






01通用爬虫和聚焦爬虫
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种。
通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网 页下载到本地,形成一个互联网内容的镜像备份。
通用搜索引擎(Search Engine)工作原理
通用网络爬虫 从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着 整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。
基本工作流程图
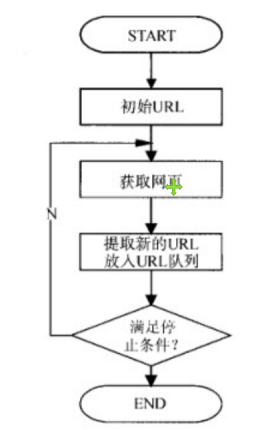
搜索引擎如何获取一个新网站的URL:有以下三种方式
1. 新网站向搜索引擎主动提交网址:
2. 在其他网站上设置新网站外链
3. 和DNS解析服务商(如DNSPod等)合作,新网站域名将被迅速抓取。
爬虫限制
搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内容。
1. rel="nofollow",,告诉搜索引擎爬虫无需抓取目标页,同时告诉搜索引擎无需将的当前页的Pagerank传递到目标页。
2. Robots协议(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
局限性
1.大多情况下,网页里90%的内容对用户来说都是无用的。
2. 搜索引擎无法提供针对具体某个用户的搜索结果。
3. 图片、数据库、音频、视频多媒体等不能很好地发现和获取。
4. 基于关键字的检索,难以支持根据语义信息提出的查询,无法准确理解用户的具体需求。
聚焦爬虫
聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于:聚焦爬虫在实施网页 抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
02HTTP和HTTPS
HTTP协议-80端口
HyperTextTransferProtocol, 超文本传输协议是一种发布和接收HTML页面的方法。
HTTPS-443端口
HypertextTransferProtocoloverSecureSocketLayer, 简单讲是HTTP的安全版,在HTTP下加入SSL 层。
HTTP工作原理
网络爬虫抓取过程可以理解为模拟浏览器操作的过程。
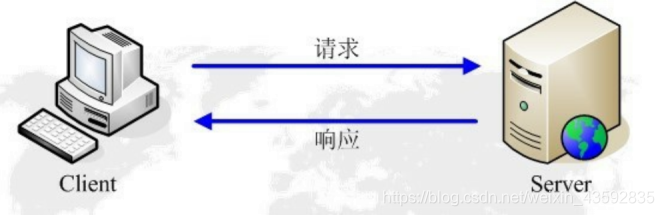
浏览器发送HTTP请求的过程 (重点)
1.当用户在浏览器的地址栏中输入一个URL并按回车键之后,浏览器会向HTTP服务器发送HTTP请求。HTTP请求主要分为“Get”和“Post”两种方法。
2. 当我们在浏览器输入URLhttp://www.baidu.com的时候,浏览器发送一个Request请求去获取http://www.baidu.com的html文件,服务器把Response文件对象发送回给浏览器。
3.浏览器分析Response中的HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
4. 当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
URL的介绍
URL(Uniform/UniversalResourceLocator的缩写):统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种标识方法。
基本格式: scheme://host[:port#]/path/…/[?query-string][#anchor]
query-string:参数,发送给http服务器的数据
http://www.baidu.com?wd=python
anchor:锚(跳转到网页的指定锚点位置)
03客户端HTTP请求
客户端发送一个HTTP请求到服务器的请求消息,包括以下格式:
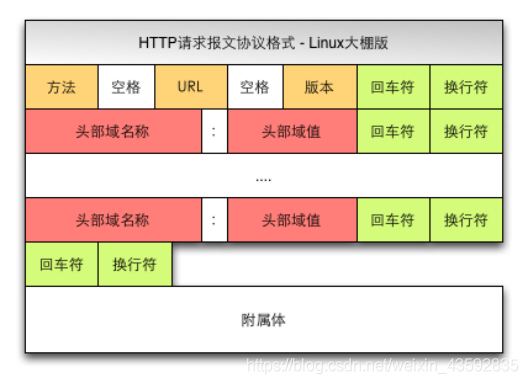
根据HTTP标准,HTTP请求可以使用多种请求方法:
HTTP0.9:只有基本的文本GET功能。
