







 本文介绍了一种使用Python爬取百度图片的方法,详细分析了百度图片的请求规则,并提供了完整的代码实现,包括处理反爬措施、异常捕获及图片下载。
本文介绍了一种使用Python爬取百度图片的方法,详细分析了百度图片的请求规则,并提供了完整的代码实现,包括处理反爬措施、异常捕获及图片下载。
由于做项目需要大量图片,应我同学的要求,帮他爬取大量百度图片
当做练习,这里写出来记录一下
我们首先分析一下百度图片的页面和获取规则
随便输入一个关键字,我们下滑图片页面,同时检查,就可以发现,它是通过Ajax请求一直获取图片
之前正好也做了爬取微博的例子,想来是差不多,于是我们分析一下Ajax请求链接
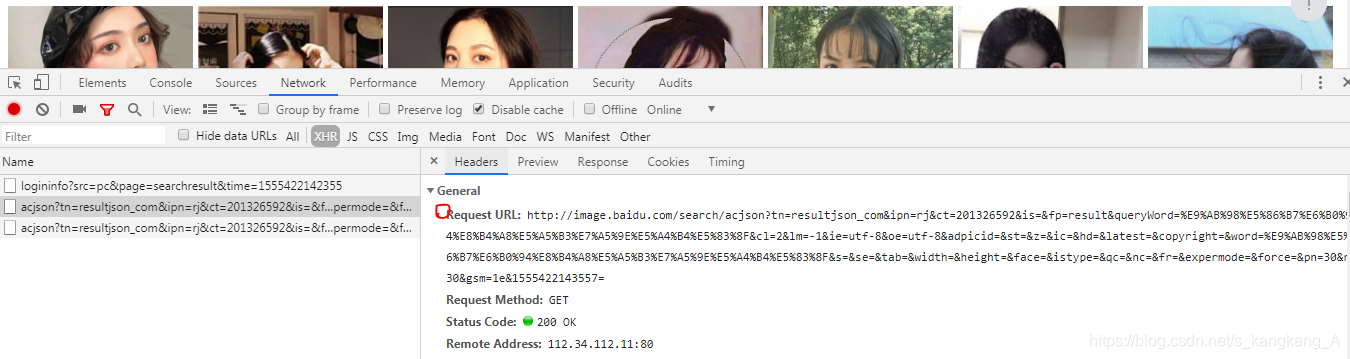
我们看到请求URL,多分析几条就能发现,它几乎是不变的,而变化的几条分别是,pn,gsm以及最后一串数字
pn很明显,一页是30张图片,所以pn是从30开始的,值为30的等差数列,也就是说后面链接的pn分别是30,60.。。。。
但是,gsm和最后一串数字是无迹可寻的,那么不要这两项我们能请求到图片吗 ?或者说我们能请求到下面这个response吗

我们试试。下面是我们没有后面两项参数获取的页面
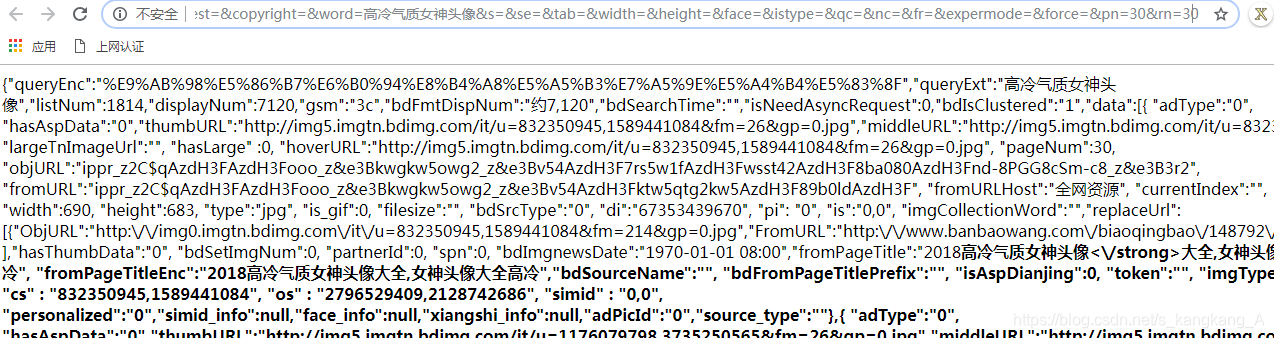
我们复制一下,去到json.cn
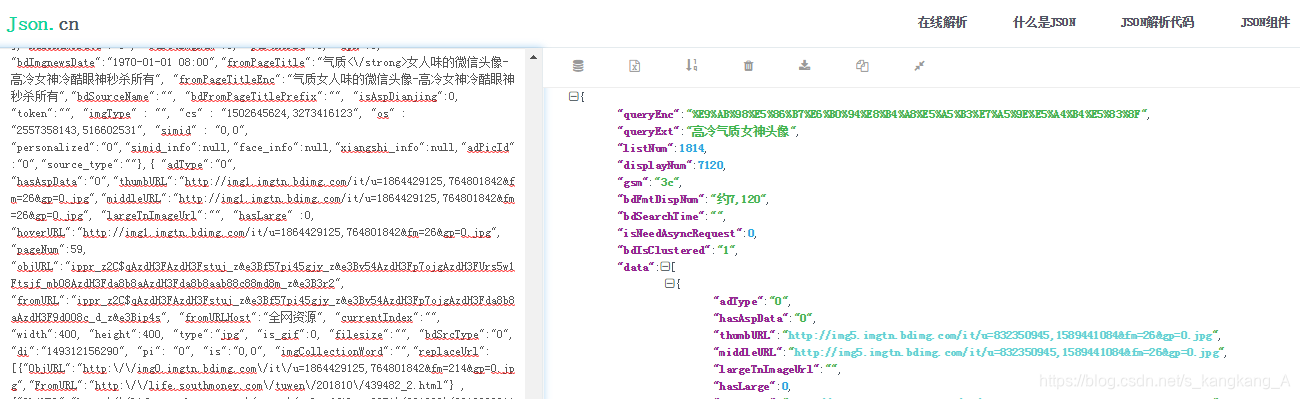
所以是可以的,那我们上代码
from urllib import request
import requests
import os
j = 23
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML,'
' like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'Referer' : 'https://image.baidu.com/search/index?ct=201326592&cl=2&st=-1&lm=-1&nc=1&ie=utf'
'-8&tn=baiduimage&ipn=r&rps=1&pv=&fm=rs3&word=2017%E9%AB%98%E5%86%B7%E6%B0%94%E8%B4'
'%A8%E5%A5%B3%E7%A5%9E%E5%A4%B4%E5%83%8F&oriquery'
'=%E7%BE%8E%E5%A5%B3%E5%A4%B4%E5%83%8F&ofr=%E7%BE%8E%E5%A5%B3%E5%A4%B4%E5%83%8F&h'
's=2&sensitive=0',
'X-Requested-With' : 'XMLHttpRequest',
'Pragma' : 'no-cache',
'Host' : 'image.baidu.com',
'Cookie' : 'BDqhfp=2017%E9%AB%98%E5%86%B7%E6%B0%94%E8%B4%A8%E5%A5%B3%E7%A5%9E%E5%A4%B4%E5%83%8F%26%26NaN-1undefin'
'ed-1undefined%26%260%26%261; BAIDUID=108DD91853020283765F341A94F1F868:FG=1; BIDUPSID=108DD91853020283765'
'F341A94F1F868; '
'PSTM=1551104040; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=1458_28777_21110_18559_28769_28720'
'_28557_28838_28585_28604; delPer=0; PSINO=1; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; userFrom=ala; BDRCVFR['
'-pGxjrCMryR]=mk3SLVN4HKm; indexPageSugList=%5B%22%E7%BE%8E%E5%A5%B3%22%5D; cleanHistoryStatus=0'
}
def parse_page(url):
global j
try:
