




 博主分享了在LeetCode上用Python解题的经验,包括两数之和、整数反转、回文数、罗马数字转整数等题目,分析了自己的解法和效率问题,对比了其他解法,并探讨了动态规划、递归等算法思想在解题中的应用。
博主分享了在LeetCode上用Python解题的经验,包括两数之和、整数反转、回文数、罗马数字转整数等题目,分析了自己的解法和效率问题,对比了其他解法,并探讨了动态规划、递归等算法思想在解题中的应用。
num1.两数之和
本题难度不大,但是O(n2n^2n2)的复杂度算超时…
我的解法:
class Solution:
def twoSum(self, nums, target):
length = len(nums)
for i in range(length):
for j in range(i+1,length):
if nums[i] + nums[j] == target:
result = []
result.append(i)
result.append(j)
return(result)
正确解法:
一开始用首尾递进查找做的,需要一次排序,时间复杂度是 O(nlogn),下面是 Python3 代码:
class Solution:
def twoSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
sorted_id = sorted(range(len(nums)), key=lambda k: nums[k]) #key代表排序依据,意为按下标对应的元素大小对元素进行排序,选择使用下标排序的原因是最后输出的是下标而不是数组元素,索引没有直接对元素进行排序
head = 0
tail = len(nums) - 1
sum_result = nums[sorted_id[head]] + nums[sorted_id[tail]]
while sum_result != target:
if sum_result > target: #排好序后当首位之和大于目标,则尾减1缩小范围,同理
tail -= 1
elif sum_result < target:
head += 1
sum_result = nums[sorted_id[head]] + nums[sorted_id[tail]]
return [sorted_id[head], sorted_id[tail]] #最后收尾缩小到了相加等于目标的元素位置
后来看解答发现可以用字典做,时间复杂度是 O(n),还是太年轻:
class Solution:
def twoSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
hashmap = {}
for index, num in enumerate(nums):
another_num = target - num
if another_num in hashmap:
return [hashmap[another_num], index]
hashmap[num] = index
return None
num7.整数反转
这道题主要运用的是字符串、列表、数字之间的转换,体现了python3的方便之处
class Solution:
def reverse(self, x: int) -> int:
if x >= 0:
y = list(map(int, str(x))) # 将整数先转换为字符串,map(function, iterable, ...)结果一般使用list进行接收,最后转换为列表
length = len(y)
result = []
for i in range(length):
result.append(y[length-i-1]) # 这里始终要注意range左闭右开的性质
a = [str(j) for j in result] # 对列表中的元素进行遍历并转换为字符串,用列表存放
b = int("".join(a)) #将这些列表中的无缝连接,再转换成整形
if -2**31 <= b <= 2**31-1:
return b
else:
return 0
return b
else:
x = -x
y = list(map(int, str(x)))
length = len(y)
result = []
for i in range(length):
result.append(y[length-i-1])
a = [str(j) for j in result]
b = int("".join(a))
if -2**31 <= b <= 2**31-1:
return -b
else:
return 0
其他人的答案
class Solution:
def reverse(self, x: int) -> int:
s = str(x)[::-1].rstrip('-') #去除掉符号之后直接反转,::对字符串也可以使用
if int(s) < 2**31:
if x >=0:
return int(s)
else:
return 0-int(s)
return 0
num9.回文数
我的,貌似时间还是很长
class Solution:
def isPalindrome(self, x: int) -> bool:
if x >= 0:
y = list(map(int,str(x)))