HTTP1.0:完善的请求/响应模型,并将协议补充完整,定义了三种请求方法:GET,POST和HEAD方法。
HTTP1.1:在1.0基础上进行更新,新增了五种请求方法:OPTIONS,PUT,DELETE,TRACE和CONNECT方法。

Get 和 Post 详解
1. GET是从服务器上获取数据,POST是向服务器传送数据
2. GET请求参数显示,都显示在浏览器网址上,即“Get”请求的参数是URL的一部分。
3. POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送,通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传操作等),请求的参数包含在“Content-Type”消息头里,指明该消息体的媒体类型和编码,
常用的请求报头
Host: 主机和端口号
Connection : 客户端与服务连接类型, 默认为keep-alive
User-Agent: 客户浏览器的名称
Accept: 浏览器或其他客户端可以接受的MIME文件类型
Referer:表明产生请求的网页来自于哪个URL
Accept-Encoding:指出浏览器可以接受的编码方式。
Accept-Language:语言种类 Accept-Charset: 字符编码
Cookie:浏览器用这个属性向服务器发送Cookie Content-Type:POST请求里用来表示的内容类型。
04HTTP响应
HTTP响应由四个部分组成,分别是: 状态行 、 消息报头 、 空行 、 响应正文

响应状态码
200: 请求成功
302: 请求页面临时转移至新url
307和304: 使用缓存资源
404: 服务器无法找到请求页面
403: 服务器拒绝访问,权限不够
500: 服务器遇到不可预知的情况
Cookie和Session
服务器和客户端的交互仅限于请求/响应过程,结束之后便断开,在下一次请求时,服务器会认为新的客户端。为了维护他们之间的链接,让服务器知道这是前一个用户发送的请求,必须在一个地方保存客户端的信息。
Cookie:通过在客户端记录的信息确定用户的身份。 Session:通过在服务器端记录的信息确定用户的身份。
########################################################################################
案例展示:
制作爬虫的基本步骤:
1. 需求分析
2. 分析网页源代码,配合F12
3. 编写正则表达式或者其他解析器代码
4. 正式编写python爬虫代码
(1)图片下载器
需求分析:"我想要图片,我又不想上网搜“ "最好还能自动下载" …… 这就是需求,至少要实现两个功能,一是搜索图片,二是自动下载。
运行代码如下所示:
import re
import requests
def downloadPic(html,keyword):
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)[:5]
i = 0
print("找到关键字:"+keyword+"的图片,现在开始下载图片....")
for each in pic_url:
print("正在下载第"+str(i+1)+"张图片,图片地址:"+str(each))
try:
pic = requests.get(each,timeout=10)
except requests.exceptions.ConnectionError:
print("【错误】当前图片无法下载")
continue
string = 'pictures/'+keyword+'_'+str(i)+'.jpg'
fp = open(string,'wb')
fp.write(pic.content)
fp.close()
i+=1
if __name__ == '__main__':
word = input("Input Key Word:")
url = 'http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=+word'
result = requests.get(url)
downloadPic(result.text,word)代码运行结果展示如下:
找到关键字:hello的图片,现在开始下载图片....
