




首先是关于给了提示然后做分割的一些方法的总结:
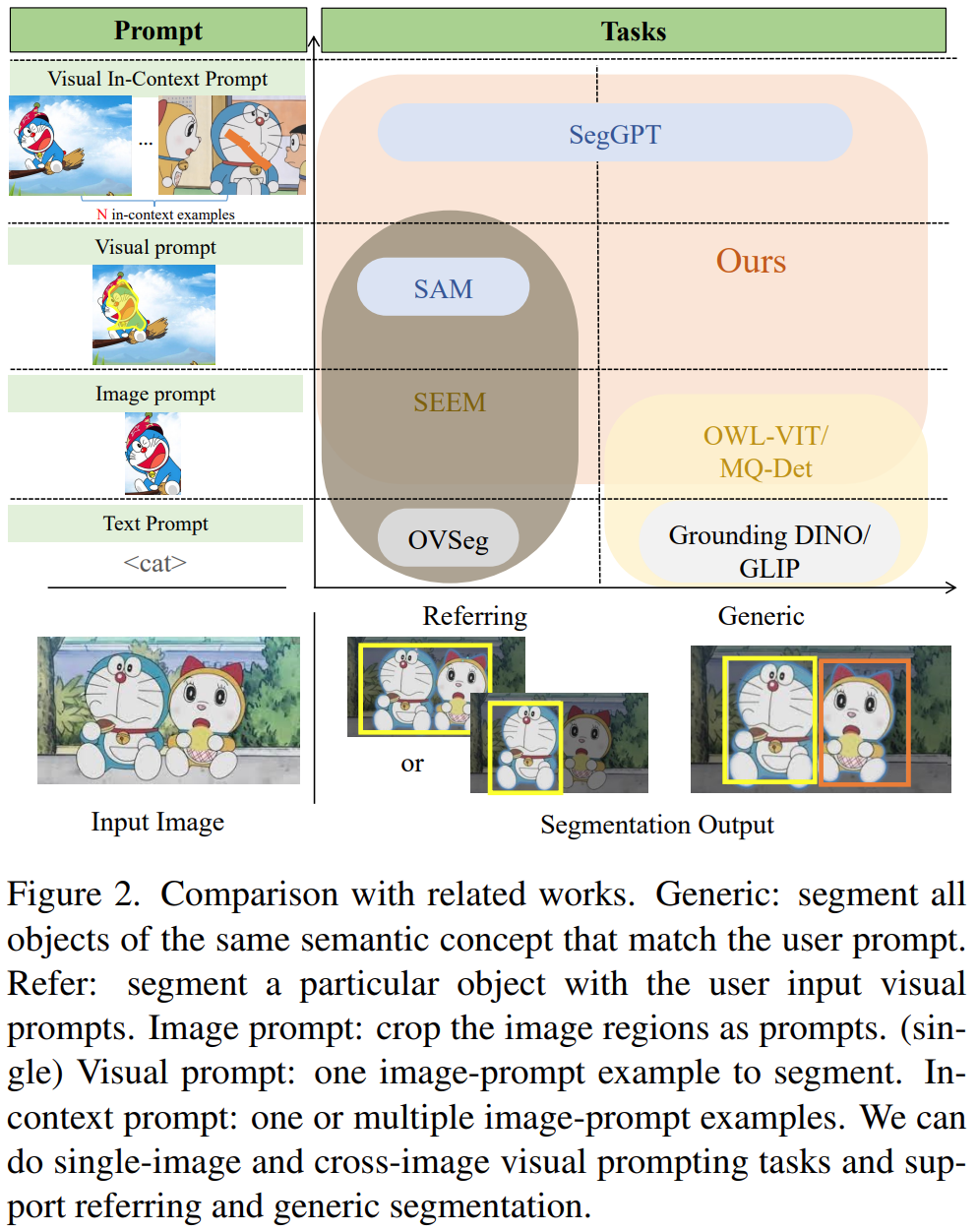
左边一列是prompt类型,右边一列是使用各个类型的prompt的模型。这些模型有分为两大类:Generic和Refer,通用分割和参考分割。Generic seg 是分割和提示语义概念一样的所有的物体,也就是提示是狮子,就把图片中所有狮子分割出来;Refer seg 