count = 0
for i in range(int(len(y)/2)):
if y[i] != y[len(y)-i-1]:
count +=1
if count > 0:
return False
else:
return True
else:
return False
其他人的
class Solution:
def isPalindrome(self, x):
"""
:type x: int
:rtype: bool
"""
if x < 0:
return False
else:
y = str(x)[::-1]
if y == str(x):
return True
else:
return False
num13.罗马数字转整数
用了比较复杂的算法,调试了很久
class Solution:
def romanToInt(self, s: str) -> int:
dict1 = {'I' : 1,'V' : 2, 'X' : 3, 'L' : 4, 'C' : 5, 'D' : 6, 'M' : 7}
dict2 = {'I' : 1, 'V' : 5, 'X' : 10, 'L': 50, 'C' : 100, 'D' : 500, 'M' : 1000}
s1 = list(s)
s2 = []
for i in range(len(s1)):
s2.append(dict1[s1[i]])
if len(set(s2)) == 1:
sum = 0
for j in s1:
sum = sum + dict2[j]
else:
if s2 == sorted(s2, reverse = True): # 符合倒序
sum = 0
for j in s1:
sum = sum + dict2[j]
else:
sum = 0
j = 0
while(j < len(s2)-1):
if s2[j] < s2[j+1]:
sum = sum + dict2[s1[j+1]] - dict2[s1[j]]
j = j + 2
else:
sum = sum + dict2[s1[j]]
j = j + 1
if s2[len(s2)-2] >= s2[len(s2)-1]:
sum = sum + dict2[s1[len(s2)-1]]
return sum
别人的
class Solution:
def romanToInt(self, s: str) -> int:
d = {'I':1, 'IV':3, 'V':5, 'IX':8, 'X':10, 'XL':30, 'L':50, 'XC':80, 'C':100, 'CD':300, 'D':500, 'CM':800, 'M':1000}
return sum(d.get(s[max(i-1, 0):i+1], d[n]) for i, n in enumerate(s))
代码行数:解析
构建一个字典记录所有罗马数字子串,注意长度为2的子串记录的值是(实际值 - 子串内左边罗马数字代表的数值)
这样一来,遍历整个 ss 的时候判断当前位置和前一个位置的两个字符组成的字符串是否在字典内,如果在就记录值,不在就说明当前位置不存在小数字在前面的情况,直接记录当前位置字符对应值
链接:https://leetcode-cn.com/problems/roman-to-integer/solution/2-xing-python-on-by-knifezhu/
num14.最长公共全缀
复杂的笨办法还易错
值得注意的是这里运用了break和break_flag来退出双层循环!
import math
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
temp = []
for i in range(len(strs)):
temp.append(len(list(strs[i])))
if temp != []:
length = min(temp)
else:
length = 0
if len(strs) == 1:
return strs[0]
count = 0
break_flag = False
for j in range(length):
if break_flag == False:
num = 0
for i in range(1,len(strs)):
if list(strs[i])[j] == list(strs[0])[j]:
num = num + 1
else:
break_flag = True
break
if num == len(strs)-1:
count = count + 1
else:
break
result = []
for i in range(math.floor(count)):
result.append(list(strs[0])[i])
result = "".join(result)
return result
别人的解答,使用emumerate函数和zip函数
def longestCommonPrefix(self, strs):
if not strs: return "" # 排除特殊情况
s1 = min(strs) #字符串确实是可以比较大小的,按照的是ASCII码的大小;这里排序后的两个字符串理论上是能不一样就开始不一样了!
