







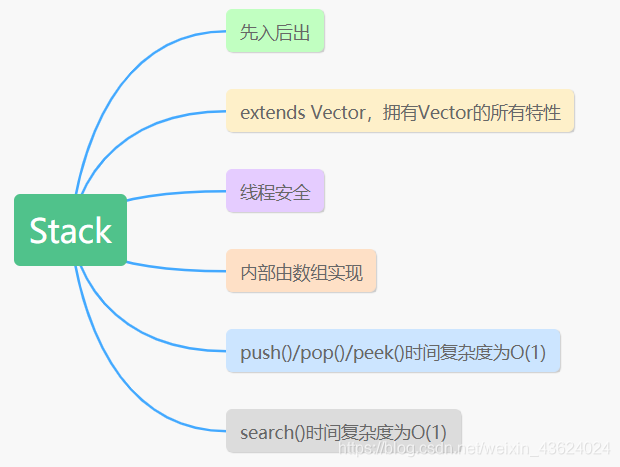
如下图所示,为Stack的一些特性
源码分析
一、 构造器
//Stack的构造器默认调用了Vector的默认构造器 初始化一个长度为10的数组
public Stack() {
//super();
}
//指定初始化容量、增长因子
//若不指定增长因子 则默认扩容为原来的2倍
//这也是Vector和ArrayList的区别之一
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
//调用默认构造 指定初始化容量为10
//顺便一提,ArrayList初始化容量为0
public Vector() {
this(10);
}二、push(),添加元素至栈顶
由于Stack的数据结构是基于Vector实现的,因此pop,push等操作也都基于Vector的API
//将item添加到数组末尾 并返回
public E push(E item) {
addElement(item);
return item;
}
//该addElement属于Vector,底层实现和ArrayList差不多,最大的区别就是扩容时的grow方法
//ArrayList默认扩容1.5倍,Vector若不指定增长因子则默认扩容2倍
//这里就不作过多分析了,具体可以参考ArrayList的源码分析
public synchronized void addElement(E obj) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = obj;
}
三、pop(),删除栈顶元素并返回
public synchronized E pop() {
E obj;
int len = size();
//先通过peek()获取数组末尾的元素
obj = peek();
//然后将末尾元素删除
removeElementAt(len - 1);
return obj;
}四、peek(),返回栈顶元素
public synchronized E peek() {
int len = size();
//若数组为0则抛出空栈异常
if (len == 0)
throw new EmptyStackException();
//返回数组末尾元素
return elementAt(len - 1);
}五、search(),在栈中检索某个元素
public synchronized int search(Object o) {
//从数组末尾开始检索
int i = lastIndexOf(o);
//若i>=0 返回对应元素在栈中所处的位置(与数组index顺序相反)
if (i >= 0) {
return size() - i;
}
return -1;
}
//----------------Vector----------------//
public synchronized int lastIndexOf(Object o) {
return lastIndexOf(o, elementCount-1);
}
public synchronized int lastIndexOf(Object o, int index) {
//若index >= 容器中的元素个数 则抛出异常
if (index >= elementCount)
throw new IndexOutOfBoundsException(index + " >= "+ elementCount);
//若传入obj=null 从index位置向前遍历 寻找到第一个出现的null位置返回
if (o == null) {
for (int i = index; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {//若不为空 从index位置向前遍历 寻找到第一个出现的相同元素位置返回
for (int i = index; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
//未找到返回-1
return -1;
}

















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