是根据用户提示分割特定的物体,也就是提示是狗狗的一只耳朵,分割出来的也是狗狗的耳朵。可以看到,本文DINOv填补了视觉提示(Visual prompt)方法的空白。
DINOv可以做Generic和Refer。
Generic和Refer的例子:
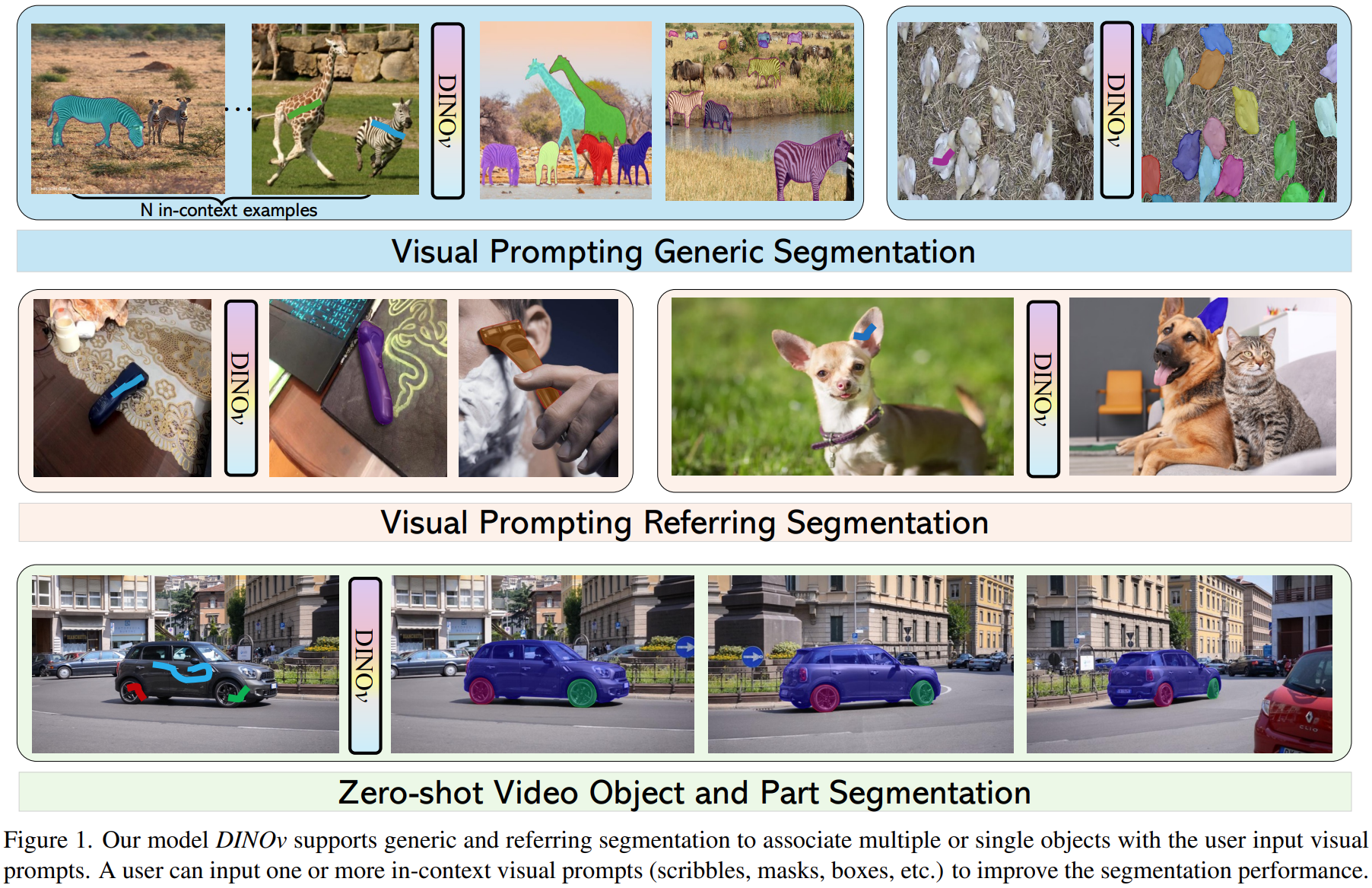
这篇文章不是简单的prompt,而是in-context learning.