s2 = max(strs)
for i,x in enumerate(s1): # 这个函数很常见,要多运用!enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
if x != s2[i]:
return s2[:i]
return s1
def longestCommonPrefix(self, strs):
if not strs: return ""
ss = list(map(set, zip(*strs))) # zip函数起到了将每个字符串的对应位置放到一个元组的效果,然后用map和set去掉重复元素,当长度为1是说明全部相同,当长度大于1时说明至少有一个与其他不同
res = ""
for i, x in enumerate(ss):
x = list(x)
if len(x) > 1:
break
res = res + x[0]
return res
num20.有效的括号
思路方面是对的:将一对一对去掉,剩下的就是最后的,但是再一次写的很复杂
class Solution:
def isValid(self, s: str) -> bool:
s1 = list(s)
if len(s1)%2 != 0:
return False
else:
dict1 = {'(' : 1 , ')' : -1 , '[' : 2, ']' : -2, '{' : 3 , '}' : -3}
s2 = []
for i in s1:
s2.append(dict1[i])
i = 0
while(i <= len(s1)/2):
j = 0
length = len(s2)
if length == 0:
return True
while (j <= len(s2)/2-1):
if s2[j] + s2[j+1] == 0:
del s2[j]
del s2[j]
j = j + 1
else:
j = j + 1
if len(s2) == length:
return False
else:
i = i + 1
别人的,总体思路是一样的,但是自己的思维总是被局限在了循环中必须要维护一个数字i的概念上。如果直接把这种存在条件当做循环条件的话,就省去了巨大的维护+判断的时间成本。
class Solution:
def isValid(self, s):
while '{}' in s or '()' in s or '[]' in s:
s = s.replace('{}', '')
s = s.replace('[]', '')
s = s.replace('()', '')
return s == ''
num26.删除数组中重复项
我的:经测试算法正确,但是运算超时,因为又是嵌套循环…
另外要注意,最容易出错的就是特殊情况的判断,一定要单列出来
维护两个数组,一个是每次加一取值的数组,一个是始终指向不重复的第一个
对于每一个j做了一个循环,当相等则i+1,主动判断j的情况比对j做循环其实更简单方便
class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
if len(nums) == 0 or len(nums) == 1 or len(nums) == len(set(nums)):
return len(nums)
else :
j = 0
i = 0
while(j < len(set(nums))):
while(i < len(nums)-2):
if nums[i+1] == nums[j]:
i = i + 1
else:
break
nums[j+1] = nums[i+1]
j = j + 1
return len(set(nums))
别人的,区别是判断不相等更容易,判断一次不相等则j加1,相等则i加1
class Solution(object):
def removeDuplicates(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
length=len(nums)
count=0
for i in range(1,length):
if nums[count]!=nums[i]:
nums[count+1]=nums[i]
count+=1
return count+1
num.27 移除元素
我的答案,思路正确但没有使用更方便的函数,注意维护两个数组这种思想用处很大,另外发现有时候while等于for+if的功能
class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
if len(nums) == 0:
return 0
elif len(nums) == 1:
if nums == [val]:
return 0
else:
return 1
else:
count = 0
i = 0
while(i + count <= len(nums)-1):
if nums[i] == val:
del nums[i]
nums.append(val)
count = count + 1
else:
i = i + 1
return len(nums) -count