正在下载第1张图片,图片地址:http://b-ssl.duitang.com/uploads/item/201502/26/20150226141101_fs2XR.jpeg
正在下载第2张图片,图片地址:http://b-ssl.duitang.com/uploads/item/201711/20/20171120163247_Pk3Ve.jpeg
正在下载第3张图片,图片地址:http://b-ssl.duitang.com/uploads/item/201505/28/20150528121929_EH8sd.jpeg
正在下载第4张图片,图片地址:http://b-ssl.duitang.com/uploads/item/201511/25/20151125234103_kyNVM.jpeg
正在下载第5张图片,图片地址:http://b-ssl.duitang.com/uploads/item/201509/06/20150906105649_m4dHC.jpeg
正在下载第6张图片,图片地址:http://img3.duitang.com/uploads/item/201602/23/20160223024243_CBsLX.jpeg
正在下载第7张图片,图片地址:http://img5.duitang.com/uploads/item/201407/10/20140710151734_jKZHG.jpeg
正在下载第8张图片,图片地址:http://b-ssl.duitang.com/uploads/item/201609/25/20160925132032_PXVC5.jpeg
正在下载第9张图片,图片地址:http://pic175.nipic.com/file/20180728/23771846_150419899088_2.jpg
正在下载第10张图片,图片地址:http://img3.duitang.com/uploads/item/201401/15/20140115205512_mCnti.jpeg
正在下载第11张图片,图片地址:http://cdnq.duitang.com/uploads/item/201504/25/20150425H4124_ityxj.jpeg
正在下载第12张图片,图片地址:http://b-ssl.duitang.com/uploads/item/201408/10/20140810154436_33H8S.jpeg
正在下载第13张图片,图片地址:http://img5q.duitang.com/uploads/item/201202/18/20120218010426_ZtBMQ.thumb.700_0.jpg
正在下载第14张图片,图片地址:http://b-ssl.duitang.com/uploads/item/201507/16/20150716095301_HntXk.jpeg
正在下载第15张图片,图片地址:http://b-ssl.duitang.com/uploads/item/201705/22/20170522140759_ehTFA.jpeg
正在下载第16张图片,图片地址:http://img4.duitang.com/uploads/item/201207/20/20120720200540_TXnni.thumb.700_0.jpeg
正在下载第17张图片,图片地址:http://img3.duitang.com/uploads/item/201507/05/20150705105040_wHiyJ.thumb.700_0.jpeg
正在下载第18张图片,图片地址:http://cdn.duitang.com/uploads/item/201406/12/20140612224531_yNfxL.thumb.700_0.jpeg
正在下载第19张图片,图片地址:http://img3.duitang.com/uploads/item/201501/12/20150112194522_xrXEJ.thumb.700_0.jpeg
正在下载第20张图片,图片地址:http://b-ssl.duitang.com/uploads/item/201601/28/20160128014923_uHYVT.thumb.700_0.jpeg
正在下载第21张图片,图片地址:http://b-ssl.duitang.com/uploads/item/201401/15/20140115210457_EBjU5.thumb.700_0.jpeg
正在下载第22张图片,图片地址:http://img4q.duitang.com/uploads/item/201505/16/20150516091202_CjVN3.thumb.700_0.jpeg
正在下载第23张图片,图片地址:http://n.sinaimg.cn/translate/433/w1600h2833/20190306/_-nz-htwhfzs5914758.jpg
正在下载第24张图片,图片地址:http://img01.tooopen.com/Downs/images/2011/4/26/sy_20110426110324243945.jpg
正在下载第25张图片,图片地址:http://b-ssl.duitang.com/uploads/item/201610/01/20161001094348_rZnfm.jpeg
正在下载第26张图片,图片地址:http://y3.ifengimg.com/a/2015_35/24da1d95f57a6de.jpg
正在下载第27张图片,图片地址:http://www.mianfeiwendang.com/pic/703ae21a26eb0ef25af2743c/1-810-jpg_6-1080-0-0-1080.jpg
正在下载第28张图片,图片地址:http://bbsfiles.vivo.com.cn/vivobbs/attachment/forum/201308/28/171928ylqfnfrfnzzy5x5u.jpg
正在下载第29张图片,图片地址:http://img5.duitang.com/uploads/item/201112/17/20111217183751_xTsBs.jpg
正在下载第30张图片,图片地址:http://img5.duitang.com/uploads/item/201409/16/20140916120854_duGW4.thumb.700_0.jpeg
imgDownLoad(第二个图片下载的代码)
代码如下:
"""
图片下载器
"""
# -*- coding:utf-8 -*-
import re
import requests
import os
def downloadPic(html, keyword):
"""
:param html: 页面的源代码
:param keyword: 搜索的关键字
:return:
"""
# (.*?)代表任意多个字符
# ()代表分组, 值返回符合条件的字符串中括号里面的内容;
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
count = 0
print('找到关键词:' + keyword + '的图片,现在开始下载图片...')
