







 本文介绍了一种基于知识图谱的开放域对话生成模型,通过分层强化学习解决话题选择与连贯性问题。模型通过上层策略平衡对话一致性与用户兴趣,中层策略深化话题,下层策略生成详细对话。实验证明模型在话题连贯性和知识准确性上超越了基线。
本文介绍了一种基于知识图谱的开放域对话生成模型,通过分层强化学习解决话题选择与连贯性问题。模型通过上层策略平衡对话一致性与用户兴趣,中层策略深化话题,下层策略生成详细对话。实验证明模型在话题连贯性和知识准确性上超越了基线。
题目
《Knowledge Graph Grounded Goal Planning for Open-Domain Conversation Generation》
简介
这是一篇AAAI-20的文章,本文面对先前在开放域对话生成中没有有效的机制来管理聊天话题,并且倾向于产生不太连贯的对话这一现象,再加上人人对话策略的启发,本文将多轮开放域对话生成任务分为两个子任务:明确目标(谈论一个话题)序列规划和通过话题阐述完成目标
为了完成该任务,本文提出了一个三层知识感知的基于分层强化学习的模型。具体来说,对于第一个子任务,上层策略学习遍历知识图(KG),以便规划高级目标序列,在对话一致性和与用户兴趣的主题一致性之间实现良好的平衡。对于第二个子任务,中间层策略和较低层策略一起工作,以目标驱动的生成机制产生关于单个主题的深度多轮对话。其中,目标序列规划的能力使聊天机器人能够针对推荐的主题进行主动的开放域对话
why
目前基于Seq2Seq的对话模型产生的回复往往具有一般性或者不太连贯。为了解决这个问题,有的研究引入了外部知识或话题信息提高对话信息量,有的研究还采用强化学习产生连贯和持久的多轮对话,但是这些方案在长时间的对话中,仍然不太连贯,话语之间主题联系不紧密。这是因为没有模块或有效的机制来管理聊天话题,以确保对话的连贯性,因此,聊天话题管理对于生成连贯的对话至关重要
what
要解决这些问题,有两个关键点:
-
如何决定下一个应该谈论的topic?(goal sequence planning)
也就是说如何进行高层次的目标序列规划。这是很困难的,因为聊天机器人既应该保持主题间的连贯性,又应该考虑用户的兴趣来决定目标,以避免“片面”的对话 -
如何深入谈论某个topic? (同时,话题转换的时机应该如何确定呢?)
也就是说如何生成一个关于单个主题的深度多轮对话来完成目标,这对应于主题内的连贯性。目标序列规划的能力使聊天机器人能够针对推荐的主题进行主动的开放域对话
针对以上两个问题,本文设计了KnowHRL模型,它是一个基于分层强化学习的模型,有三个层次策略: upper layer policy/ middle layer policy/ lower layer policy,可以处理两个子任务:目标序列规划和通过主题细化完成目标
-
对于第一个问题,upper layer policy在KG上进行遍历学习,以便规划目标序列。这有一定的难度,因为要考虑对话一致性和用户兴趣一致性之间的平衡。给定来自KG的一个顶点作为当前聊天主题,上层策略学习从当前顶点的所有一跳邻居和用户提到的新主题中选择最佳聊天主题
-
对于第二个问题,对给定的聊天主题进行深入的对话也有一定的难度,尤其是对于低资源的主题。因此,我们分两步进行深入交谈。首先,middle layer policy选择当前目标顶点的一跳邻居作为可聊的主题面。然后,本文使用给定的目标和它的一个可聊的主题面来指导lower layer policy,以便生成多轮深入对话
How
在强化学习模型框架中
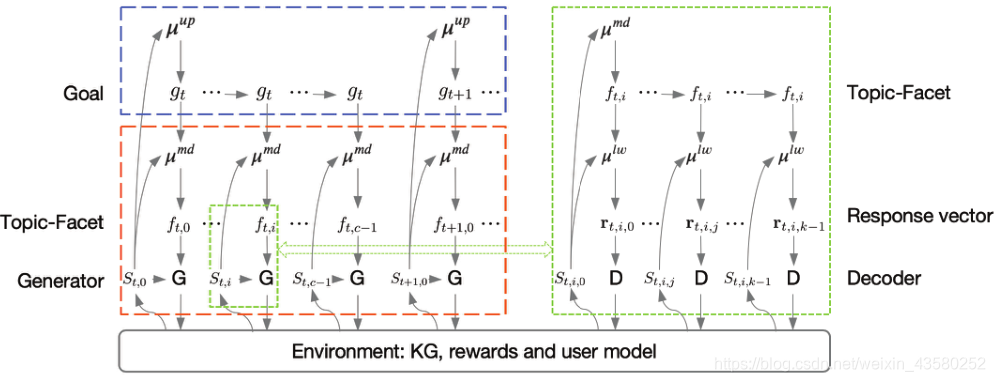
-
state
状态S由目标历史g、主题方面历史f、上下文话语u和一个特殊符号ut组成,该符号表示用户在最后一次话语中是否提到了一个新的主题upper layer,所选择的目标(话题)应该与当前目标(话题)密切相关,以确保对话的话题间连贯性。因此,我们使用当前目标顶点的所有相邻顶点来构成一个动作空间。而且,为了给用户个性化聊天话题,我们还包括了用户提到的所有话题
middle layer,它的动作空间由当前目标顶点的所有相邻顶点组成,除了前面已经讨论过的顶点