别人的答案
pop函数移除了某个元素后,会将后面的元素整体向前移动,当使用前序遍历的时候,我们需要维护两个数组保证能够不出现错误,但是使用后向遍历就不会出现这个问题,即移除的方向要和i前进的方向不同才行
j=len(nums)
for i in range(j-1,-1,-1):
if nums[i]==val:
nums.pop(i)
return len(nums)
class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
while val in nums:
nums.remove(val)
return len(nums)
使用del删除指定位置元素
del是python语句,而不是列表方法,无法通过list来调用。使用del可以删除一个元素,当元素删除之后,位于它后面的元素会自动移动填补空出来的位置。
使用remove()删除指定值
如果不确定或不关心元素在列表中的位置,可以使用remove()根据指定的值来删除元素。
使用pop()获取并删除指定位置元素
使用pop()同样可以获取列表中指定位置的元素,但在获取完成之后,该元素会自动被删除。如果为pop(off)指定了偏移量,它会返回偏移量对应位置的元素。如果不指定,则默认使用-1。因此pop(0)将返回头元素,而pop()或pop(-1)则会返回列表的尾元素。
综上所述,这种情况下不用对索引进行维护的remove显然更加方便
num28.实现Strstr()
不使用快捷的内置函数和kmp算法的情况下,代码如下,没什么难度
class Solution:
def strStr(self, haystack: str, needle: str) -> int:
# 第一种方法可以采取类似n-gram的方法,但是显然分词这里就要很大的复杂度
# 第二种直接找
if len(needle) == 0:
return 0
if len(haystack) < len(needle):
return -1
if needle == haystack:
return 0
else:
i = 0
while(i <= len(haystack)-len(needle)):
if haystack[i: i+len(needle)] == needle:
return i
else:
i = i + 1
if i == len(haystack)-len(needle)+1:
return -1
使用内置函数index直接返回索引(学过是学过,但是不熟导致不会用)
class Solution:
def strStr(self, haystack: str, needle: str) -> int:
if needle and not haystack: return -1
if needle in haystack:
return haystack.index(needle)
else:
return -1
num35.搜索插入位置
遍历法
class Solution:
def searchInsert(self, nums: List[int], target: int) -> int:
if nums == []:
return 0
else:
try:
return nums.index(target)
except:
i = 0
j = len(nums) - 1
if nums[0] > target:
return 0
elif nums[len(nums)-1] < target:
return len(nums)
else:
i = 0
while(nums[i] < target):
i = i + 1
return i
二分法:重点理解为什么候选区间的索引范围是 [0, size]。最易错的就是左右边界问题。
from typing import List
class Solution:
def searchInsert(self, nums: List[int], target: int) -> int:
# 返回大于等于 target 的索引,有可能是最后一个
size = len(nums)
# 特判
if size == 0:
return 0
left = 0
# 如果 target 比 nums里所有的数都大,则最后一个数的索引 + 1 就是候选值,因此,右边界应该是数组的长度
right = size
# 二分的逻辑一定要写对,否则会出现死循环或者数组下标越界
while left < right:
mid = left + (right - left) // 2 # "/"就表示 浮点数除法,返回浮点结果;" // "表示整数除法,返回不大于结果的一个最大的整数,当对数组的奇偶不确定的时候,使用//很好
if nums[mid] < target:
left = mid + 1 #
else:
assert nums[mid] >= target # 检查条件,不符合就终止程序
# [1,5,7] 2
right = mid
# 调试语句
# print('left = {}, right = {}, mid = {}'.format(left, right, mid))
return left
