







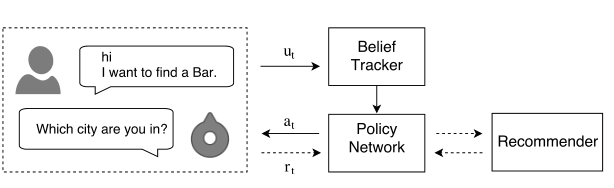
 本文提出了一种结合推荐系统和对话管理的深度强化学习框架,用于构建个性化对话推荐代理。该代理通过用户历史评分和会话查询来生成推荐,同时在对话中收集用户偏好。系统包括NLU模块、DM模块和NLG模块,其中NLU模块使用深度信念跟踪器分析用户意图,DM模块采用策略网络决定何时询问或推荐,NLG模块生成用户响应。实验表明该框架能有效提升推荐的准确性和用户体验。
本文提出了一种结合推荐系统和对话管理的深度强化学习框架,用于构建个性化对话推荐代理。该代理通过用户历史评分和会话查询来生成推荐,同时在对话中收集用户偏好。系统包括NLU模块、DM模块和NLG模块,其中NLU模块使用深度信念跟踪器分析用户意图,DM模块采用策略网络决定何时询问或推荐,NLG模块生成用户响应。实验表明该框架能有效提升推荐的准确性和用户体验。
题目
Conversational Recommender System
简介
在这篇文章中,作者提出了一个将推荐和对话合并的统一的深度强化学习框架(framework)从而建立个性化的对话推荐代理,在进行评分预测和生成推荐时,该模型使用用户过去的评分和当前会话中收集到的用户查询。这样的对话系统通常试图通过提问来收集用户偏好,一旦收集到足够多的用户偏好,它就会向用户做出个性化的推荐。我们进行了模拟实验和真实的在线用户研究,以证明该框架的有效性
why
个性化的对话系统一般有很大的商业潜力,然而这方面的研究非常有限,现有的解决方案要么基于单轮自组织搜索引擎,要么基于传统的多轮对话系统。它们通常只利用当前会话中的用户输入,而忽略用户的长期偏好;另一方面,众所周知,基于推荐系统可以大大提高销售转化率,该系统基于过去的购买行为学习用户偏好,并优化面向业务的指标,如转化率或预期收入
what
本文的系统有三个主要部分
首先,自然语言理解(NLU)模块,用于分析每个用户话语,跟踪用户的对话历史,并不断更新用户的意图。这个NLU模块的重点是提取item特定的元数据
第二,本文提出了一个对话管理(DM)模块,它决定在给定当前状态下采取哪种操作。该数据挖掘模块具有专门为此任务定义的操作空间
第三个组件是自然语言生成模块,用于生成对用户的响应。该框架使我们能够构建一个对话式搜索和推荐系统,该系统可以决定何时以及如何从用户那里收集信息,并基于用户过去的购买历史和当前会话中的上下文信息做出推荐
对于NLU模块,本文训练深度信念跟踪器来基于上下文分析用户的当前话语,并从用户话语中提取目标item的方面值。它的输出表示为一个用户查询,用于更新当前的用户意图,它是关于目标的一组facet-value pairs。对话管理器和推荐系统都将使用用户查询
对于数据挖掘模块,本文训练了一个深度策略网络,在给定当前用户查询和推荐系统学习到的长期用户偏好的情况下,该网络决定在每个回合采取哪个动作,该动作可以是向用户询问关于特定方面的信息或者推荐产品列表,深度策略网络选择在整个对话会话中使预期回报最大化的操作(当收集的用户查询足以识别用户的信息需求时,最佳动作通常是为用户推荐个性化的项目列表;当收集的用户查询不充分时,最佳的行动通常是要求更多的信息)