# each 是每个图片的url地址
for each in pic_url:
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 '
'Mobile Safari/537.36'}
# 获取指定图片的相应对象;
response = requests.get(each, timeout=10, headers=headers)
except requests.exceptions.ConnectionError:
print('【错误】当前图片无法下载')
continue
except Exception as e:
print('【错误】当前图片无法下载')
print(e)
continue
else:
# print(response.status_code)
if response.status_code != 200:
print("访问失败: ", response.status_code)
continue
# ******** 存储图片到本地*******************************
if not os.path.exists(imgDir):
print("正在创建目录 ", imgDir)
os.makedirs(imgDir)
posix = each.split('.')[-1]
if posix not in ['png', 'jpg', 'gif', 'jpeg']:
break
print('正在下载第' + str(count + 1) + '张图片,图片地址:' + str(each))
name = keyword + '_' + str(count) + '.' + posix
filename = os.path.join(imgDir, name)
count += 1
with open(filename, 'wb') as f:
# response.content: 返回的是二进制文本信息
# response.text:返回的字符串文本信息
f.write(response.content)
if __name__ == '__main__':
imgDir = 'pictures'
word = input("Input key word: ")
url = 'http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=' + word
try:
response = requests.get(url)
except Exception as e:
print(e)
content = ''
else:
content = response.text
downloadPic(content, word)
(02)urllib模块理解
运行代码如下所示:
from urllib import request
from urllib import error
from urllib import parse
#paese:解析
try:
url = 'http://www.baidu.com:80'
obj = parse.urlparse(url)
response = request.urlopen(url)
print("访问的网站是:",obj.netloc)
except error.HTTPError as e:
print(e.code,e.reason,e.headers)
except error.URLError as e:
print(e.reason)
else:
bytes_content = response.read()
print(type(bytes_content))
str_content = bytes_content.decode('utf-8')
print(type(str_content))
结果显示如下:
/home/kiosk/anaconda3/bin/python3.7 /home/kiosk/PycharmProjects/day11/day25python/02_urllib模块理解.py
访问的网站是: www.baidu.com:80
<class 'bytes'>
<class 'str'>
Process finished with exit code 0
(03)urllib反爬虫第一步:模拟浏览器
结果展示如下:
/home/kiosk/anaconda3/bin/python3.7 /home/kiosk/PycharmProjects/day11/day25python/03_urllib反爬虫第一步_模拟浏览器.py
访问的网站是: www.baidu.com:80
<class 'bytes'>
<class 'str'>
请求头部信息: {'User-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) '}
响应头部信息: Cache-Control: no-cache
Content-Type: text/html;charset=utf-8
Coremonitorno: 0
Date: Thu, 08 Aug 2019 03:11:00 GMT
P3p: CP=" OTI DSP COR IVA OUR IND COM "
Server: apache
Set-Cookie: BAIDUID=53C0433E48A6150B9750B336F973BC4C:FG=1; max-age=31536000; expires=Fri, 07-Aug-20 03:11:00 GMT; domain=.baidu.com; path=/; version=1; comment=bd