num38.报数
第一遍阅读的时候审错题了,一以为报数时要统计每个的出现次数,但题意是一个一个报的,递归程序终于调试成功,里面关于全局变量控制递归次数、字符串、列表、字典转换,匿名函数的使用还是有一定参考价值的
n=4
count = 0
from collections import Counter
def baoshu(aa):
global count
count = count + 1
aa = list(str(aa))
sort_aa = sorted(Counter(aa).items(), key = lambda x:x[0], reverse = True)
key = []
for i in sort_aa:
key.append(int(i[0]))
value = []
for i in sort_aa:
value.append(int(i[1]))
bb = []
for i in range(len(key)):
bb.append(str(value[i]))
bb.append(str(key[i]))
aa = int(''.join(bb))
if count == n-1:
return aa
else:
return baoshu(aa)
这是使用递归函数后正确解法,但是由于力扣好像不能识别嵌套函数,所以目前没有再力扣下运行成功
count = 0
n = 4
def baoshu(aa):
aa = list(str(aa))
global count
count = count + 1
i = 0
result = []
while(i < len(aa)-1):
j = 1
while( aa[i] == aa[i + j]):
j= j + 1
if i + j >= len(aa):
break
result.append(str(j))
result.append(str(aa[i]))
i = i + j
if aa[len(aa)-2] != aa[len(aa)-1]:
result.append(str(1))
result.append(str(aa[len(aa)-1]))
aa = int(''.join(result))
if count == n - 1:
return aa
else:
return baoshu(aa)
别人的,暂时没看懂
class Solution:
def countAndSay(self, n: int) -> str:
if(n == 1): return '1'
num = self.countAndSay(n-1)+"*"
print(num)
temp = list(num)
count = 1
strBulider = ''
# print(len(temp))
for i in range(len(temp)-1):
if temp[i] == temp[i+1] :
count += 1
else:
if temp[i] != temp[i+1]:
strBulider += str(count) + temp[i]
count = 1
return strBulider
num53.最大子序和
这题明显用笨办法太耗时了,不可能用笨办法解决
别人的:思想是动态规划,nums[i-1]并不是数组前一项的意思,而是到前一项为止的最大子序和,和0比较是因为只要大于0,就可以相加构造最大子序和。如果小于0则相加为0,nums[i]=nums[i],相当于最大子序和又重新计算。其实是一边遍历一边计算最大序和
class Solution(object):
def maxSubArray(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
for i in range(1, len(nums)):
nums[i]= nums[i] + max(nums[i-1], 0)
return max(nums)
思路和上题类似
class Solution(object):
def maxSubArray(self, nums):
sum = 0
max_sub_sum = nums[0]
for num in nums:
sum += num
if sum > max_sub_sum:
max_sub_sum = sum
if sum < 0:
sum = 0
return max_sub_sum
分治法:
定义基本情况。
将问题分解为子问题并递归地解决它们。
合并子问题的解以获得原始问题的解。
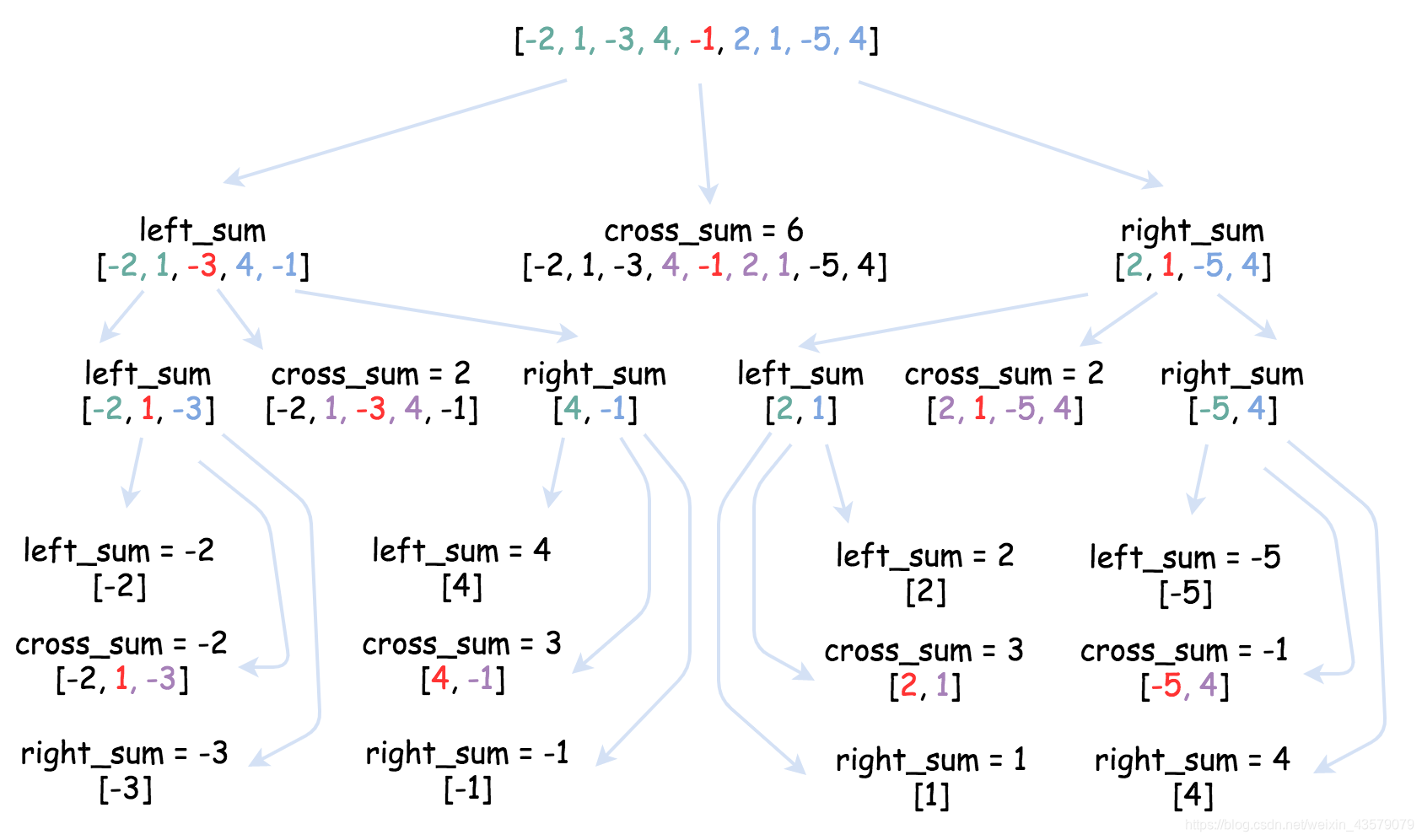
不是很能看懂…
class Solution:
def cross_sum(self, nums, left, right, p):
if left == right:
return nums[left]
left_subsum = float('-inf')
curr_sum = 0
for i in range(p, left - 1, -1):
curr_sum += nums[i]
left_subsum = max(left_subsum, curr_sum)