how
针对如何解决建立会话式推荐系统的问题,本文的框架有三个组成部分:Belief Tracker、推荐系统和策略网络
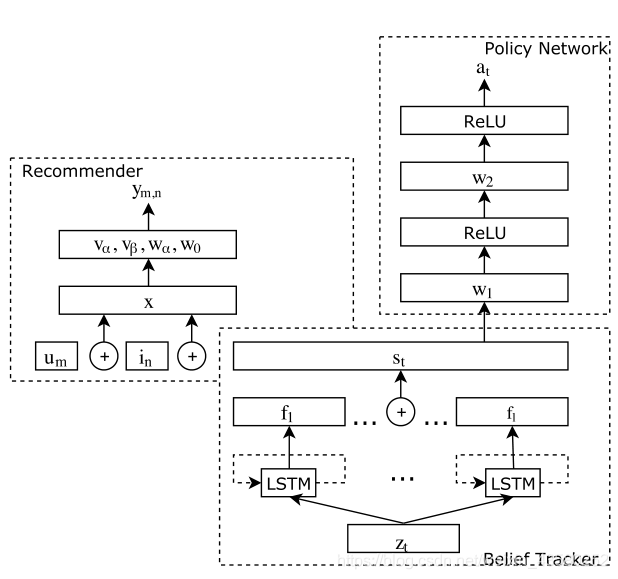
- Belief Tracker
在时间步t的用户话语e(t),Belief Tracker的Input是n-gram向量z(t),z(t)的维数是n-gram词汇的大小
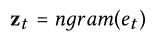
接下来,直到当前时刻t的n-grams序列由LSTM网络编码成向量h(t),然后被送到softmax激活层以被转换成概率分布:
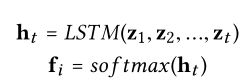
在每一轮中,所有的f相互连接,形成当前会话中对话状态的当前信念
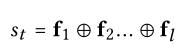
- Recommender System
U表示用户,I表示项目。对于数据集中的M个用户和n个项目,用户和项目表示为集合:{u1,u2,…,uM}和{i1,i2,…,iN}。输入特征x是one-hot编码的用户/项目向量,而dialogue belief是
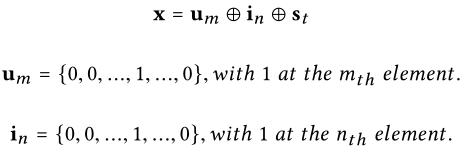
输出ym,n可以是显式反馈的评分,也可以是隐式反馈的0-1标量。本文使用双向(K = 2)调频:
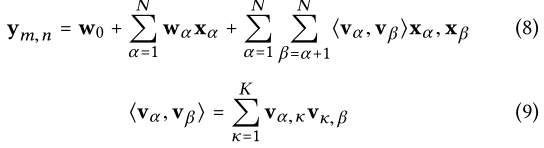
本文首先取每个aspect belief的argmax,每个aspect中取一个,随后这些值组合形成了一个新的分布,概率是l值概率的乘积。然后我们保留最可能的组合,并使用它们的方面值从整个项目集中检索项目,检索到的项目形成候选集。然后,本文使用训练好的模型根据候评分对它们进行重新排序 - Deep Policy Network
现在描述用于管理会话系统的深度策略网络。在每个回合,强化学习模型根据对话状态选择一个动作,以获得最大的长期回报。本文采用了强化学习的策略梯度法,可以直接学习一个策略,不需要参考价值函数,强化学习具有状态S、动作A、奖励R和策略π(a|s)的基本成分
Conclusion
本文提出了一个统一的框架,将推荐系统和对话系统技术集成在一起,构建一个智能对话推荐系统。在这个框架下,明确定义了agent动作空间和用户状态。随着会话代理与用户通信并从用户处收集更多信息,agent的状态(即用户信息需求或用户查询的可信度)被表示并不断更新为半结构化数据
agent采取行动并提供信息来优化长期奖励,例如更高的成功率、更短的回合或延迟的奖励,而不是只返回给当前用户查询的最高排名结果的贪婪方法。在推荐系统研究的基础上,本文还引入了会话系统的奖励函数。可以了解在强化学习的每一步,哪个动作可以使基于会话的奖励最大化。它学会根据需要收集face value,并在适当的时候直接提出建议


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









