







由于Blending在集成过程中只会用到验证集的数据,对数据的利用效率低,为了解决这个问题,可以引入交叉验证的方式。Stacking集成学习算法就是基于这个想法。
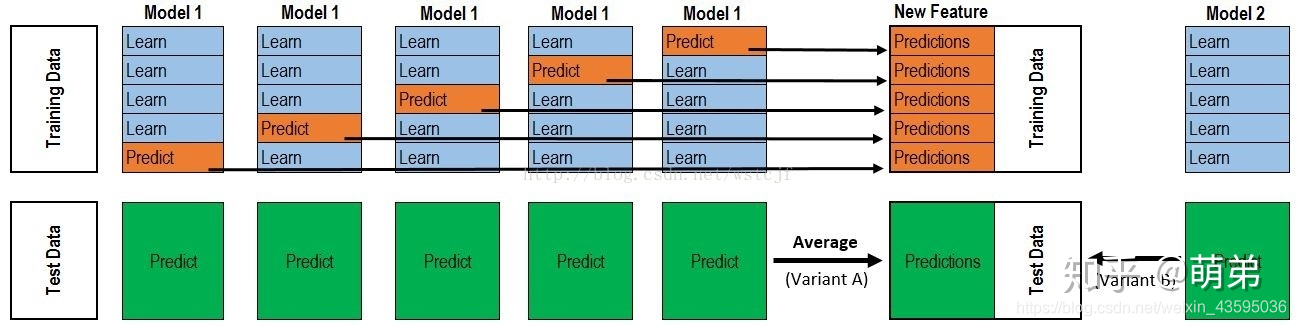
- 首先将所有数据分为训练集和测试集,假设训练集样本数为10000,测试集样本数为2500,对训练集进行5折交叉验证,每次使用训练集中的8000个样本训练模型,剩余2000个样本用来验证(在上图中表示为橙色)。
- 每次验证相当于使用图中蓝色的8000个样本训练出一个模型,每个模型对验证集进行预测,得到2000个预测结果。同时测试集进行预测得到2500个预测结果。经过5折交叉验证,可以得到训练集所有样本在验证时的预测结果,同时也对于测试集所有样本都可得到5个预测结果。
- 接下来将训练集所有样本的预测结果作为新的特征,标记为 A 1 A_1 A1,而对于测试集中每个样本的5个预测结果进行加权平均,得到新的特征,标记为 B 1 B_1 B1。
- 以上基于一个基模型在数据集上得到特征 A 1 , B 1 A_1,B_1 A1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2727
2727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









