







 本文介绍了一种新型对话系统,通过监督学习模仿人类并利用bot-play进行目标导向对话优化。研究者创建了首个大规模推荐对话数据集,通过两阶段训练提升策略,最终模型在与人交互中表现更优。
本文介绍了一种新型对话系统,通过监督学习模仿人类并利用bot-play进行目标导向对话优化。研究者创建了首个大规模推荐对话数据集,通过两阶段训练提升策略,最终模型在与人交互中表现更优。
题目
Recommendation as a Communication Game:
Self-Supervised Bot-Play for Goal-oriented Dialogue
简介
本文利用数据集开发了一个端到端的对话系统,可以同时进行对话和推荐。模型首先被训练来模仿人类玩家的行为,而不考虑任务目标本身(监督训练)。然后,本文在两个配对的预训练模型(bot-play)之间模拟bot-bot对话,来微调本文的模型,以实现对话目标。最后的实验表明,与没有经过bot-play训练的模型相比,经过bot-play微调的模型学习到了改进的对话策略,在与人类对话时更经常地达到对话目标,并且与人类行为一致
why
传统的推荐系统产生静态的而不是交互式的推荐,这种系统没法有效地处理用户的特定请求、临时请求,从而获取用户暂时的兴趣偏好;而且如果用户的喜好未知,则可能遭受冷启动问题
what
本文收集了一个基于真实用户对电影偏好的目标驱动对话语料库,并展示了使用该语料库训练的模型可以学习成功的推荐对话策略。训练分两个阶段进行:第一,监督阶段,训练模型模仿人类在任务中的行为;第二,改进模型的目标导向策略的bot-play阶段
(1)提供了第一个大规模目标驱动的推荐对话数据集,该数据集基于真实世界的知识库,具有特定的目标和奖励信号
(2)提出了一个两阶段的推荐策略学习框架,并通过实证验证了它能带来更好的推荐会话策略
how
super-vised multi-aspect learning and bot-play
-
super-vised multi-aspect
具体对应于以下三个子任务:
(1)生成对话话语,想要用与正常人对话方式相匹配的方式与搜索者说话
(2)基于对话历史和电影描述表示预测正确的电影
(3)决定是推荐还是继续进行对话
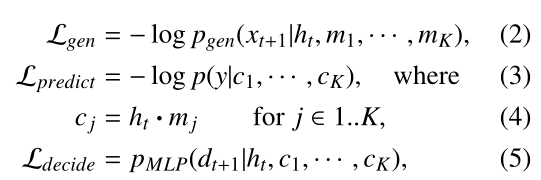
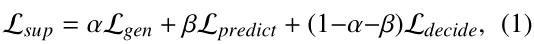
-
Bot-Play
这一环节展示了如何构建一个奖励函数来执行环境中两个bots之间的Bot-Play,目的是开发一个更好的专家对话agent来进行推荐首先分别预先训练专家和搜索者模型:
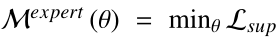
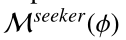
然后,让他们互相聊天,并通过最大化游戏中的奖励来微调专家模型
Result
- Evaluation of Supervised Models
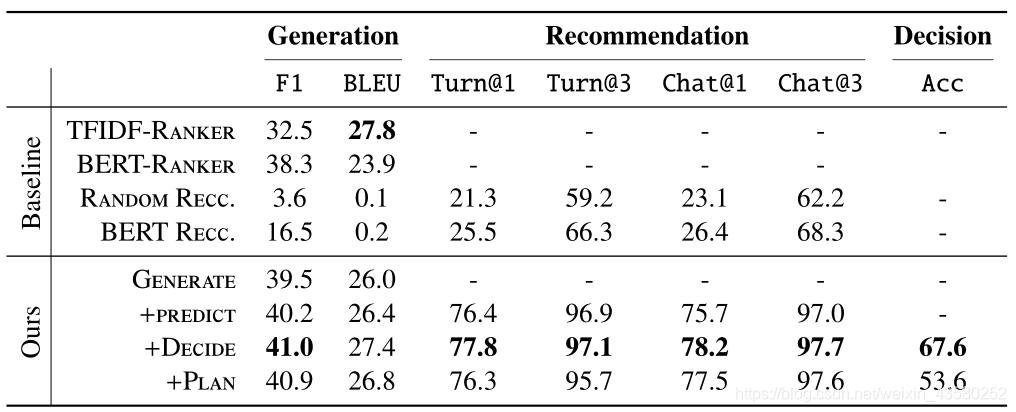
- Evaluation on Dialogue Games
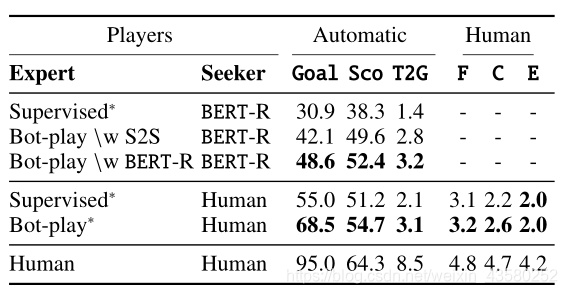
Conclusion
总之,本文将推荐作为专家和搜索者之间的goal-oriented game,并通过学习模仿大量人与人的对话,以及通过训练agent之间的bot-play,以监督的方式为两个训练代理提供框架。实验表明,这两个阶段的结合效果更好


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









