







 本文探讨了特征选择在数据科学中的重要性,包括提高准确性、减少过拟合、加速训练、优化可视化和增强模型可解释性。介绍了Filter Method、Wrapper Method和Embedded Method三种特征选择方法,并通过LASSO Regularization和Recursive Feature Elimination (RFE)举例说明。通过计算特征重要性和递归消除,确定最佳特征子集。
本文探讨了特征选择在数据科学中的重要性,包括提高准确性、减少过拟合、加速训练、优化可视化和增强模型可解释性。介绍了Filter Method、Wrapper Method和Embedded Method三种特征选择方法,并通过LASSO Regularization和Recursive Feature Elimination (RFE)举例说明。通过计算特征重要性和递归消除,确定最佳特征子集。
正好在写这部分,就顺带练习一下吧。
一如既往地,来源:https://towardsdatascience.com/feature-selection-techniques-1bfab5fe0784
数据集:https://www.kaggle.com/uciml/mushroom-classification
减少特征数量的好处有:
- 准确性提高。
- 减少过度拟合。
- 加快训练速度。
- 改进数据可视化。
- 增加模型的可解释性。
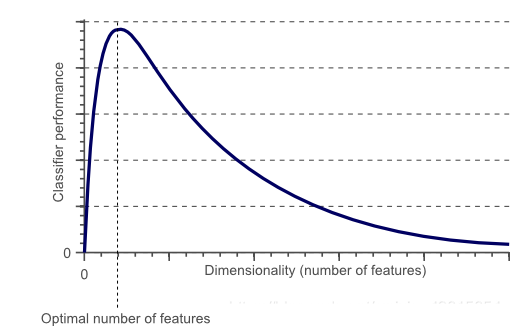
经统计证明,存在用于每个特定任务的最佳特征数量(图1)。如果添加的功能多于严格必要的功能,那么我们的模型性能将下降(由于添加的噪音)。 真正的挑战是找出要使用的最佳功能数量。
见:https://www.visiondummy.com/2014/04/curse-dimensionality-affect-classification/
概念
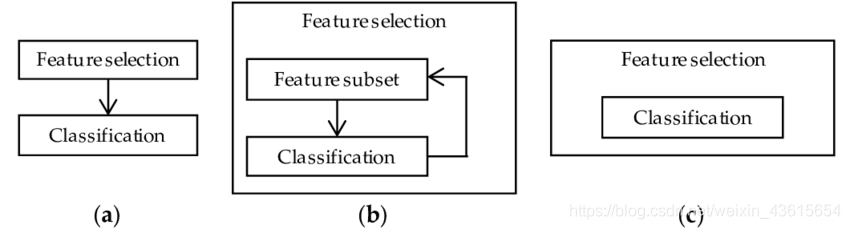
有许多不同的方法可用于特征选择。 一些最重要的是:
- 1.Filter Method
做法:过滤数据集,只取其中的一个子集,包含所有相关的功能。
**具体操作:**使用皮尔逊相关的相关矩阵 - 2.Wrapper Method
做法:使用Forward/Backward/Bidirectional/Recursive Feature Elimination作为评价标准。其结果可能比过滤更准确,但计算量更大。
3.Embedded Method
LASSO Regularization
具体操作
导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import seaborn as sns
from sklearn import preprocessing
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
from sklearn import svm
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