right_subsum = float('-inf')
curr_sum = 0
for i in range(p + 1, right + 1):
curr_sum += nums[i]
right_subsum = max(right_subsum, curr_sum)
return left_subsum + right_subsum
def helper(self, nums, left, right):
if left == right:
return nums[left]
p = (left + right) // 2
left_sum = self.helper(nums, left, p)
right_sum = self.helper(nums, p + 1, right)
cross_sum = self.cross_sum(nums, left, right, p)
return max(left_sum, right_sum, cross_sum)
def maxSubArray(self, nums: 'List[int]') -> 'int':
return self.helper(nums, 0, len(nums) - 1)
num58.最后一个单词的长度
本题难度不大,麻烦的主要是特殊情况。另外用倒序可以有效减少运算量。
class Solution:
def lengthOfLastWord(self, s: str) -> int:
try:
a = list(s)[::-1]
while( a.index(' ') == 0):
del a[0]
return a.index(' ')
except:
return len(a)
别人的
class Solution:
def lengthOfLastWord(self, s: str) -> int:
s = s.strip(' ') #strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
L = s.split(' ')[-1] # 返回的是一个列表类型,通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串。另外取最后一个的时候索引直接用-1就可以了,不用len(nums)-1.
return len(L)
num66.加一
复杂的方法。基本程序错误的时候都是没有考虑到可能出现的特殊情况,这里使用负索引更加方便
class Solution:
def plusOne(self, digits: List[int]) -> List[int]:
count = 0
a = [1]
if set(digits) == {9}:
for i in range(len(digits)):
a.append(0)
return a
else:
while( digits[-1-count] == 9):
count = count + 1
if count > 0:
digits[-1-count] = digits[-1-count] + 1
for i in range(count):
digits[-1-i] = 0
else:
digits[-1-count] = digits[-1-count] + 1
return digits
别人的
class Solution(object):
def plusOne(self, digits):
"""
:type digits: List[int]
:rtype: List[int]
"""
num = ''.join(str(s) for s in digits) #将列表中数组转换为整形的方法(先转换成字符串再用join进行连接,用处很大)
new = int(num)+1
return list(str(new))
num67. 二进制求和
没有用内置函数,用算法实现二进制到十进制再到二进制的
class Solution:
def addBinary(self, a: str, b: str) -> str:
a1 = []
for i in a:
a1.append(i)
sum1 = 0
for i in range(len(a1)):
sum1 = sum1 + 2**i*int(a1[-1-i])
b1 = []
for i in b:
b1.append(i)
sum2 = 0
for i in range(len(b1)):
sum2 = sum2 + 2**i*int(b1[-1-i])
sum3 = sum1 + sum2
c1 = []
while (sum3 != 0 and sum3 != 1):
c1.append(sum3%2)
sum3 = sum3//2
c1.append(sum3)
return str(''.join(str(i) for i in c1[::-1]))
使用内置函数 int和bin就能实现
return bin(int(a,2)+int(b,2))[2:]

















 1429
1429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