Set-Cookie: H_WISE_SIDS=133994_126126_114550_134698_132060_131888_133720_133675_120173_132909_133045_131246_132439_130763_132378_131518_118889_118867_118855_118830_118798_107316_132781_134392_133352_132553_129654_134433_132250_124634_128967_133472_133838_133847_132552_134461_134319_134541_134214_131423_133780_134601_134488_134383_133537_110085_134152_127969_127316_128196_134150_133931_134350; path=/; expires=Fri, 07-Aug-20 03:11:00 GMT; domain=.baidu.com
Set-Cookie: bd_traffictrace=081111; expires=Thu, 08-Jan-1970 00:00:00 GMT
Set-Cookie: rsv_i=e329DLLI1rHHGz5qWzkJ3Y475TrjFFjcIf1PHovyuLQ7XcB6r0QUmD9rDMYwqFHBkWXvNt96QfwGYdEsYWve1Jds2sIXRC0; path=/; domain=.baidu.com
Set-Cookie: BDSVRTM=107; path=/
Set-Cookie: eqid=deleted; path=/; domain=.baidu.com; expires=Thu, 01 Jan 1970 00:00:00 GMT
Set-Cookie: __bsi=11410664630223327108_00_30_N_N_109_0303_cca8_Y; max-age=3600; domain=m.baidu.com; path=/
Strict-Transport-Security: max-age=172800
Tracecode: 06608918470713964042080811
Tracecode: 06608193450533894922080811
Traceid: 1565233860257241191411410664630223327108
Vary: Accept-Encoding
Vary: Accept-Encoding
Vary: Accept-Encoding
Connection: close
Transfer-Encoding: chunked
响应的状态码: 200
Process finished with exit code 0
运行代码如下所示:
"""
浏览器的模拟
应用场景:有些网页为了防止别人恶意采集其信息所以进行了一些反爬虫的设置,而我们又想进行爬取。
解决方法:设置一些Headers信息(User-Agent),模拟成浏览器去访问这些网站。
"""
from urllib import request
from urllib import error
from urllib import parse
try:
url = 'http://www.baidu.com:80'
obj = parse.urlparse(url)
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) '}
# 实例化请求对象, 修改请求的头部信息;
requestObj = request.Request(url, headers=headers)
# urlopen方法可以打开一个url地址, 也可以打开一个请求对象(一般为了修改请求头部)
response = request.urlopen(requestObj)
print("访问的网站是: ", obj.netloc)
except error.HTTPError as e:
print(e.code, e.reason, e.headers)
except error.URLError as e:
print(e.reason)
else:
bytes_content = response.read()
print(type(bytes_content))
str_content = bytes_content.decode('utf-8')
print(type(str_content))
# 请求对象拥有的方法:
# 相应对象拥有的方法:
# print(dir(requestObj))
# print(dir(response))
print("请求头部信息:", requestObj.headers)
print("响应头部信息: ", response.headers)
print("响应的状态码: ", response.code)(04)urllib反爬虫第二步:设置代理
运行代码如下所示:
"""
代理服务器的设置
应用场景:使用同一个IP去爬取同一个网站上的网页,久了之后会被该网站服务器屏蔽。
解决方法:使用代理服务器。 (使用代理服务器去爬取某个网站的内容的时候,在对方的网站上,显示的不是我们真实的IP地址,而是代理服务器的IP地址)
如何获取免费代理?
pass
"""
from urllib.request import ProxyHandler,build_opener,urlopen,install_opener
import random
proxyes = [
{'HTTPS':'124.47.7.38:80'},
{'HTTP':'123.139.56.238:9999'},
{'HTTP':'113.140.1.82:53281'},
]
url = 'http://httpbin.org/get'
#
proxy_support= ProxyHandler(random.choice(proxyes))
#
opener = build_opener(proxy_support)
install_opener(opener)
#3
response = opener.open(url)
print('>>>>>>>>>>>>>>>.')
content = response.read()
print(len(content))
print(content)
结果展示如下:
/home/kiosk/anaconda3/bin/python3.7 /home/kiosk/PycharmProjects/day11/day25python/04_urllib反爬虫第二步_设置代理.py
>>>>>>>>>>>>>>>.
