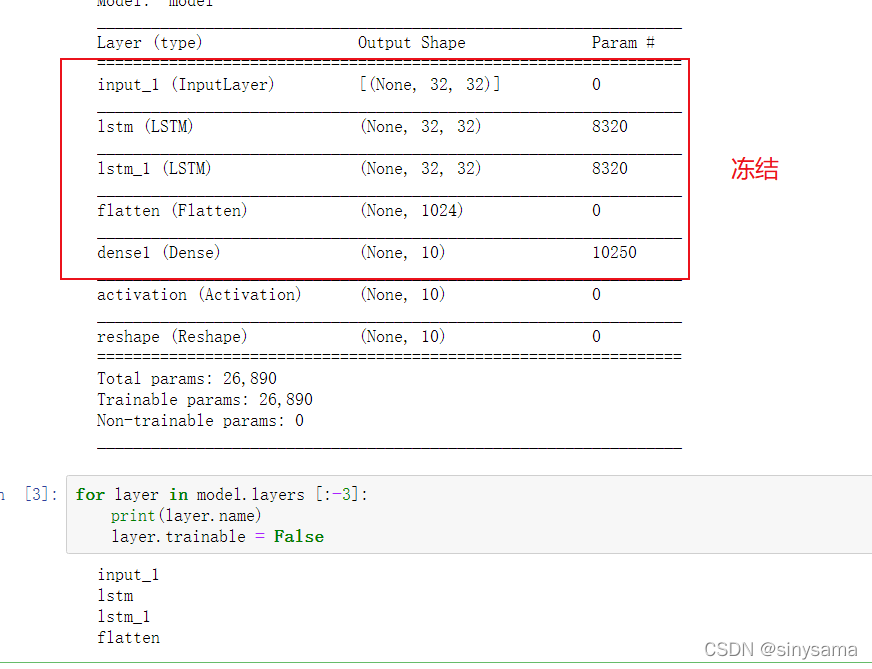
5.torch.optim.lr_scheduler.StepLR()加快收敛速度!
trainer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9,weight_decay=wd)
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)
第一个参数就是所使用的优化器对象
因为过大的学习率会导致在最低点来回震荡,而较小的学习率能更好的接近最优解,可以用来加快收敛速度!
所以间隔一段迭代后将学习率调小一下有助于找到最优解,即每隔setp_size 将学习率乘以gamma替换:lr = lr *gamma
代码实现:torch.optim.lr_scheduler:调整学习率_qyhaill的博客-优快云博客_lr_scheduler
6.torch.max()
_, pre_labels = torch.max(outputs, 1)
torch.max(outputs, 1) 其中这个 1代表行,0的话代表列。
torch.max返回两个值,一个是最大的概率值,一个是索引(从0开始)。
6.固定随机种子
torch.manual_seed(3407) is all you need
调参只需随机种子:torch.manual_seed(3407) is all you need? - 知乎
(还得是炼丹鬼才!)
在训练神经网路过程中,我发现明明代码没改,但是每次运行他的最好结果都不一样,经过了解才知道,应该是初始化或者训练过程中参数变化随机性造成的,可以举一个简单的传统模型:
K-means:比如需要设置5类,其最开始就要随机设置五个点作为起始中心点,而好的初始化同样会影响结果!
这边以torch为例子,但是好像在训练过程参数随机性需要通过别的方法固定,了解不深。
一般设置在网络训练前!
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
# 设置随机数种子
setup_seed(3407)


















 5591
5591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