lower layer,由于可以选择任意长度的话语,其作用空间是无限的,这对policy学习来说具有一定的难度。为了过滤动作空间,我们使用一组响应向量作为动作,每个向量代表一种典型的方式来响应给定的上下文,例如用疑问句进行响应。具体来说,使用编码到x中的级联主题方面和上下文话语作为输入,多个基于MLP的网络将把它转换成一组响应向量,每个相应向量可以被进一步解码成响应语句
-
Policy
- upper layer
这一层的策略主要用来决定下一个应该谈论的topic, 并且会考虑user-interest,user-interest在这里是指user提到的new topics - middle layer
首先,upper layer policy会向下传递一个goal,middle layer policy从goal周围(本文是基于knowledge graph)选择一个topic,这个topic可以看作是目标topic的深入谈论 - lower layer
lower layer policy则是用于生成回复
- upper layer
-
Reward
-
upper layer
对话话题序列连贯度:TransE[1]空间的平均cosine距离
用户兴趣一致性:用户提及新话题时候,bot应该相应调整
多样性: 在频繁切换对话话题和一直停留在一个对话话题间取得平衡
可持续性:鼓励bot聊内容丰富的节点,使用PageRank打分
来自中层的对话话题完成情况
-
middle layer
可聊内容侧面之间的连贯度
来自下层的奖励情况
-
lower layer
句间相关度
生成语句丰富度
是否完成给定的可聊面
-
Result
-
数据集
论文在百度公司之前发布的DuConv数据集上进行了实验。该数据集包含30k对话Session,其中对话轮数为120k。我们将数据切分为训练集(100k轮对话)、开发集(10k 轮对话)以及测试集(10k轮对话)。该数据还提供了电影、明星领域的知识图谱,由人工进行标注,每个对话Session最终需要引导到一个预先给定的实体,并且对话需要围绕知识图谱中的相应知识进行。
-
基线
论文选取了2个基线模型
① CCM:基于KG对话模型
② CCM+LaRL:对一个基于隐变量以及RL的对话模型(LaRL)进行了改进,使用了CCM中的两个图注意力机制使得LaRL可以充分利用知识图谱 -
评估指标
这里没有采用BLEU等指标,而是设计了多个人工指标。主要原因在于文中工作目标不是选取概率最高的句子做为回复,而是建模回复序列的长期特性,例如对话可持续性、主题的连贯性等。论文中提出了主题间连贯性(Inter-topic Coherence)、主题内连贯性(Intra-topic Coherence)、用户兴趣一致性(User Interest Consistency)、知识准确率(Knowledge accuracy)、独特性(Distinct)等五个人工指标,同时沿用前人的Distinct指标评估回复多样性
-
结果
KnowHRL模型在主题间连贯性、主题内连贯性、用户兴趣一致性、知识准确率等指标下,有非常显著的优势,表明KnowHRL可以生成主题连贯的多轮对话,并且让回复中的知识更加准确。Ablation Study:为了探究模型中对话目标相关Reward因子对模型整体效果的影响,论文还做了模型简化测试(Ablation Study),简化后的模型即KnowHRL-liteReward
KnowHRL-liteReward:为了确认对话目标相关Reward的贡献,论文中实现了一个KnowHRL模型的变体,即将对话目标相关的Reward去掉
不使用对话目标相关的Reward因子后, 模型在主题间连贯性以及用户兴趣一致性等指标下效果显著下降。可以看到,对话目标相关的Reward引入,对模型整体效果的提升比较显著
Conclusion
本文提出了一个基于知识图的基于分层RL的会话模型(KnowHRL),该模型在KG上进行分层目标规划,以促进聊天话题管理和进一步的响应生成
借助于知识图谱,该模型为对话策略(Dialog Policy)学习引入了显示的、可解释的对话状态与动作,不仅便于设计对话目标相关的Reward因子,还可使用对话目标以及细粒度话题指导回复生成
结果表明,KnowHRL在对话一致性、用户兴趣一致性和知识准确性方面优于基线。未来,可提升的点在于如何从开放域对话语料库中丰富KG的内容,以涵盖更多的聊天话题


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