224
b'{\n "args": {}, \n "headers": {\n "Accept-Encoding": "identity", \n "Host": "httpbin.org", \n "User-Agent": "Python-urllib/3.7"\n }, \n "origin": "117.35.134.154, 117.35.134.154", \n "url": "https://httpbin.org/get"\n}\n'
Process finished with exit code 0
(5)requests反爬虫第二步:设置代理
运行代码如下所示:
import requests
import random
proxies = [
{'http':'123.139.56.238:9999'},
{'http':'158.140.182.175:8080'},
]
headers = {
'User-Agent':'Mozilla/5.0(Linux;U;Android2.3.7;en-us;NexusOneBuild/FRF91)'
}
url = 'http://httpbin.org/get'
proxy = random.choice(proxies)
print(proxy)
response = requests.get(url,headers=headers,proxies=random.choice(proxies))
print(response.text)
print(response.headers)结果展示如下:
/home/kiosk/anaconda3/bin/python3.7 /home/kiosk/PycharmProjects/day11/day25python/05_repuest反爬虫第二步_设置代理.py
{'http': '123.139.56.238:9999'}
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0(Linux;U;Android2.3.7;en-us;NexusOneBuild/FRF91)",
"X-Proxy-Id": "1148370680"
},
"origin": "1.80.80.15, 123.139.56.238, 1.80.80.15",
"url": "https://httpbin.org/get"
}
{'Access-Control-Allow-Credentials': 'true', 'Access-Control-Allow-Origin': '*', 'Content-Type': 'application/json', 'Date': 'Thu, 08 Aug 2019 03:29:36 GMT', 'Referrer-Policy': 'no-referrer-when-downgrade', 'Server': 'nginx', 'X-Content-Type-Options': 'nosniff', 'X-Frame-Options': 'DENY', 'X-XSS-Protection': '1; mode=block', 'Content-Length': '334'}
Process finished with exit code 0
(6)检测代理IP是否可用
"""
测试代理IP是否可用?
"""
# -*- coding: utf-8 -*-
import telnetlib
print('------------------------connect---------------------------')
ip = '123.139.56.238'
try:
tn = telnetlib.Telnet(ip, port='9999', timeout=10)
except Exception as e:
print(e)
print('error')
else:
print('ok')
print('-------------------------end----------------------------')(7)requests请求方法详解
代码展示如下:
# GET
import requests
# url = 'http://www.baidu.com'
# response = requests.get(url)
# print(response.text) # 文本
# print(response.content)# 二进制
# # print(response.json()) # 返回的是json字符串, 转成python可以识别的字典;
# # POST
# url = 'http://httpbin.org/post' # 专门用来测试post方法的网站
# response = requests.post(url, data={'name':'westos', 'age':10})
# print(response.text)
# # PUT
# url = 'http://httpbin.org/put' # 专门用来测试post方法的网站
# response = requests.put(url, data={'name':'westos', 'age':10})
# response = requests.put(url, data={'name':'zhihu'})
# print(response.text)
# # DELETE
# url = 'http://httpbin.org/delete'
#
# response = requests.delete(url, data={'name':'westos', 'age':10})
# print(response.text)
# url解析
# url = 'https://movie.douban.com/subject/26794435/photos?type=R&start=90&sortby=like&size=a&subtype=a'
url = 'https://movie.douban.com/subject/26794435/photos'
params = {
'
'start': 90,
'sortby': 'like',
'subtype': 'a'
}
response = requests.get(url, params=params)
with open('douban.html', 'wb') as f:
f.write(response.content)(08)requests模块搜索小案例
运行代码如下:
import requests
def searchBaidu():
keyword = input("请输入搜索的关键字:")
baiduurl = 'http://www.baidu.com/s'
params = {
'wd':keyword
}
headers = {
'User-Agent':'Mozilla/5.0(Linux;U;Android2.3.7;en-us;NexusOneBuild/FRF91)'
}
try:
response = requests.get(baiduurl,params=params,headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
except Exception as e:
print("[-]爬取失败:",e)
else:
print('[+]'+ response.url+"爬取成功....")
print(len(response.text))
if __name__ == '__main__':
searchBaidu()
代码结果展示如下:
/home/kiosk/anaconda3/bin/python3.7 /home/kiosk/PycharmProjects/day11/day25python/08_requests模块搜索小案例.py
请输入搜索的关键字:篮球
[+]http://www.baidu.com/s?wd=%E7%AF%AE%E7%90%83爬取成功....