resp = requests.get(url,headers)
if resp.status_code == 200:
content = resp.json()
# print(content)
except requests.ConnectionError as e:
print("Error" , e.args)
items = content.get('data')[0:30]
for item in items:
j += 1
# print(item)
url = item.get('thumbURL')
p_name = str(j) + os.path.splitext(url)[1]
request.urlretrieve(url , 'beautifulgirl/' + p_name)
print(p_name + "下载完成")
def main():
i = 0
for x in range(0,30):
i += 30
url = ' https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=20132' \
'6592&is=&fp=result&queryWord=2017%E9%AB%98%E5%86%B7%E6%B0%94%E8%B4%A8%E5%A5%B3%E7%A5' \
'%9E%E5%A4%B4%E5%83%8F&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1' \
'&z=&ic=&hd=&latest=©right=&word=2017%E9%AB%98%E5%86%B7%E6%B0%94%E8%B4%' \
'A8%E5%A5%B3%E7%A5%9E%E5%A4%B4%E5%83%8F&s=&se=&tab=&width=&height=&face=&istype' \
'=&qc=&nc=1&fr=&expermode=&force=&pn=i&rn=30'.format(i)
parse_page(url)
if __name__ == '__main__':
main()
那么这里抓取的是前900张,因为我同学不需要那么多,所以我只爬了900张。下面讲一下代码
我们定义了一个全局变量j=24,因为客户要求命名为数字,且从24开始,引用全局变量需要在方法里global。
因为怕反爬,所以定制头部信息比较长。
我们还做了一个抛出异常,如果下载失败,我们就可以看见
我们做了一个切片操作,这是因为,30是空的,从0开始正好30张图
![]()
我们用了os模块的方法去获取图片的后缀,是.png还是.jpg我们命名但不改变图片属性

关于改善:
如果你想要的爬取所有图片,我们很明显可以看见

这可以帮你估计页数。
如果你需要自己输入关键字去搜索,那么把输入的字符编码一下,传入url即可
如果你觉得下载慢,可以参考我前面的生产者消费者线程爬取,过高的频率访问,可能会被封ip哦。
最后。
我在第一次爬取时,发现从第二个Ajax请求,转化成json提取URL下载时是没有问题的,但在第一个Ajax请求转化成json提取数据时报了错,出现了无法转化的问题,因为时间太晚就没修改,从第二个Ajax爬取就交给我同学了,本来想修改一下,但今天测试忽然又可以了,但这并不能改变我优化代码的决心。
如果你对第一个Ajax请求进行如下操作
resp = requests.get(url,headers)
content = resp.json()
出现了如下报错
TypeError: 'str' object is not callable
或者,你爬取的json是不规范的,解释器无法解析而报错的。
那么,你要知道,正则表达式是无所不能的,以下仅参考,这里仅对第一页进行了url提取:
import requests
import re
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML,'
' like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'Referer' : 'https://image.baidu.com/search/index?ct=201326592&cl=2&st=-1&lm=-1&nc=1&ie=utf'