输入是一组图片-提示对(a set of reference image (Q) - visual prompt (A) pairs)输入的提示可以是mask、涂鸦(scribble)、框等,输出目标图片的mask。
DINOv的框架:
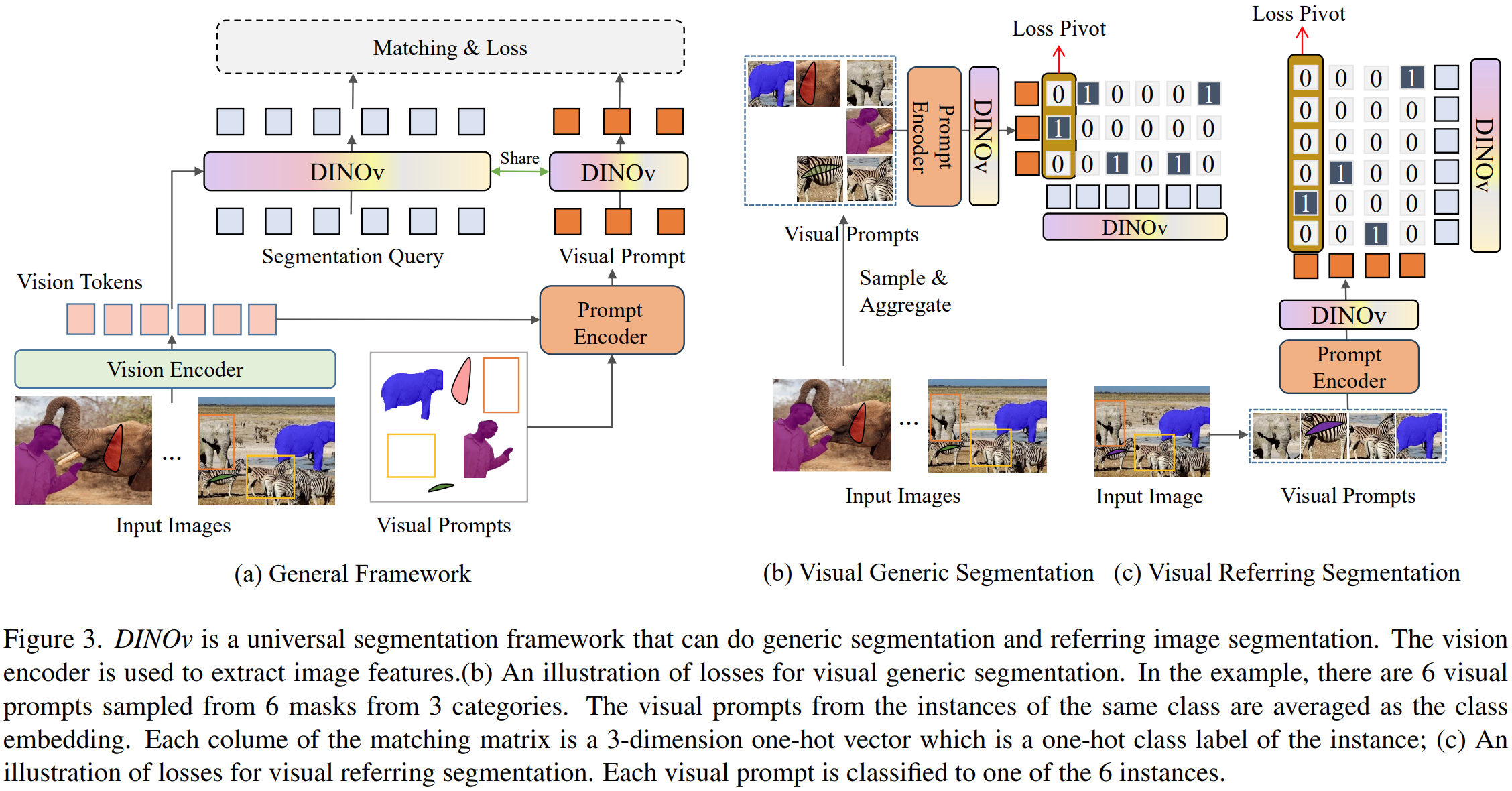
给一些参考图片:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2479
2479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