24259
Process finished with exit code 0
(09)bs4模块入门
"""
# 0. 概括
- 获取页面: urllib, requests
- 解析页面信息: 正则表达式, BeautifulSoup4(BS4)
# 1. BS4简介
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个
工具箱,通过解析文档为tiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。
你不需要考虑编码方式,除非文档没有指定一个编一下原始编码方式就可以了。
# 2. BS4的4种对象
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,
每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment .
## 2-1. BeautifulSoup对象
## 2-2. Tag对象
Tag就是html中的一个标签,用BeautifulSoup就能解析出来Tag的具体内容,
具体的格式为soup.name,其中name是html下的标签。
"""
from bs4 import BeautifulSoup
html = """
<html>
<head><title>story12345</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><span>westos</span><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister1" id="link2">python</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Java</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# 1. 实例化BeautifulSoup对象
# https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/#id7
soup = BeautifulSoup(html, 'lxml') # 使用lxml解析器进行解析,速度快。
print(soup)
print(soup.prettify()) # 按照指定的缩进格式补齐并显示html;结果展示如下:
/home/kiosk/anaconda3/bin/python3.7 /home/kiosk/PycharmProjects/day11/day25python/09_bs4模块入门.py
<html>
<head><title>story12345</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><span>westos</span><!-- Elsie --></a>,
<a class="sister1" href="http://example.com/lacie" id="link2">python</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Java</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
<html>
<head>
<title>
story12345
</title>
</head>
<body>
<p class="title" name="dromouse">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
<span>
westos
</span>
<!-- Elsie -->
</a>
,
<a class="sister1" href="http://example.com/lacie" id="link2">
python
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Java
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>
Process finished with exit code 0
根据标签名获取信息,代码如下:
print(soup.title)
print("网页的标题: ", soup.title.text) # 获取指定标签里面的文本信息
print(soup.title.name)
结果展示如下:
/home/kiosk/anaconda3/bin/python3.7 /home/kiosk/PycharmProjects/day11/day25python/09_bs4模块入门.py
<title>story12345</title>
网页的标题: story12345
title
Process finished with exit code 0
获取的标签包含多个时, 默认返回第一个;
代码如下:
print(soup.a)结果展示如下;
/home/kiosk/anaconda3/bin/python3.7 /home/kiosk/PycharmProjects/day11/day25python/09_bs4模块入门.py
<a class="sister" href="http://example.com/elsie" id="link1"><span>westos</span><!-- Elsie --></a>
Process finished with exit code 0
获取指定标签的属性(3种),代码如下:
print(soup.a['href'])
print(soup.a['class'])
print(soup.a['id'])
print(soup.a.get('id'))结果展示如下:
/home/kiosk/anaconda3/bin/python3.7 /home/kiosk/PycharmProjects/day11/day25python/09_bs4模块入门.py
http://example.com/elsie
['sister']
link1
link1
Process finished with exit code 0
attrs获取a标签的所有属性,代码如下:
print(soup.a.attrs['href'])
修改标签里面的属性信息,代码如下:
print(soup.a['href'])
soup.a['href'] = 'http://www.baidu.com'
print(soup.a)结果展示如下:
/home/kiosk/anaconda3/bin/python3.7 /home/kiosk/PycharmProjects/day11/day25python/09_bs4模块入门.py
http://example.com/elsie
<a class="sister" href="http://www.baidu.com" id="link1"><span>westos</span><!-- Elsie --></a>
Process finished with exit code 0
找到符合条件的所有标签,代码如下:
tagObj = soup.find_all('a')
print(tagObj)
print(len(tagObj))结果展示如下:
/home/kiosk/anaconda3/bin/python3.7 /home/kiosk/PycharmProjects/day11/day25python/09_bs4模块入门.py
[<a class="sister" href="http://example.com/elsie" id="link1"><span>westos</span><!-- Elsie --></a>, <a class="sister1" href="http://example.com/lacie" id="link2">python</a>, <a class="sister" href="http://example.com/tillie" id="link3">Java</a>]
3
Process finished with exit code 0

















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