'-8&tn=baiduimage&ipn=r&rps=1&pv=&fm=rs3&word=2017%E9%AB%98%E5%86%B7%E6%B0%94%E8%B4'
'%A8%E5%A5%B3%E7%A5%9E%E5%A4%B4%E5%83%8F&oriquery'
'=%E7%BE%8E%E5%A5%B3%E5%A4%B4%E5%83%8F&ofr=%E7%BE%8E%E5%A5%B3%E5%A4%B4%E5%83%8F&h'
's=2&sensitive=0',
'X-Requested-With' : 'XMLHttpRequest',
'Pragma' : 'no-cache',
'Host' : 'image.baidu.com',
'Cookie' : 'BDqhfp=2017%E9%AB%98%E5%86%B7%E6%B0%94%E8%B4%A8%E5%A5%B3%E7%A5%9E%E5%A4%B4%E5%83%8F%26%26NaN-1undefin'
'ed-1undefined%26%260%26%261; BAIDUID=108DD91853020283765F341A94F1F868:FG=1; BIDUPSID=108DD91853020283765'
'F341A94F1F868; '
'PSTM=1551104040; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=1458_28777_21110_18559_28769_28720'
'_28557_28838_28585_28604; delPer=0; PSINO=1; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; userFrom=ala; BDRCVFR['
'-pGxjrCMryR]=mk3SLVN4HKm; indexPageSugList=%5B%22%E7%BE%8E%E5%A5%B3%22%5D; cleanHistoryStatus=0'
}
def parse_page(url):
try:
resp = requests.get(url,headers)
if resp.status_code == 200:
content = resp.text
print(content)
except requests.ConnectionError as e:
print("Error" , e.args)
urls = re.findall(r'"thumbURL":"(.*?)"',content,re.S)
for u in urls:
print(u)
def main():
url = ' https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=20132' \
'6592&is=&fp=result&queryWord=2017%E9%AB%98%E5%86%B7%E6%B0%94%E8%B4%A8%E5%A5%B3%E7%A5' \
'%9E%E5%A4%B4%E5%83%8F&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1' \
'&z=&ic=&hd=&latest=©right=&word=2017%E9%AB%98%E5%86%B7%E6%B0%94%E8%B4%' \
'A8%E5%A5%B3%E7%A5%9E%E5%A4%B4%E5%83%8F&s=&se=&tab=&width=&height=&face=&istype' \
'=&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30'
parse_page(url)
if __name__ == '__main__':
main()
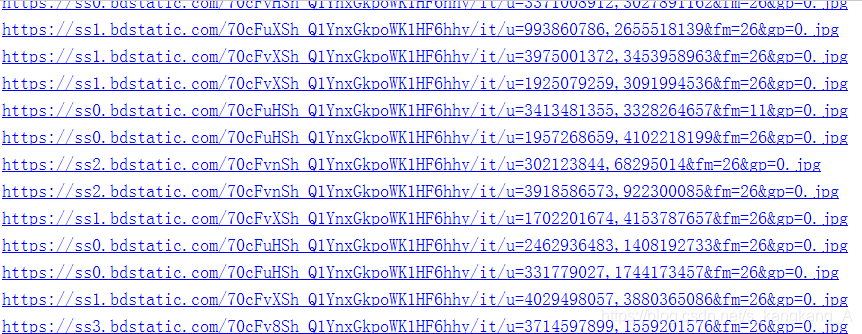
用url下载就可以啦。
——————————————————更新2019-4-19——————————————————————————
更新了代码,让大家可以自己选择图片和存储路径,而且爬取所有图片,所有。。。。。。
from urllib import request
import requests
from urllib import parse
