




 该博客详细介绍了如何利用Keras在MNIST数据集上构建并训练手写数字识别模型。从文件目录结构、代码解析、数据预处理到模型定义、训练与保存、模型测试,作者一步步展示了完整的流程。通过数据预处理,将CSV数据归一化并转换为模型所需的格式。训练了一个简单的三层神经网络,并在测试集上进行了评估,得到了损失函数曲线和预测准确率。
该博客详细介绍了如何利用Keras在MNIST数据集上构建并训练手写数字识别模型。从文件目录结构、代码解析、数据预处理到模型定义、训练与保存、模型测试,作者一步步展示了完整的流程。通过数据预处理,将CSV数据归一化并转换为模型所需的格式。训练了一个简单的三层神经网络,并在测试集上进行了评估,得到了损失函数曲线和预测准确率。
文章目录
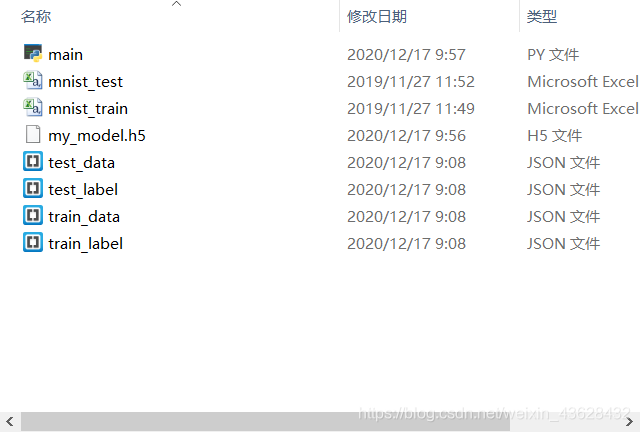
1. 文件目录结构
文件目录如下,依次为:
- 主程序
- MNIST测试数据集
- MNIST训练数据集
- 训练好的BP神经网络模型
- 测试数据
- 测试数据的标签
- 训练数据
- 训练数据的标签
2. 代码解析
(1)模块导入部分:
import json
import matplotlib.pyplot as plt
import numpy as np
from keras.models import Sequential,load_model
from keras.layers import Dense,Activation
from keras.optimizers import SGD
解析:
- JSON模块用来存储预处理好的训练数据以及测试数据;使用JSON模块的好处是只需进行一次预处理,后续的过程或者改进无需在数据处理上消耗时间;
- Keras部分:
- Sequential:Keras库中的基础类
- load_model:用于从H5文件中加载模型,同样是为了节省后续操作的时间
- Dense:全连接层
- Activation:激活函数
- SGD:优化函数
(2)路径存储部分:
def __init__(self):
self.mnist_train_path = r'mnist_train.csv'
self.mnist_test_path = r'mnist_test.csv'
self.train_data_path = r'train_data.json'
self.train_label_path = r'train_label.json'
self.test_data_path = r'test_data.json'
self.test_label_path = r'test_label.json'
self.my_model_path = r'my_model.h5'
(3)数据预处理部分
def _get_data(self,orginal_data_path,data_path,label_path):
data,orginal_label = [],[]
with open(orginal_data_path,'r') as f_obj:
for line in f_obj:
line = line.split(',')
orginal_label.append(int(line[0]))
data.append([int(x)/255 for x in line[1:]])
label = []
for item in orginal_label:
myItem = list(np.zeros(10))
myItem[item]< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