import os
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0'
'.3440.75 Safari/537.36',
'Referer' : 'https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gb18030&word=%B'
'6%AF%C2%FE%CD%BC%C6%AC&fr=ala&ala=1&alatpl=adress&pos=0&hs=2&xthttps=111111',
'Host' : 'image.baidu.com'
}
j = 0
def parse_page(url,save_path):
global j
try:
resp = requests.get(url,headers)
text = resp.json()
except requests.ConnectionErrorn as e:
print("Error", e.args)
items = text.get("data")[0:30]
for item in items:
j += 1
url = item.get("thumbURL")
p_name = str(j) + os.path.splitext(url)[1]
request.urlretrieve(url, save_path + p_name)
print(p_name + "下载完成")
def main():
kw = input("请输入关键字:")
save_path = input(r'请输入路径确保正确且存在,如:"E:\beautifulgirl\"')
data1 = {
'queryWord': kw
}
data1 = parse.urlencode(data1)
data2 = {
'word': kw
}
data2 = parse.urlencode(data2)
f_url = "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&f" \
"p=result&{}&cl=2&lm=-1&ie=utf-8&oe=utf-8" \
"&adpicid=&st=&z=&ic=&hd=&latest=©right=&{}&" \
"s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&fr=&expermode=&force=&pn=30&rn=30".format(data1, data2)
try:
resp = requests.get(url=f_url , headers=headers)
text = resp.json()
# print(text)
except requests.ConnectionErrorn as e:
print("Error" , e.args)
all_num = text.get("displayNum")
# print(all_num)
Max_size = int(all_num/30)
i = 0
for x in range(0,Max_size):
i += 30
url = "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&f" \
"p=result&{}&cl=2&lm=-1&ie=utf-8&oe=utf-8" \
"&adpicid=&st=&z=&ic=&hd=&latest=©right=&{}&" \
"s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&fr=&expermode=&force=&pn={}&rn=30".format(data1,data2,i)
# print(url)
parse_page(url,save_path)
if __name__ == '__main__':
main()

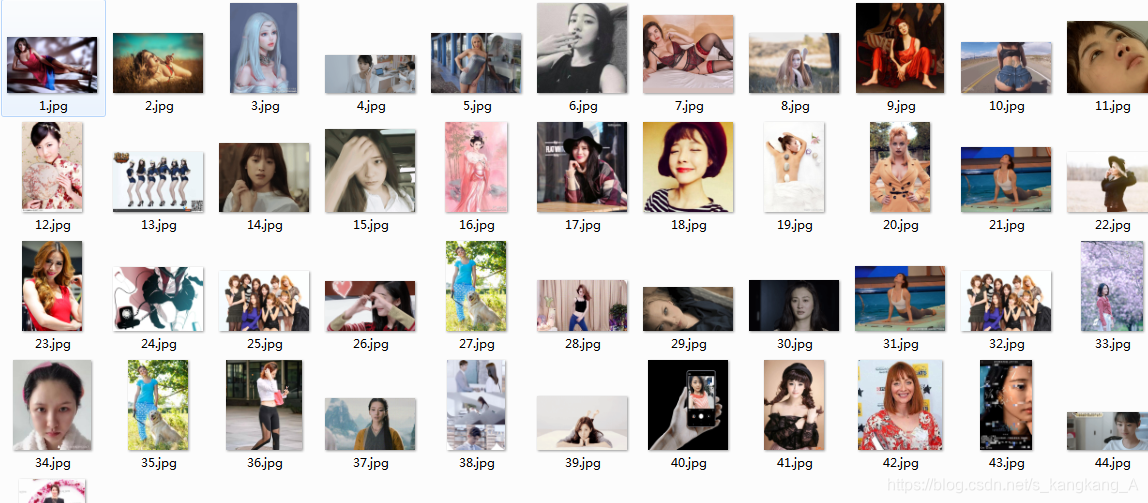
就这样,不在详述。

















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









